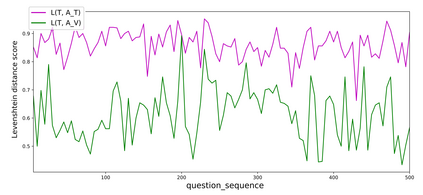
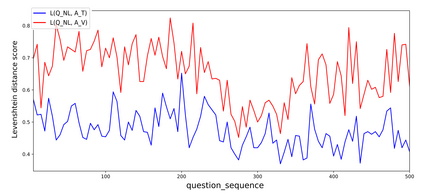
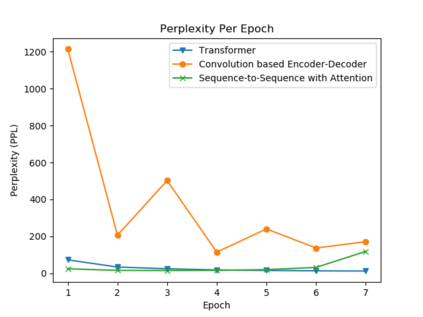
In the last years, there have been significant developments in the area of Question Answering over Knowledge Graphs (KGQA). Despite all the notable advancements, current KGQA datasets only provide the answers as the direct output result of the formal query, rather than full sentences incorporating question context. For achieving coherent answers sentence with the question's vocabulary, template-based verbalization so are usually employed for a better representation of answers, which in turn require extensive expert intervention. Thus, making way for machine learning approaches; however, there is a scarcity of datasets that empower machine learning models in this area. Hence, we provide the VANiLLa dataset which aims at reducing this gap by offering answers in natural language sentences. The answer sentences in this dataset are syntactically and semantically closer to the question than to the triple fact. Our dataset consists of over 100k simple questions adapted from the CSQA and SimpleQuestionsWikidata datasets and generated using a semi-automatic framework. We also present results of training our dataset on multiple baseline models adapted from current state-of-the-art Natural Language Generation (NLG) architectures. We believe that this dataset will allow researchers to focus on finding suitable methodologies and architectures for answer verbalization.
翻译:过去几年来,在知识图的问答(KGQA)领域取得了显著进展。尽管取得了各种显著的进步,但当前的 KGQA 数据集仅作为正式查询的直接输出结果提供答案,而不是包含问题背景的完整句子。为了用问题词汇获得一致的回答句,通常采用基于模板的口头表述来更好地表述答案,而这反过来又需要广泛的专家干预。因此,为机器学习方法开辟了道路;然而,为在这一领域的机器学习模型提供了赋权的数据集。因此,我们提供了VANilla数据集,目的是通过在自然语言句中提供答案来缩小这一差距。这一数据集的回答句与问题比三重更近,在语义上更接近。我们的数据集由100多个简单的问题组成,它们来自CSQA和简单问题Wikiddata数据集,并使用半自动框架生成。我们还介绍了我们关于从当前状态和艺术搜索的自然语言结构中调整的多条基线模型的培训结果,我们相信,我们将让研究人员能够找到合适的语言结构。