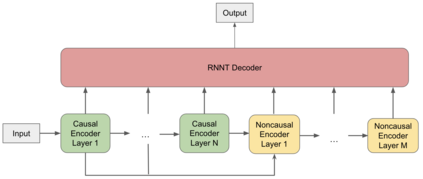
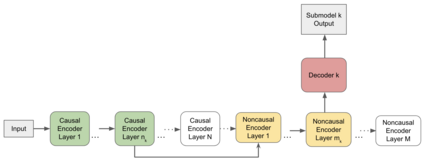
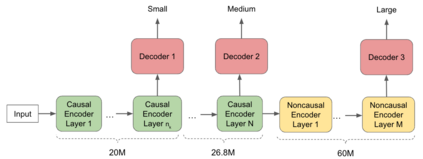
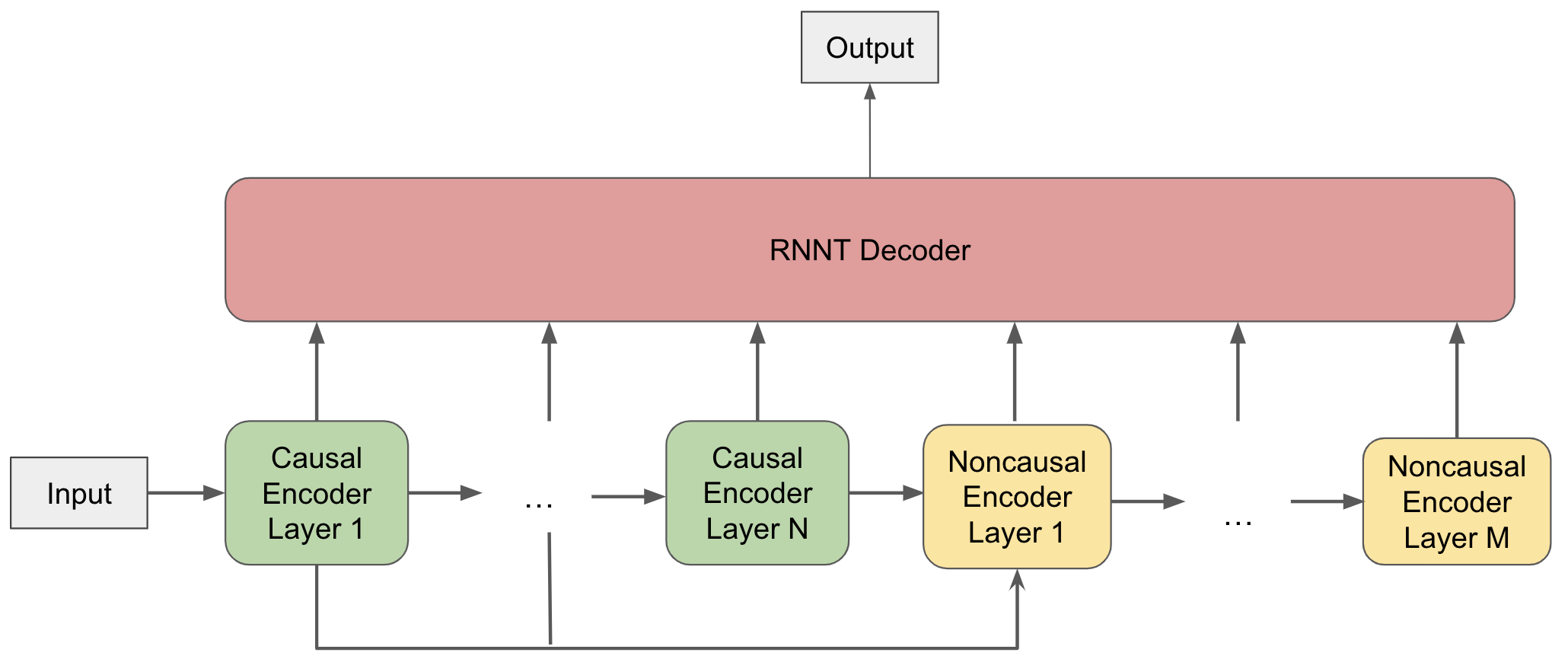
In this paper, we propose a dynamic cascaded encoder Automatic Speech Recognition (ASR) model, which unifies models for different deployment scenarios. Moreover, the model can significantly reduce model size and power consumption without loss of quality. Namely, with the dynamic cascaded encoder model, we explore three techniques to maximally boost the performance of each model size: 1) Use separate decoders for each sub-model while sharing the encoders; 2) Use funnel-pooling to improve the encoder efficiency; 3) Balance the size of causal and non-causal encoders to improve quality and fit deployment constraints. Overall, the proposed large-medium model has 30% smaller size and reduces power consumption by 33%, compared to the baseline cascaded encoder model. The triple-size model that unifies the large, medium, and small models achieves 37% total size reduction with minimal quality loss, while substantially reducing the engineering efforts of having separate models.
翻译:在本文中,我们提出了一个动态级联编码器自动语音识别(ASR)模型,该模型统一了不同部署情景的模型。此外,该模型可以大幅降低模型规模和动力消耗,而不会降低质量。 也就是说,随着动态级联编码器模型,我们探索了三种技术,以最大限度地提高每个模型的性能:1)在共享编码器的同时,对每个子模型分别使用解码器;2)使用漏斗集合来提高编码器的效率;3)平衡因果和非因果编码器的规模,以提高质量和适合部署制约。总的来说,拟议的大中型模型比基线级联动编码器模型缩小了30%的规模,将电力消耗减少了33%。将大型、中型和小型模型统一起来的三重模型在质量损失最小的情况下实现了37%的总规模削减,同时大大减少了拥有不同模型的工程努力。