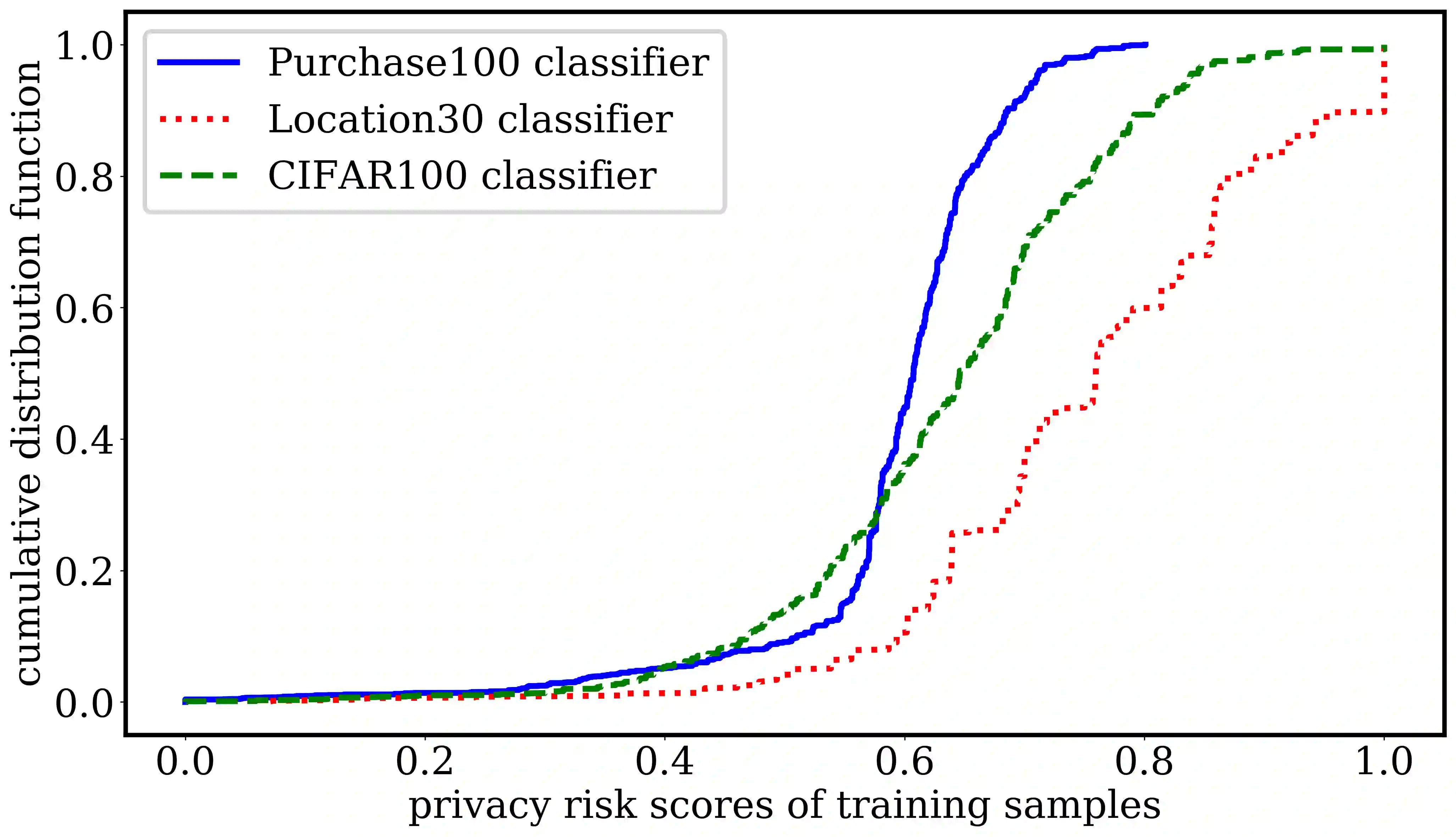
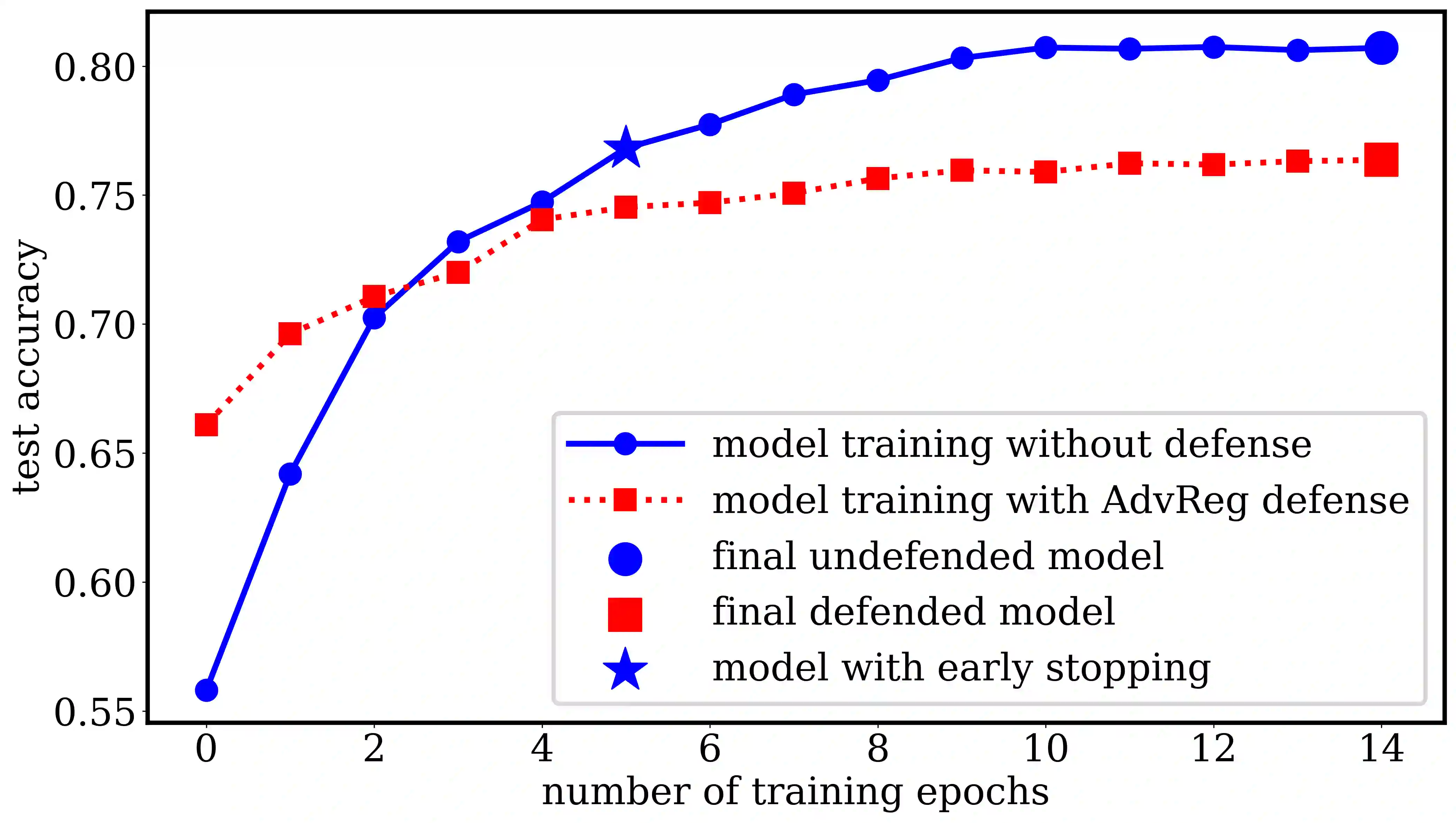
Machine learning models are prone to memorizing sensitive data, making them vulnerable to membership inference attacks in which an adversary aims to guess if an input sample was used to train the model. In this paper, we show that prior work on membership inference attacks may severely underestimate the privacy risks by relying solely on training custom neural network classifiers to perform attacks and focusing only on the aggregate results over data samples, such as the attack accuracy. To overcome these limitations, we first propose to benchmark membership inference privacy risks by improving existing non-neural network based inference attacks and proposing a new inference attack method based on a modification of prediction entropy. We also propose benchmarks for defense mechanisms by accounting for adaptive adversaries with knowledge of the defense and also accounting for the trade-off between model accuracy and privacy risks. Using our benchmark attacks, we demonstrate that existing defense approaches are not as effective as previously reported. Next, we introduce a new approach for fine-grained privacy analysis by formulating and deriving a new metric called the privacy risk score. Our privacy risk score metric measures an individual sample's likelihood of being a training member, which allows an adversary to identify samples with high privacy risks and perform attacks with high confidence. We experimentally validate the effectiveness of the privacy risk score and demonstrate that the distribution of privacy risk score across individual samples is heterogeneous. Finally, we perform an in-depth investigation for understanding why certain samples have high privacy risks, including correlations with model sensitivity, generalization error, and feature embeddings. Our work emphasizes the importance of a systematic and rigorous evaluation of privacy risks of machine learning models.
翻译:机器学习模式容易被误读敏感数据,使其容易受到会籍推断攻击的伤害,在这种攻击中,对手的目的是猜测是否使用了输入样本来训练模型。在本文中,我们表明,先前关于会籍推断攻击的工作可能严重低估隐私风险,因为仅仅依靠培训定制神经网络分类人员来进行攻击,而仅侧重于数据样本的总体结果,例如攻击准确性。为了克服这些限制,我们首先提议通过改进基于推断攻击的现有非神经网络的敏感度攻击,并通过修改预测重要性提出一种新的推断攻击方法,来衡量会员隐私风险。我们还提出国防机制的基准,方法是对具备防御知识的适应性对手进行会计核算,同时对模型准确性和隐私风险进行会计核算。我们利用基准攻击,表明现有的防御方法不像以前所报告的那样有效。为了克服这些限制,我们首先提出一个新的方法,即通过制定和得出称为隐私风险评级的新标准,我们隐私风险评级衡量个人样本评估作为培训成员的可能性,我们最终能够对隐私风险进行对比,我们用高精确度的样本进行测试,我们用高隐私风险评级来评估。