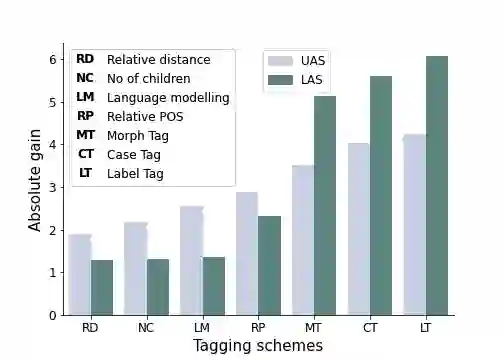
Neural dependency parsing has achieved remarkable performance for many domains and languages. The bottleneck of massive labeled data limits the effectiveness of these approaches for low resource languages. In this work, we focus on dependency parsing for morphological rich languages (MRLs) in a low-resource setting. Although morphological information is essential for the dependency parsing task, the morphological disambiguation and lack of powerful analyzers pose challenges to get this information for MRLs. To address these challenges, we propose simple auxiliary tasks for pretraining. We perform experiments on 10 MRLs in low-resource settings to measure the efficacy of our proposed pretraining method and observe an average absolute gain of 2 points (UAS) and 3.6 points (LAS). Code and data available at: https://github.com/jivnesh/LCM
翻译:在许多领域和语言中,神经依赖性分析取得了显著的成绩。大量标签数据瓶颈限制了这些低资源语言方法的有效性。在这项工作中,我们侧重于低资源环境中形态丰富语言的依赖性分析。虽然形态信息对于依赖性分析任务至关重要,但形态扭曲和缺乏强大的分析师对为MRL获取这种信息构成挑战。为了应对这些挑战,我们建议为培训前工作提供简单的辅助任务。我们在低资源环境中对10个MRL进行试验,以衡量我们拟议的预培训方法的功效,并观察到平均绝对增益2点(UAS)和3.6点(LAS)。法规和数据见:https://github.com/jivnesh/LCM。