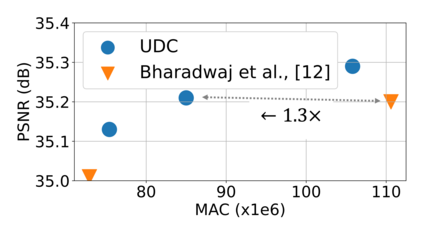
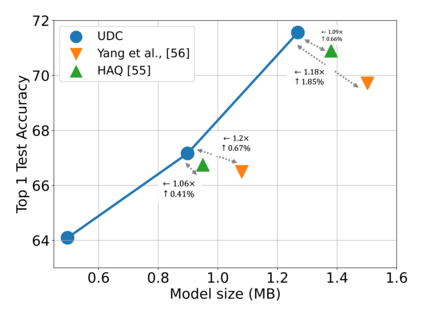
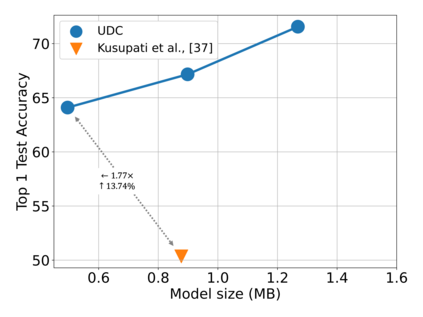
Emerging Internet-of-things (IoT) applications are driving deployment of neural networks (NNs) on heavily constrained low-cost hardware (HW) platforms, where accuracy is typically limited by memory capacity. To address this TinyML challenge, new HW platforms like neural processing units (NPUs) have support for model compression, which exploits aggressive network quantization and unstructured pruning optimizations. The combination of NPUs with HW compression and compressible models allows more expressive models in the same memory footprint. However, adding optimizations for compressibility on top of conventional NN architecture choices expands the design space across which we must make balanced trade-offs. This work bridges the gap between NPU HW capability and NN model design, by proposing a neural architecture search (NAS) algorithm to efficiently search a large design space, including: network depth, operator type, layer width, bitwidth, sparsity, and more. Building on differentiable NAS (DNAS) with several key improvements, we demonstrate Unified DNAS for Compressible models (UDC) on CIFAR100, ImageNet, and DIV2K super resolution tasks. On ImageNet, we find Pareto dominant compressible models, which are 1.9x smaller or 5.76% more accurate.
翻译:新兴互联网应用正在驱动神经网络网络(NNS)的部署,这些网络的准确性通常受到记忆能力的限制。为了应对这个微微ML挑战,神经处理器等新的HW平台支持模型压缩,这利用了积极的网络量化和无结构的调整优化。将NPU与HW压缩和压缩模型相结合,可以在同一记忆足迹中建立更清晰的模型。然而,在常规的NNW结构选择之上增加压缩优化,扩大设计空间,我们必须平衡取舍。这项工作缩小了NPU HW能力和NNNW模型设计之间的差距,为此提议了一个神经结构搜索算法,以高效搜索大型设计空间,包括:网络深度、操作器类型、层宽度、微宽度、宽度和压缩模型等。在不同的NAS(DNAS)上加了几个关键改进,我们展示了统一的DNA系统,用于可压缩的模型(UDUDC)和5.KFARM(SMAFR) 或更小型的图像模型(UDFAR) 。