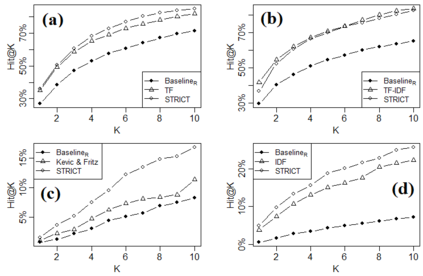
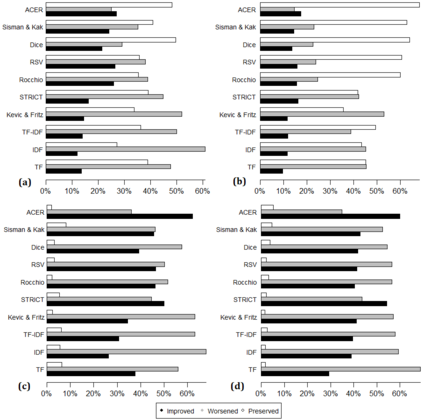
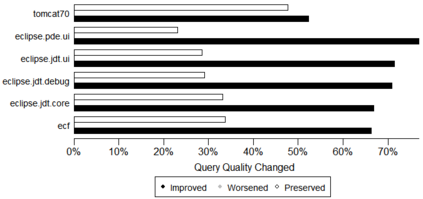
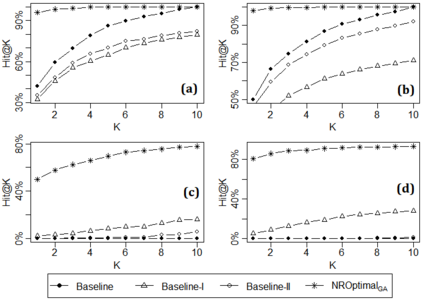
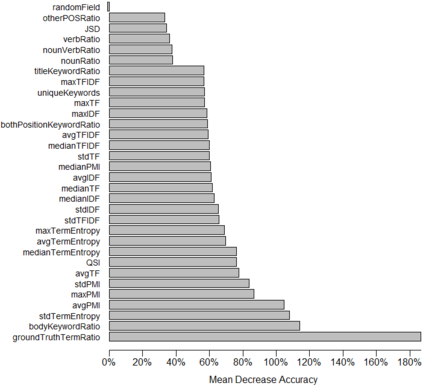
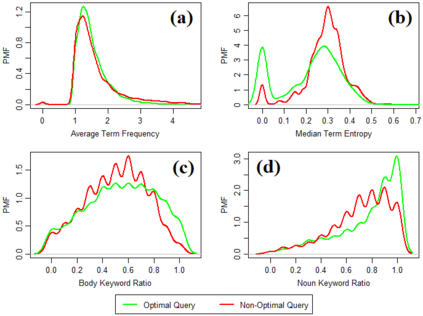
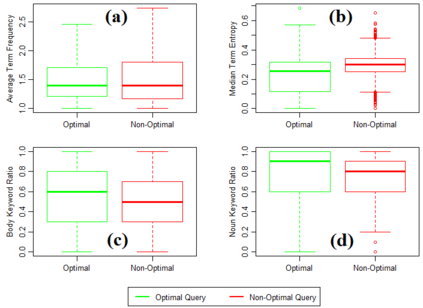
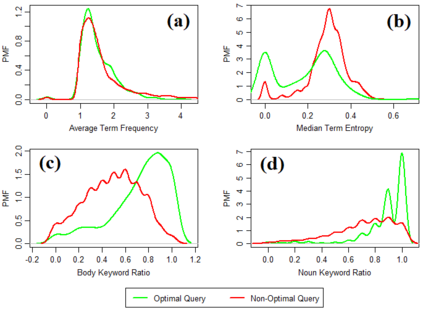
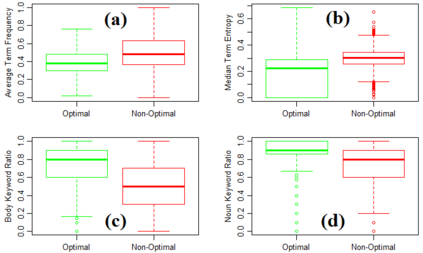
Being light-weight and cost-effective, IR-based approaches for bug localization have shown promise in finding software bugs. However, the accuracy of these approaches heavily depends on their used bug reports. A significant number of bug reports contain only plain natural language texts. According to existing studies, IR-based approaches cannot perform well when they use these bug reports as search queries. On the other hand, there is a piece of recent evidence that suggests that even these natural language-only reports contain enough good keywords that could help localize the bugs successfully. On one hand, these findings suggest that natural language-only bug reports might be a sufficient source for good query keywords. On the other hand, they cast serious doubt on the query selection practices in the IR-based bug localization. In this article, we attempted to clear the sky on this aspect by conducting an in-depth empirical study that critically examines the state-of-the-art query selection practices in IR-based bug localization. In particular, we use a dataset of 2,320 bug reports, employ ten existing approaches from the literature, exploit the Genetic Algorithm-based approach to construct optimal, near-optimal search queries from these bug reports, and then answer three research questions. We confirmed that the state-of-the-art query construction approaches are indeed not sufficient for constructing appropriate queries (for bug localization) from certain natural language-only bug reports although they contain such queries. We also demonstrate that optimal queries and non-optimal queries chosen from bug report texts are significantly different in terms of several keyword characteristics, which has led us to actionable insights. Furthermore, we demonstrate 27%--34% improvement in the performance of non-optimal queries through the application of our actionable insights to them.
翻译:光量和成本效益都比较轻, IR 的错误本地化方法在寻找软件错误时显示有希望。 但是, 这些方法的准确性很大程度上取决于它们所使用的错误报告。 大量错误报告只包含简单的自然语言文本。 根据现有的研究, IR 的错误报告在使用这些错误报告作为搜索查询时无法很好地运行。 另一方面, 最近有一块证据表明, 即使这些只使用语言的自然报告也包含足够的好关键词, 从而帮助错误成功本地化。 一方面, 这些结论表明, 自然只使用语言的错误报告可能足以成为良好的查询关键字的充足来源。 另一方面, 它们对于基于 IR 错误本地化的错误报告中的查询方法存在严重怀疑。 在目前, 我们试图通过深入的经验研究, 严格地检查基于 IR 本地化的查询方法中的最新查询方法。 特别是, 我们使用2, 320 错误报告中的数据集, 使用现有的方法, 利用基于遗传性 Algorith 的查询方法来获取良好的查询关键文本。 在目前, 我们的错误化报告中, 正在大量地进行不精确的查询, 我们的自然的查询, 正在从错误化报告, 通过构建适当的研究, 建立适当的方法, 我们的正确的方法在构建中, 我们的正确的方法在构建中, 。