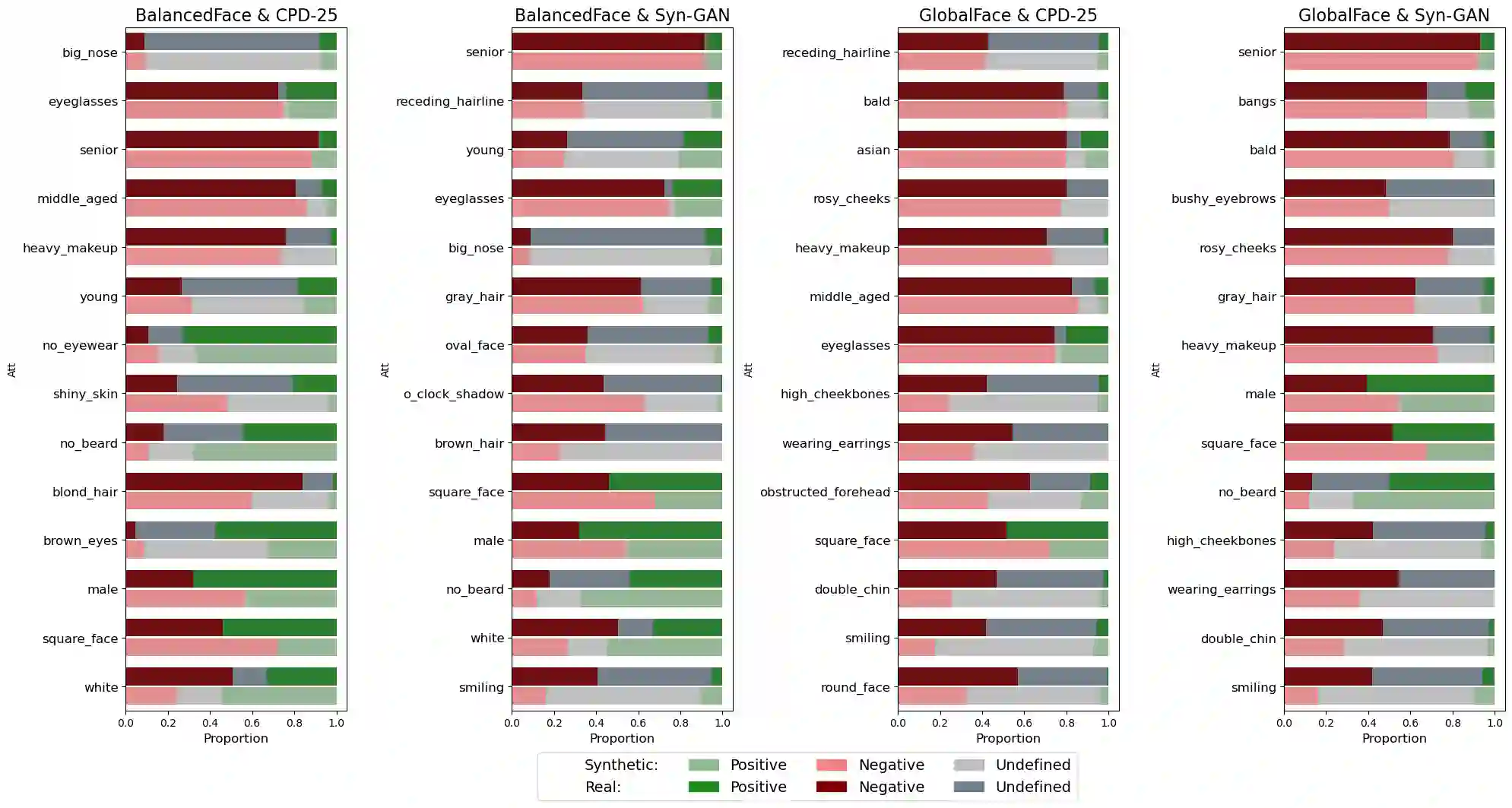
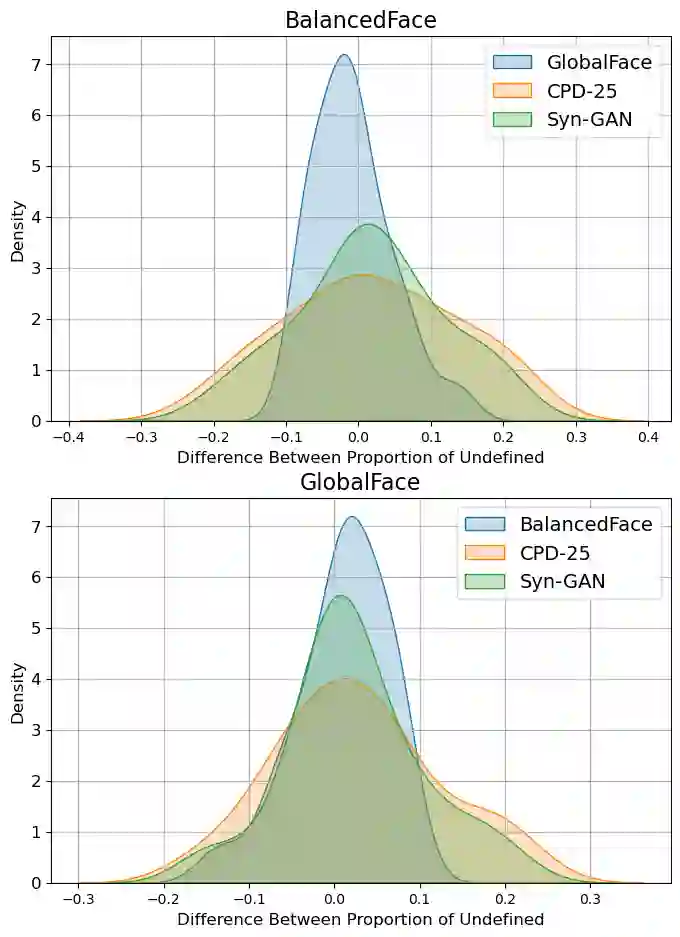
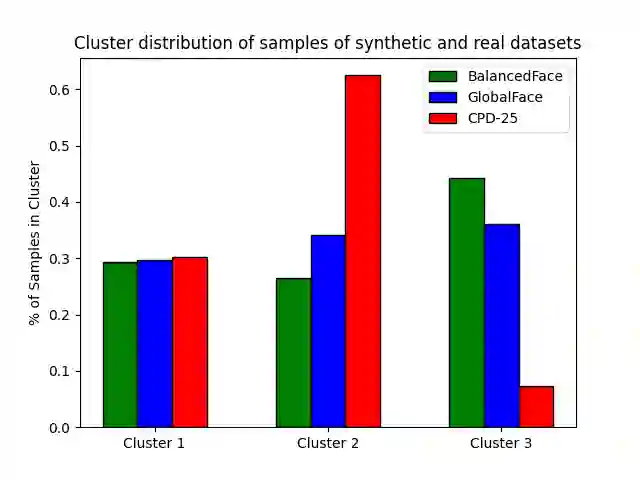
Face recognition applications have grown in parallel with the size of datasets, complexity of deep learning models and computational power. However, while deep learning models evolve to become more capable and computational power keeps increasing, the datasets available are being retracted and removed from public access. Privacy and ethical concerns are relevant topics within these domains. Through generative artificial intelligence, researchers have put efforts into the development of completely synthetic datasets that can be used to train face recognition systems. Nonetheless, the recent advances have not been sufficient to achieve performance comparable to the state-of-the-art models trained on real data. To study the drift between the performance of models trained on real and synthetic datasets, we leverage a massive attribute classifier (MAC) to create annotations for four datasets: two real and two synthetic. From these annotations, we conduct studies on the distribution of each attribute within all four datasets. Additionally, we further inspect the differences between real and synthetic datasets on the attribute set. When comparing through the Kullback-Leibler divergence we have found differences between real and synthetic samples. Interestingly enough, we have verified that while real samples suffice to explain the synthetic distribution, the opposite could not be further from being true.
翻译:暂无翻译