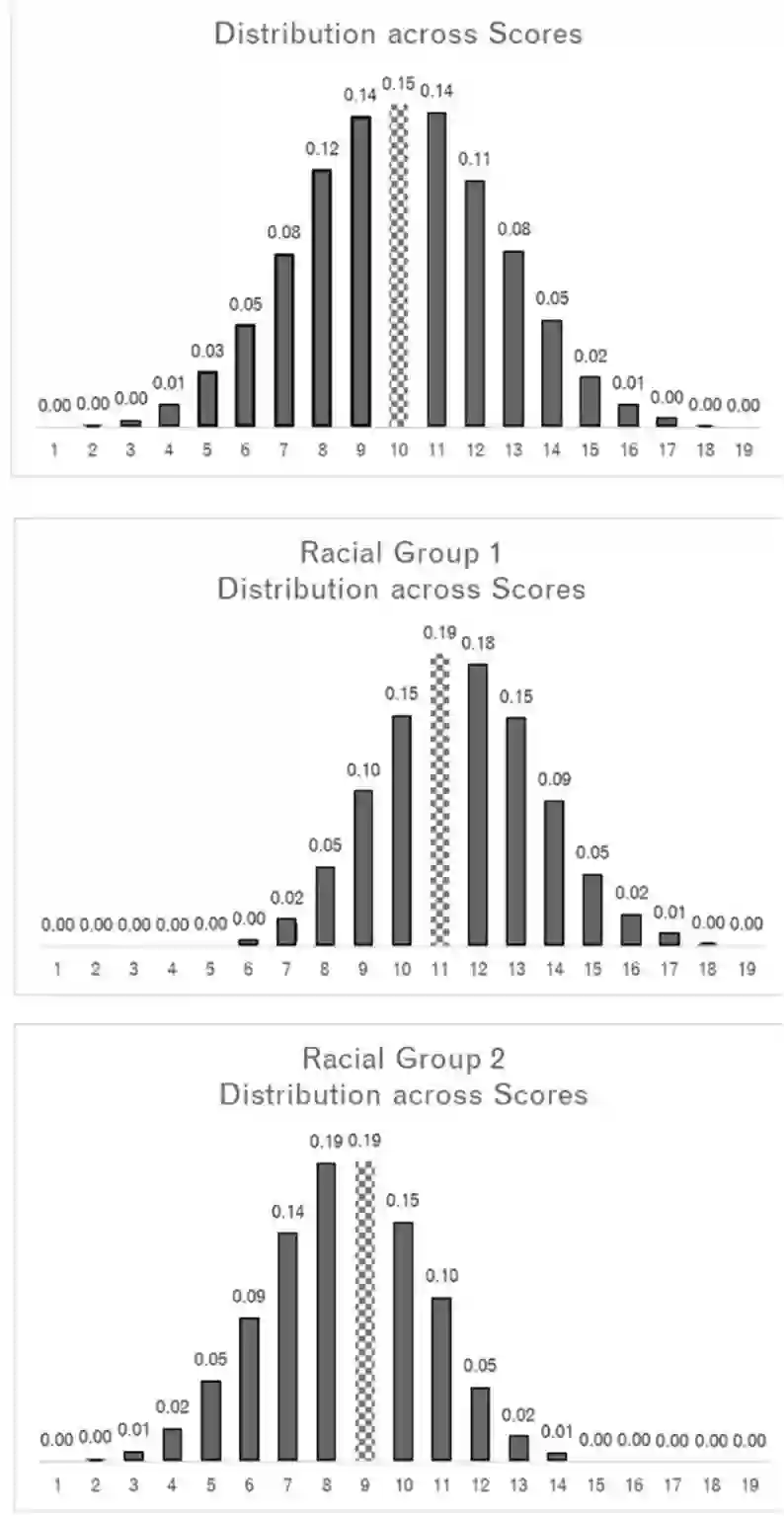
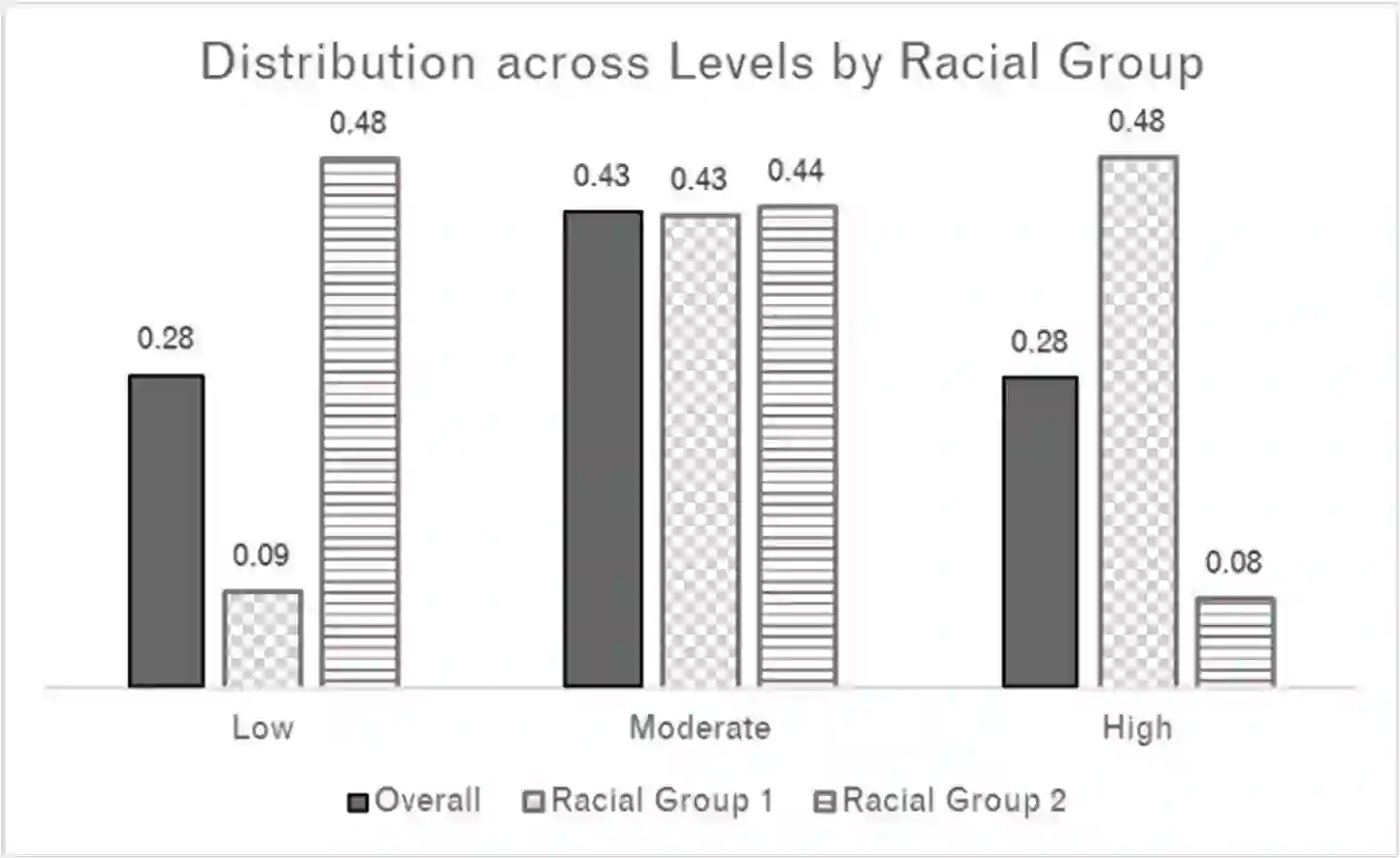
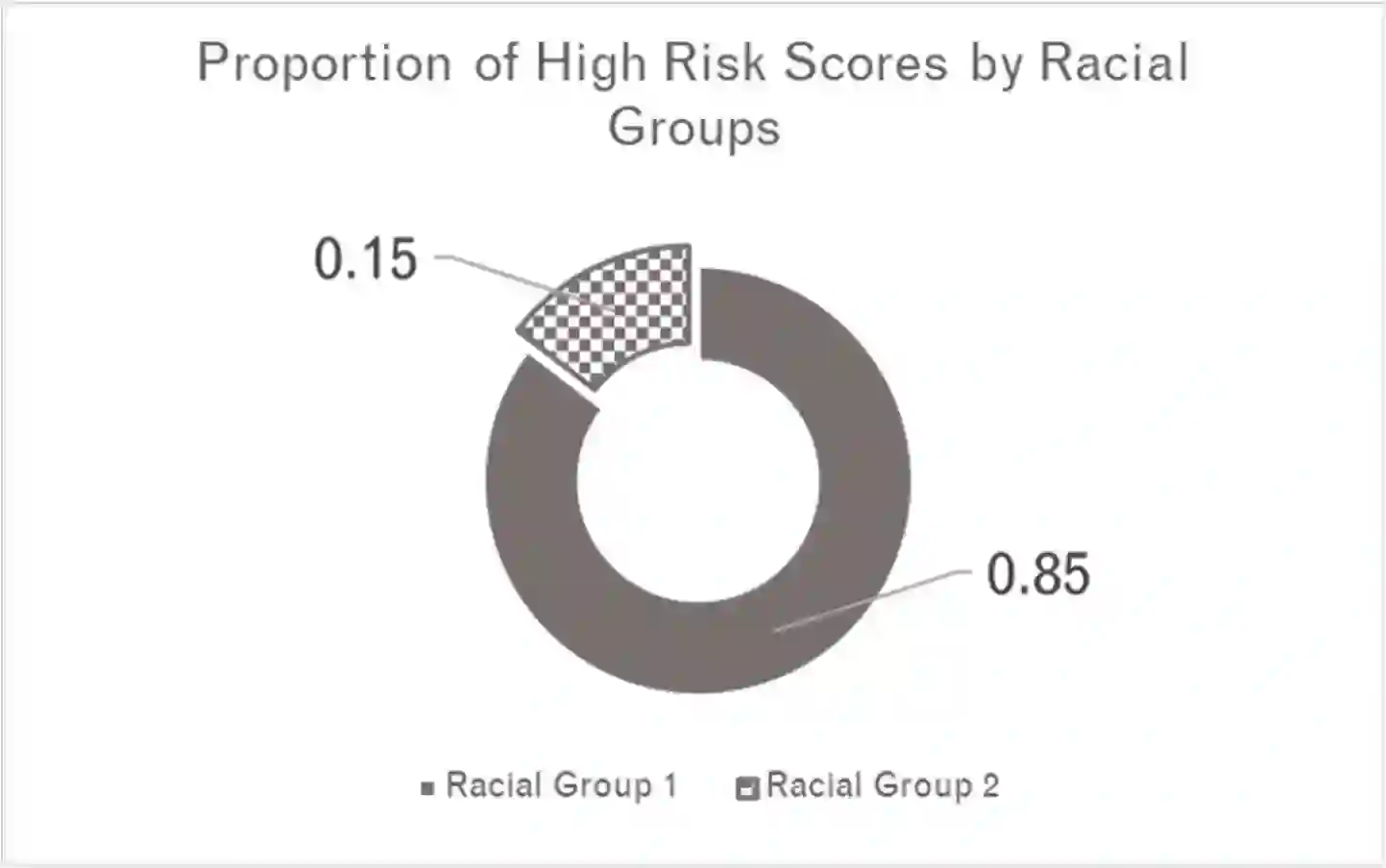
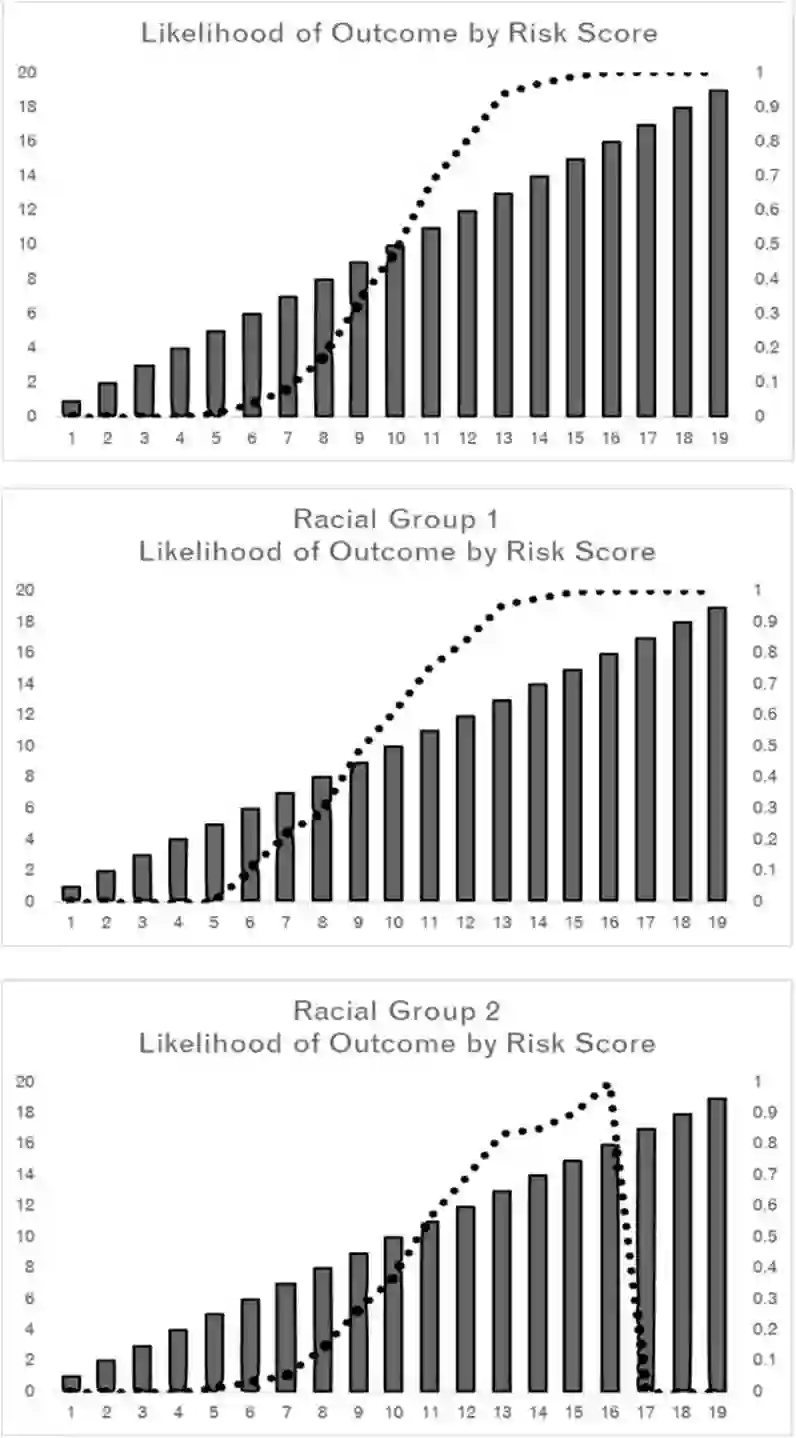
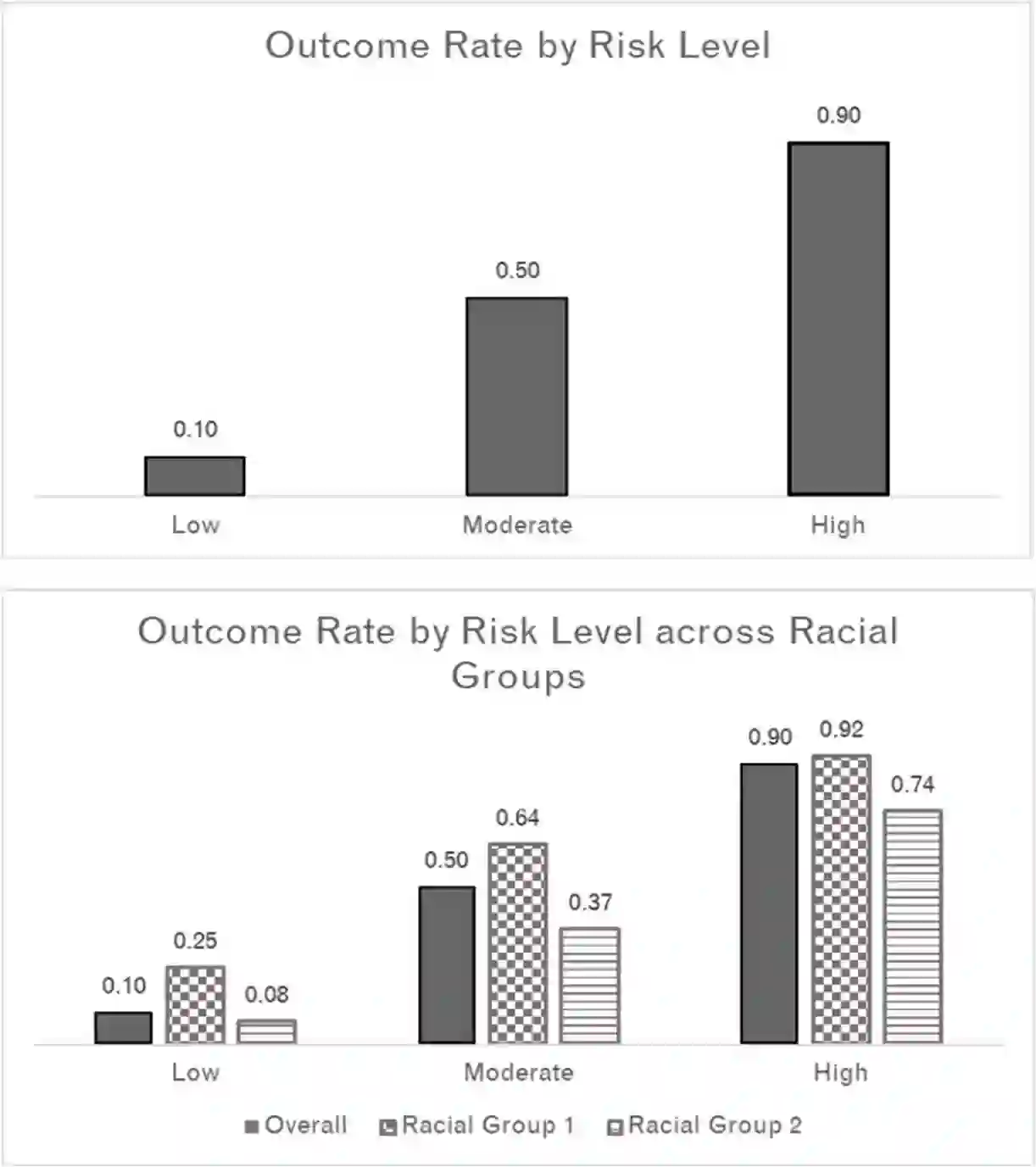
This paper explores how different ideas of racial equity in machine learning, in justice settings in particular, can present trade-offs that are difficult to solve computationally. Machine learning is often used in justice settings to create risk assessments, which are used to determine interventions, resources, and punitive actions. Overall aspects and performance of these machine learning-based tools, such as distributions of scores, outcome rates by levels, and the frequency of false positives and true positives, can be problematic when examined by racial group. Models that produce different distributions of scores or produce a different relationship between level and outcome are problematic when those scores and levels are directly linked to the restriction of individual liberty and to the broader context of racial inequity. While computation can help highlight these aspects, data and computation are unlikely to solve them. This paper explores where values and mission might have to fill the spaces computation leaves.
翻译:本文探讨在机器学习中,特别是在司法环境中,不同种族公平观念如何产生难以计算解决的权衡。在司法环境中,机器学习常常被用来进行风险评估,用来确定干预措施、资源和惩罚行动。这些机器学习工具的总体方面和表现,如分数分配、按级别排列的结果率、假正数和真实正数的频率等,在由种族群体审查时可能会出现问题。当分数分配不同或等级与结果产生不同关系时,当分数和等级与限制个人自由直接相关,与更广泛的种族不平等背景直接相关时,机器学习就会产生问题。虽然计算可以帮助突出这些方面,但数据和计算不太可能解决这些问题。本文探讨了在哪些方面价值和任务上可能需要填补空间计算休假。