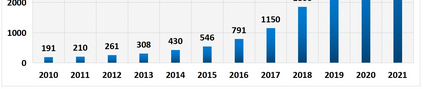
Human-in-the-loop aims to train an accurate prediction model with minimum cost by integrating human knowledge and experience. Humans can provide training data for machine learning applications and directly accomplish tasks that are hard for computers in the pipeline with the help of machine-based approaches. In this paper, we survey existing works on human-in-the-loop from a data perspective and classify them into three categories with a progressive relationship: (1) the work of improving model performance from data processing, (2) the work of improving model performance through interventional model training, and (3) the design of the system independent human-in-the-loop. Using the above categorization, we summarize major approaches in the field; along with their technical strengths/ weaknesses, we have simple classification and discussion in natural language processing, computer vision, and others. Besides, we provide some open challenges and opportunities. This survey intends to provide a high-level summarization for human-in-the-loop and motivates interested readers to consider approaches for designing effective human-in-the-loop solutions.
翻译:通过综合人类知识和经验,人类可以提供机器学习应用培训数据,直接完成计算机在机器基础上难以完成的任务。在本文件中,我们从数据角度调查现有关于“人中环”的工作,将其分为三个渐进关系类别:(1) 改进数据处理模型工作,(2) 通过干预模式培训改进模型业绩的工作,(3) 通过独立“人中环”系统的设计。我们利用上述分类,总结了该领域的主要办法;除了技术优势/弱点外,我们还在自然语言处理、计算机愿景和其他方面进行简单分类和讨论。此外,我们提供一些公开的挑战和机遇,旨在为“人中环”提供高层次的组合,激励感兴趣的读者考虑设计有效的“人中环”解决方案的方法。