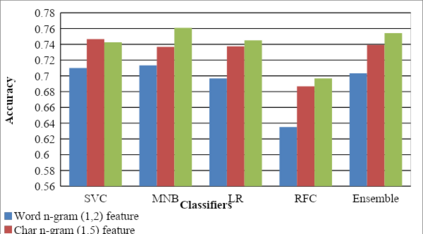
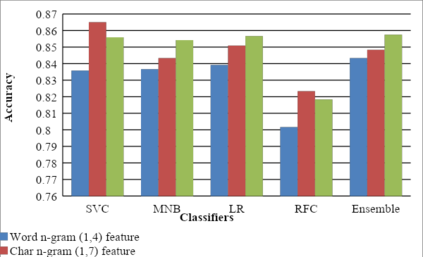
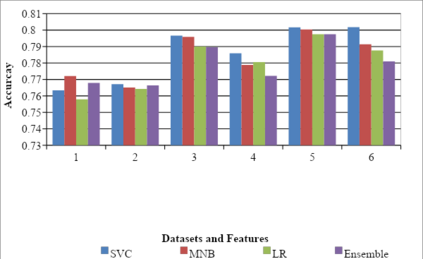
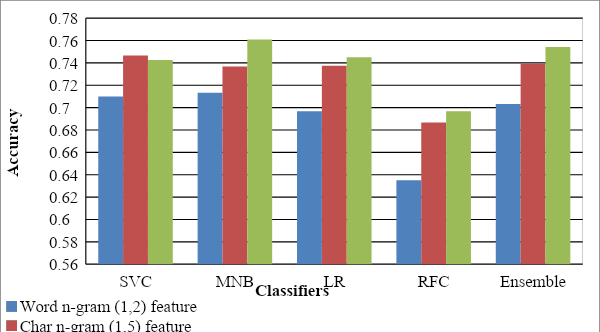
This paper describes the system submitted by our team, KBCNMUJAL, for Task 2 of the shared task Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC), at Forum for Information Retrieval Evaluation, December 16-20, 2020, Hyderabad, India. The datasets of two Dravidian languages Viz. Malayalam and Tamil of size 4000 observations, each were shared by the HASOC organizers. These datasets are used to train the machine using different machine learning algorithms, based on classification and regression models. The datasets consist of tweets or YouTube comments with two class labels offensive and not offensive. The machine is trained to classify such social media messages in these two categories. Appropriate n-gram feature sets are extracted to learn the specific characteristics of the Hate Speech text messages. These feature models are based on TFIDF weights of n-gram. The referred work and respective experiments show that the features such as word, character and combined model of word and character n-grams could be used to identify the term patterns of offensive text contents. As a part of the HASOC shared task, the test data sets are made available by the HASOC track organizers. The best performing classification models developed for both languages are applied on test datasets. The model which gives the highest accuracy result on training dataset for Malayalam language was experimented to predict the categories of respective test data. This system has obtained an F1 score of 0.77. Similarly the best performing model for Tamil language has obtained an F1 score of 0.87. This work has received 2nd and 3rd rank in this shared Task 2 for Malayalam and Tamil language respectively. The proposed system is named HASOC_kbcnmujal.
翻译:本文描述了由我们的团队KBCNMUJAL提交的系统,即我们团队KBCNMUJAL在信息检索评价论坛(信息检索评价论坛,2020年12月16日至20日,印度海得拉巴,印度海得拉巴)上提交的仇恨言语和攻击性内容识别共同任务任务任务2的任务2。两种Dravidian语言的数据集Viz、Malayalam和泰米尔大小4000的观测由HASOC组织者共享。这些数据集用于使用基于分类和回归模型的不同机器学习算法对机器进行培训。数据集包括Twitter或YouTube评论,其中两个类标签是攻击性的,而不是攻击性的。该机器经过训练,可以将这类社交媒体信息信息信息分为两类。适当的 ngram 数据集将学习仇恨言论短信的具体特性。这些功能模型以N-gram的TFIDF重量为基础。上述工作和相关实验显示,可以使用词、性质和性格的模型模型等特征来确定攻击性文字内容的术语模式。作为HASOC共享任务的一部分,用于进行该类的模型共享任务,测试数据系统,用于进行该测试。