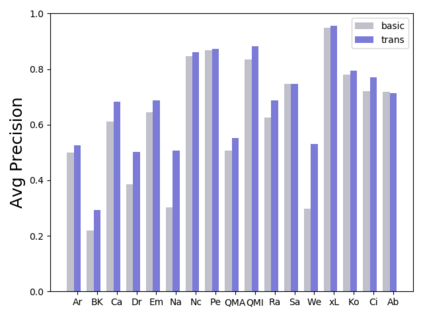
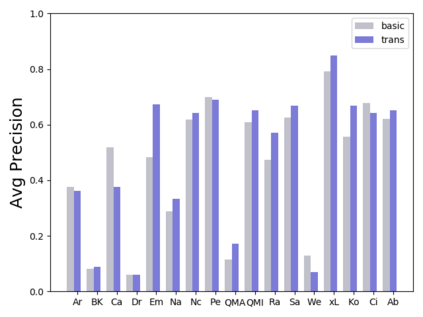
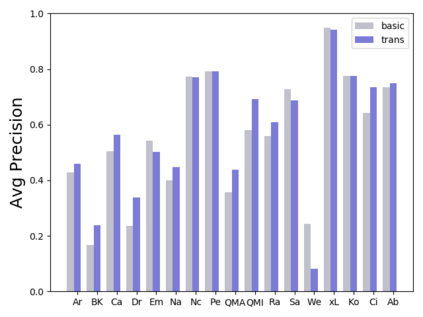
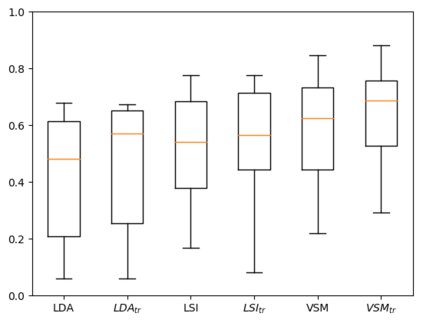
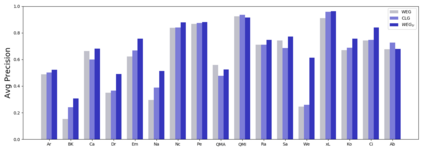
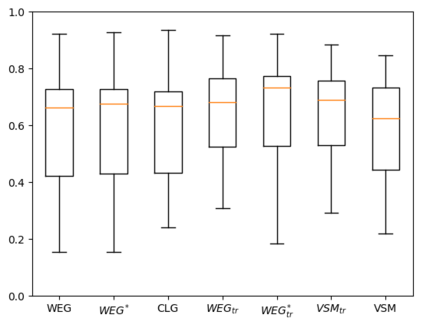
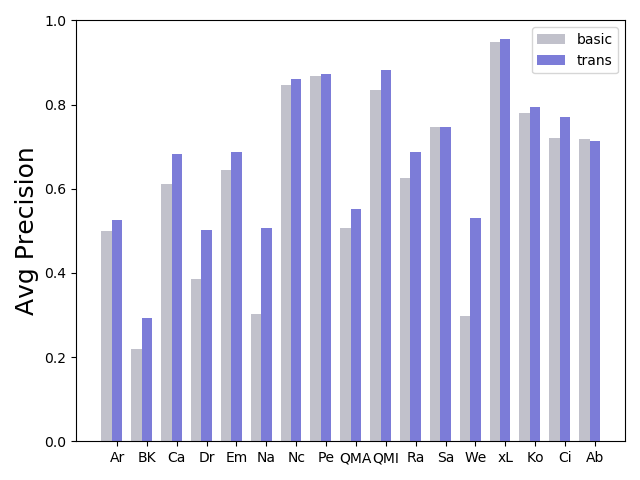
Software traceability establishes associations between diverse software artifacts such as requirements, design, code, and test cases. Due to the non-trivial costs of manually creating and maintaining links, many researchers have proposed automated approaches based on information retrieval techniques. However, many globally distributed software projects produce software artifacts written in two or more languages. The use of intermingled languages reduces the efficacy of automated tracing solutions. In this paper, we first analyze and discuss patterns of intermingled language use across multiple projects, and then evaluate several different tracing algorithms including the Vector Space Model (VSM), Latent Semantic Indexing (LSI), Latent Dirichlet Allocation (LDA), and various models that combine mono- and cross-lingual word embeddings with the Generative Vector Space Model (GVSM). Based on an analysis of 14 Chinese-English projects, our results show that best performance is achieved using mono-lingual word embeddings integrated into GVSM with machine translation as a preprocessing step.
翻译:由于人工创建和维护链接的非三重成本,许多研究人员提出了基于信息检索技术的自动化方法。然而,许多全球分布的软件项目生成了两种或多种语言的软件文物。使用混合语言降低了自动追踪解决方案的功效。在本文件中,我们首先分析和讨论多个项目混合使用语言的模式,然后评价若干不同的追踪算法,包括矢量空间模型、迟发语语语索引、利通狄里赫莱分配(LDA)以及将单词和跨语言词嵌入基因矢量空间模型(GVSM)的各种模型。根据对14个中英项目的分析,我们的结果显示,最佳的成绩是通过将单语词嵌入GVSM和机器翻译作为预处理步骤实现。