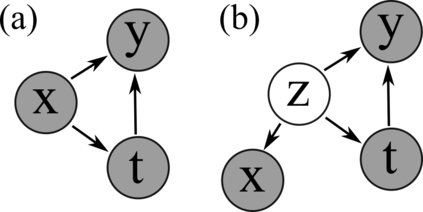
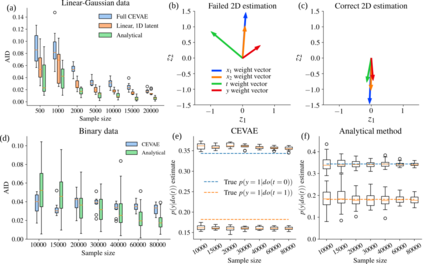
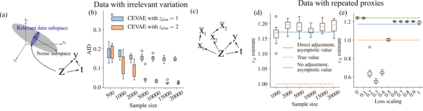
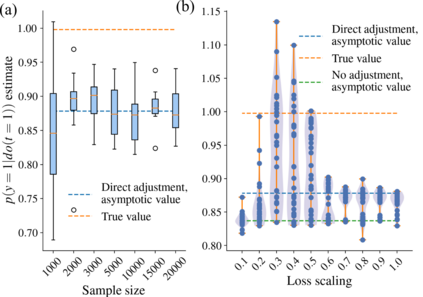
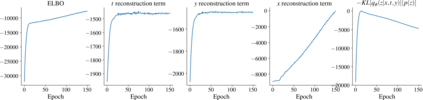
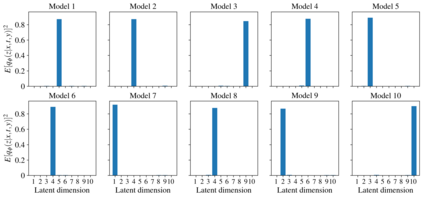
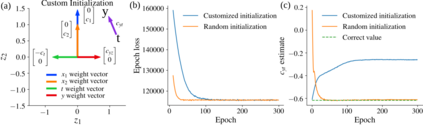
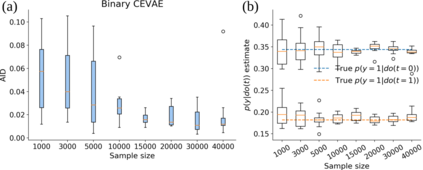
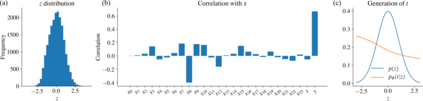
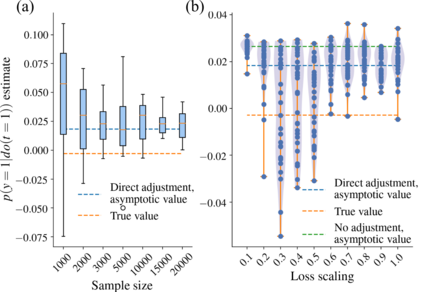
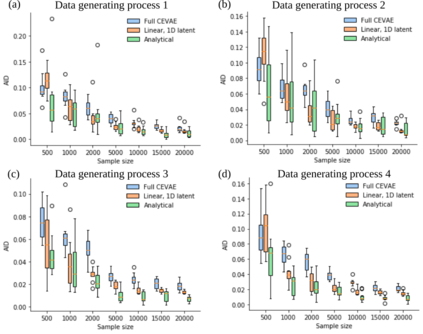
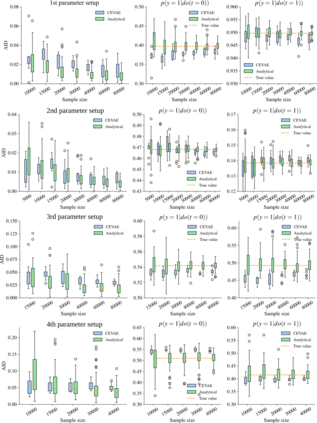
Using deep latent variable models in causal inference has attracted considerable interest recently, but an essential open question is their identifiability. While they have yielded promising results and theory exists on the identifiability of some simple model formulations, we also know that causal effects cannot be identified in general with latent variables. We investigate this gap between theory and empirical results with theoretical considerations and extensive experiments under multiple synthetic and real-world data sets, using the causal effect variational autoencoder (CEVAE) as a case study. While CEVAE seems to work reliably under some simple scenarios, it does not identify the correct causal effect with a misspecified latent variable or a complex data distribution, as opposed to the original goals of the model. Our results show that the question of identifiability cannot be disregarded, and we argue that more attention should be paid to it in future work.
翻译:在因果关系推断中使用深潜变量模型最近引起了相当大的兴趣,但一个基本的未决问题是其可识别性。虽然这些模型已经产生了有希望的结果,而且在某些简单模型配方的可识别性方面存在着理论,但我们也知道,总体而言无法确定潜在变量的因果关系。 我们用多种合成和现实世界数据集的理论考虑和广泛实验,用因果变异自动编码器(CEVAE)作为案例研究,来调查理论和经验结果之间的这一差距。 虽然CEVAE似乎在某些简单假设下可以可靠地工作,但是它并没有确定正确的因果效果,与模型的原始目标相反,而错误地指明了潜在的变量或复杂的数据分布。 我们的结果显示,不可忽视身份可识别性问题,我们主张在未来的工作中应更多地关注这一问题。