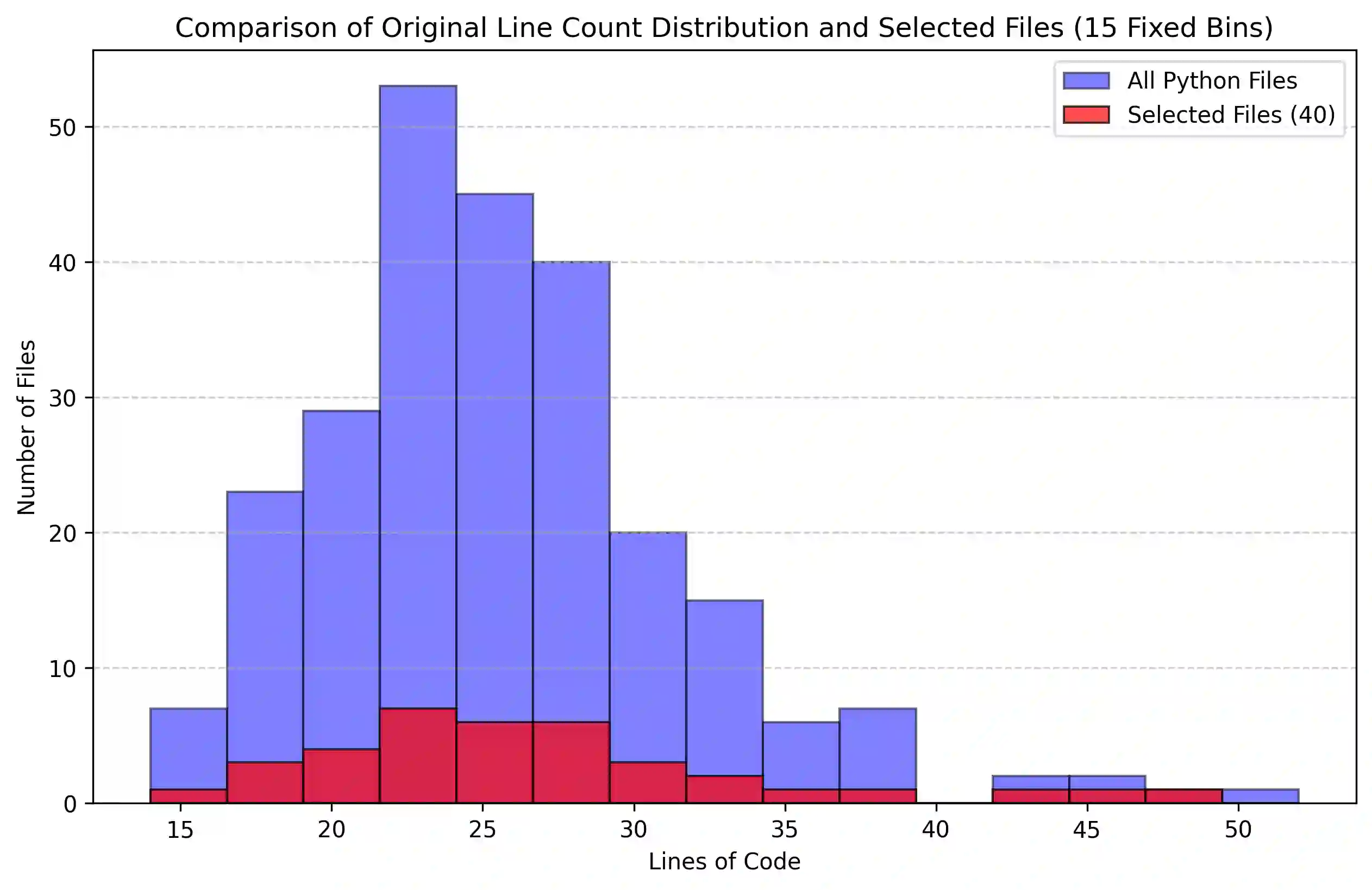
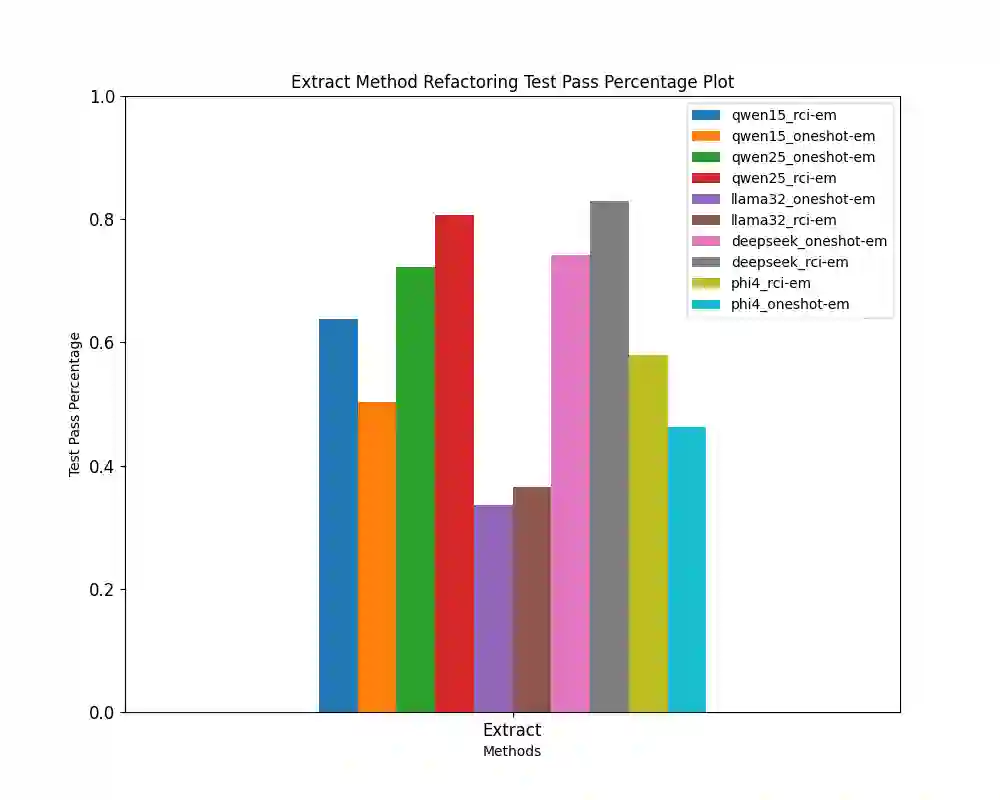
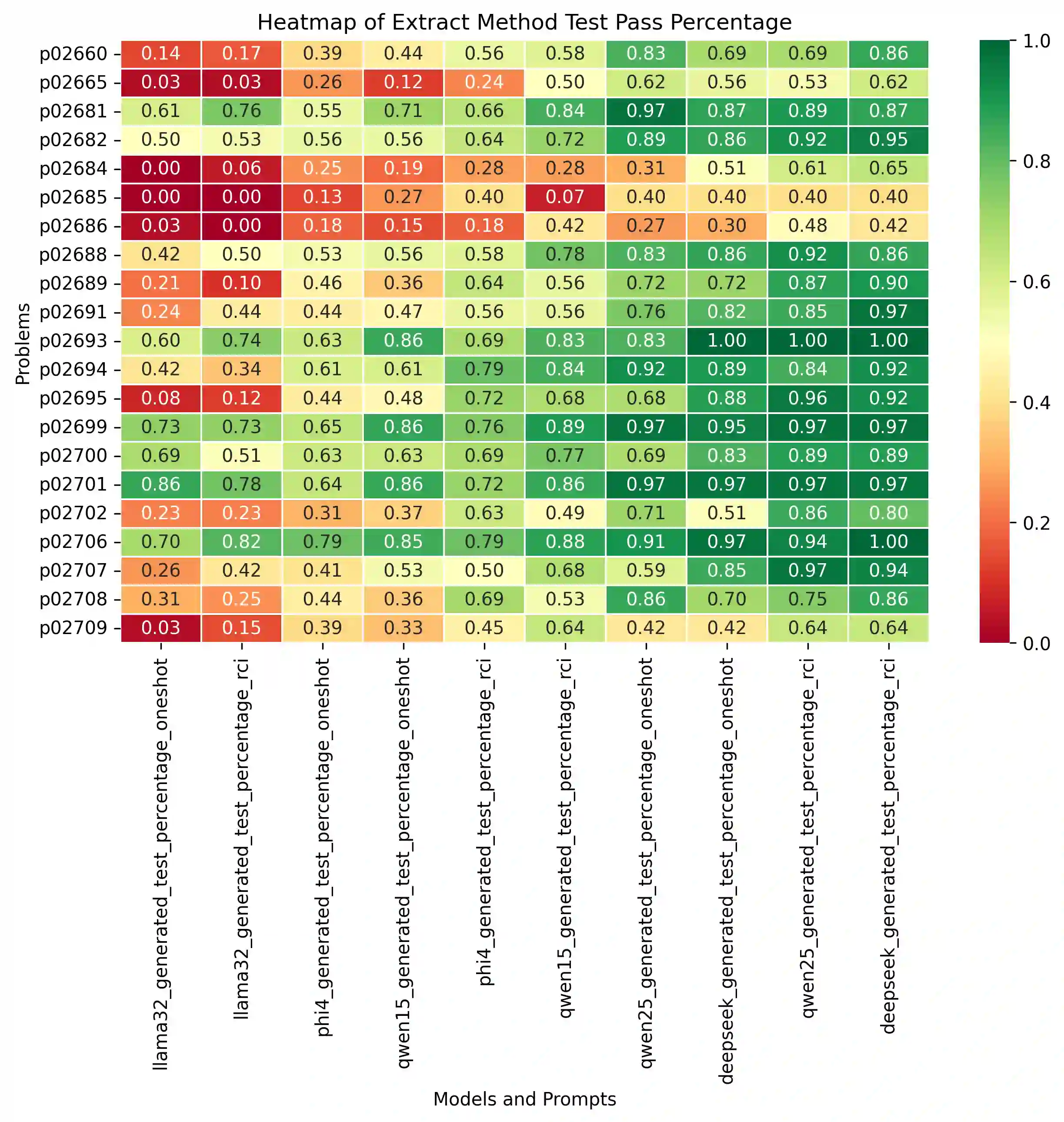
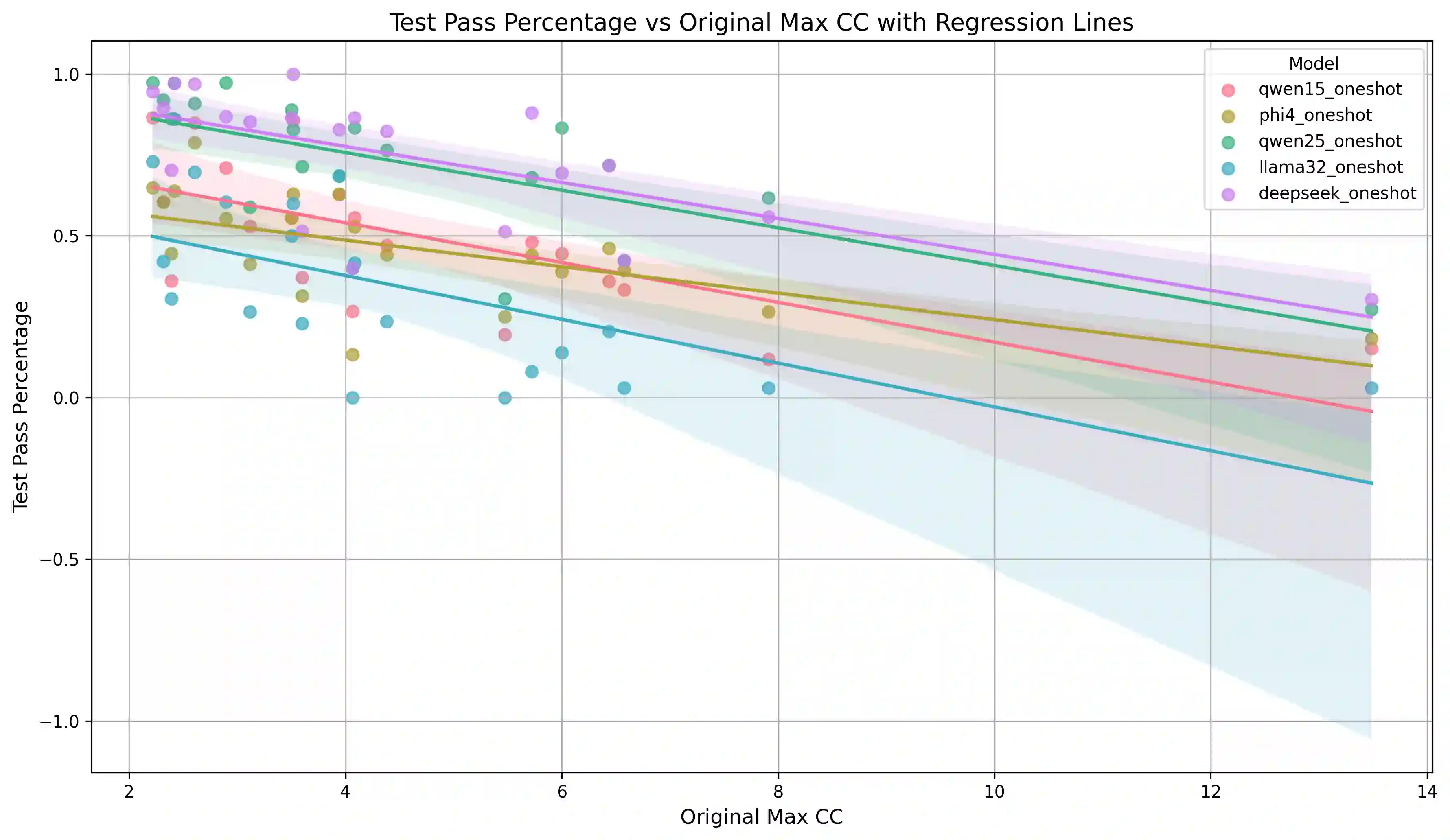
Automating the Extract Method refactoring (EMR) remains challenging and largely manual despite its importance in improving code readability and maintainability. Recent advances in open-source, resource-efficient Large Language Models (LLMs) offer promising new approaches for automating such high-level tasks. In this work, we critically evaluate five state-of-the-art open-source LLMs, spanning 3B to 8B parameter sizes, on the EMR task for Python code. We systematically assess functional correctness and code quality using automated metrics and investigate the impact of prompting strategies by comparing one-shot prompting to a Recursive criticism and improvement (RCI) approach. RCI-based prompting consistently outperforms one-shot prompting in test pass rates and refactoring quality. The best-performing models, Deepseek-Coder-RCI and Qwen2.5-Coder-RCI, achieve test pass percentage (TPP) scores of 0.829 and 0.808, while reducing lines of code (LOC) per method from 12.103 to 6.192 and 5.577, and cyclomatic complexity (CC) from 4.602 to 3.453 and 3.294, respectively. A developer survey on RCI-generated refactorings shows over 70% acceptance, with Qwen2.5-Coder rated highest across all evaluation criteria. In contrast, the original code scored below neutral, particularly in readability and maintainability, underscoring the benefits of automated refactoring guided by quality prompts. While traditional metrics like CC and LOC provide useful signals, they often diverge from human judgments, emphasizing the need for human-in-the-loop evaluation. Our open-source benchmark offers a foundation for future research on automated refactoring with LLMs.
翻译:尽管提取方法重构(EMR)对于提升代码可读性和可维护性至关重要,但其自动化实现仍面临挑战,目前主要依赖人工操作。近期,资源高效的开源大语言模型(LLMs)的进展为自动化此类高级任务提供了前景广阔的新途径。本研究针对Python代码的EMR任务,对五种参数规模从30亿到80亿不等的先进开源LLMs进行了批判性评估。我们采用自动化指标系统评估了功能正确性与代码质量,并通过比较单次提示与递归批评与改进(RCI)方法,探究了提示策略的影响。基于RCI的提示方法在测试通过率和重构质量方面持续优于单次提示。表现最佳的模型Deepseek-Coder-RCI和Qwen2.5-Coder-RCI分别实现了0.829和0.808的测试通过百分比(TPP)得分,同时将每个方法的代码行数(LOC)从12.103分别降低至6.192和5.577,圈复杂度(CC)从4.602分别降至3.453和3.294。针对RCI生成重构的开发者调查显示超过70%的接受度,其中Qwen2.5-Coder在所有评估标准中评分最高。相比之下,原始代码的评分低于中性水平,特别是在可读性和可维护性方面,这凸显了基于高质量提示的自动化重构的优势。虽然传统指标如CC和LOC能提供有效参考,但它们常与人工判断存在偏差,强调了人在环评估的必要性。我们开源的基准测试为未来基于LLMs的自动化重构研究奠定了基础。