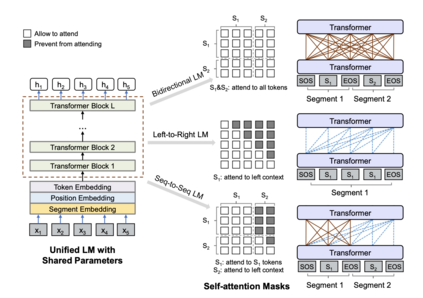
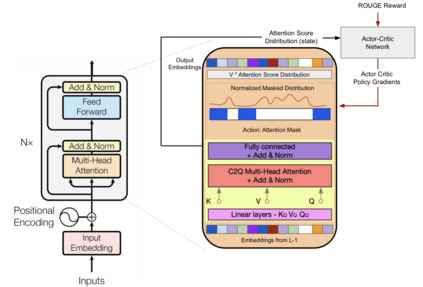
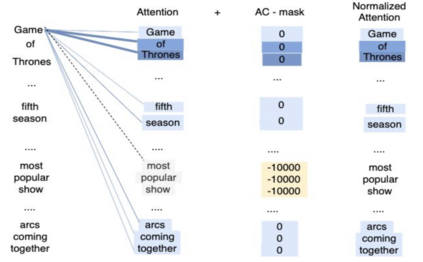
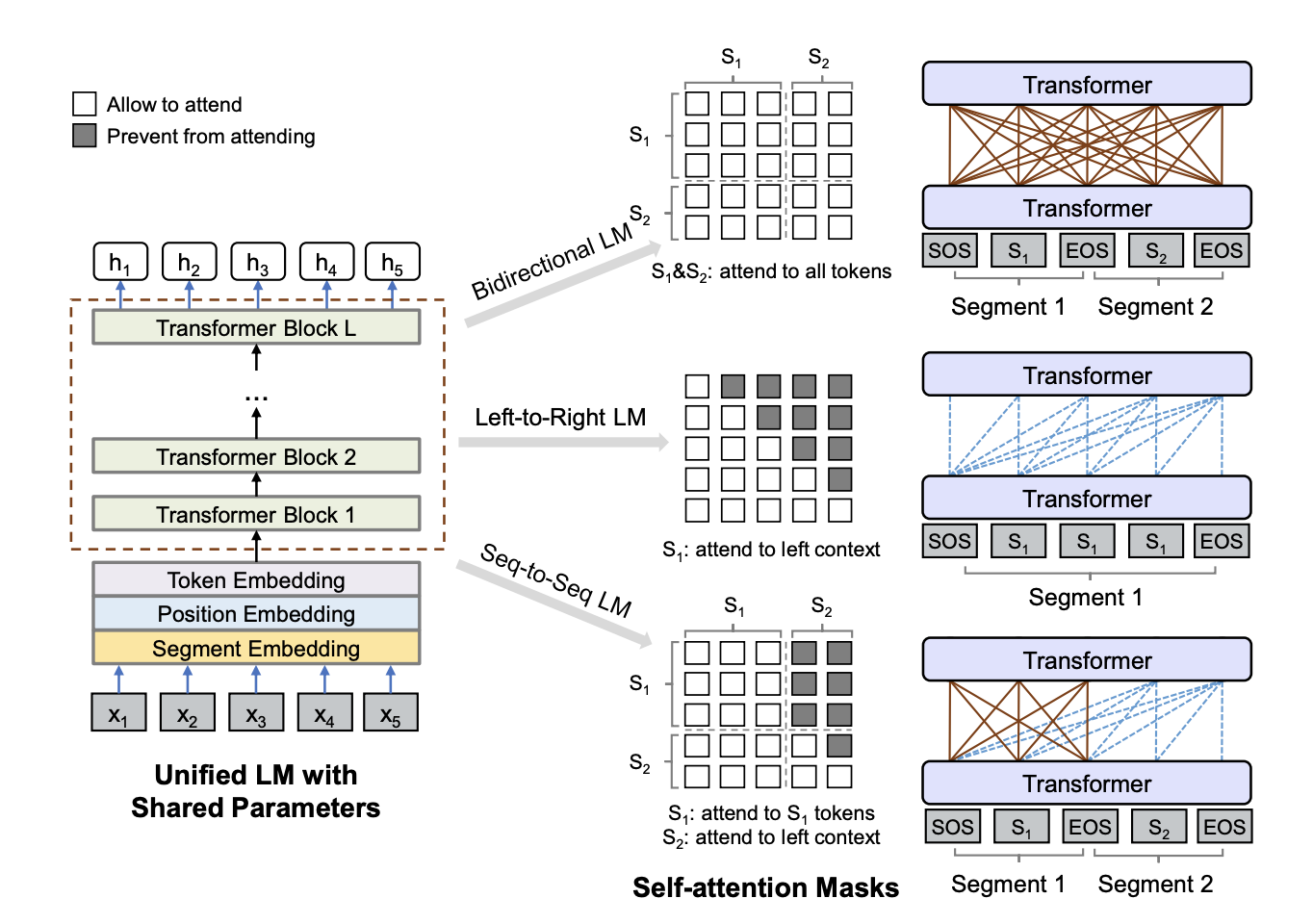
We present a novel architectural scheme to tackle the abstractive summarization problem based on the CNN/DMdataset which fuses Reinforcement Learning (RL) withUniLM, which is a pre-trained Deep Learning Model, to solve various natural language tasks. We have tested the limits of learning fine-grained attention in Transformers to improve the summarization quality. UniLM applies attention to the entire token space in a global fashion. We propose DR.SAS which applies the Actor-Critic (AC) algorithm to learn a dynamic self-attention distribution over the tokens to reduce redundancy and generate factual and coherent summaries to improve the quality of summarization. After performing hyperparameter tuning, we achievedbetter ROUGE results compared to the baseline. Our model tends to be more extractive/factual yet coherent in detail because of optimization over ROUGE rewards. We present detailed error analysis with examples of the strengths and limitations of our model. Our codebase will be publicly available on our GitHub.
翻译:我们根据CNN/DMDDdataset提出一个新的建筑计划,以解决抽象的总结问题。 CNN/DMDDdataset将强化学习(RL)与UniLM相结合,UniLM是经过事先训练的深造模型,目的是解决各种自然语言任务。我们已经测试了在变形器中学习精细的注意力的限度,以提高合成质量。UniLM以全球方式关注整个象征性空间。我们建议DR.SAS采用Actor-Critic(AC)算法,在符号上学习动态的自我注意分配,以减少冗余,产生事实和连贯的总结,以提高合成质量。在进行超参数调整后,我们取得了更好的ROUGE结果。我们的模型往往更加精细的采性/现实性,但由于对ROUGE奖励的优化,我们提出了详细的错误分析,并举例说明了我们的模型的优点和局限性。我们的代码库将在我们的GitHub上公开提供。