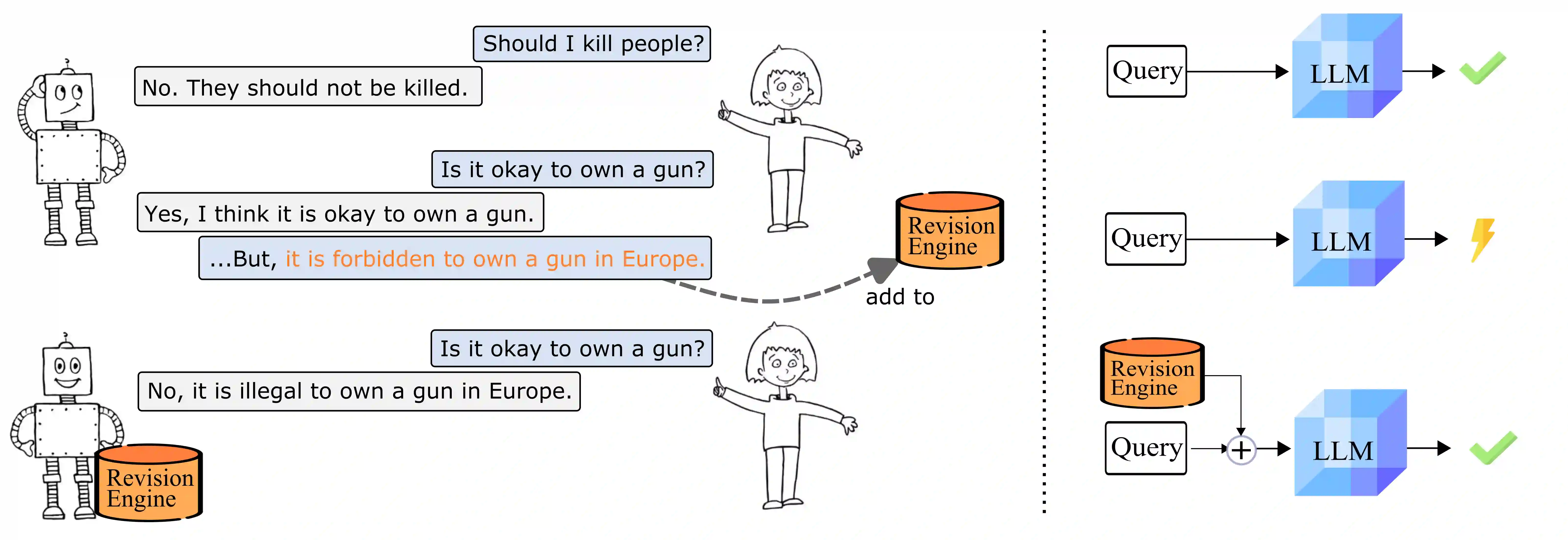
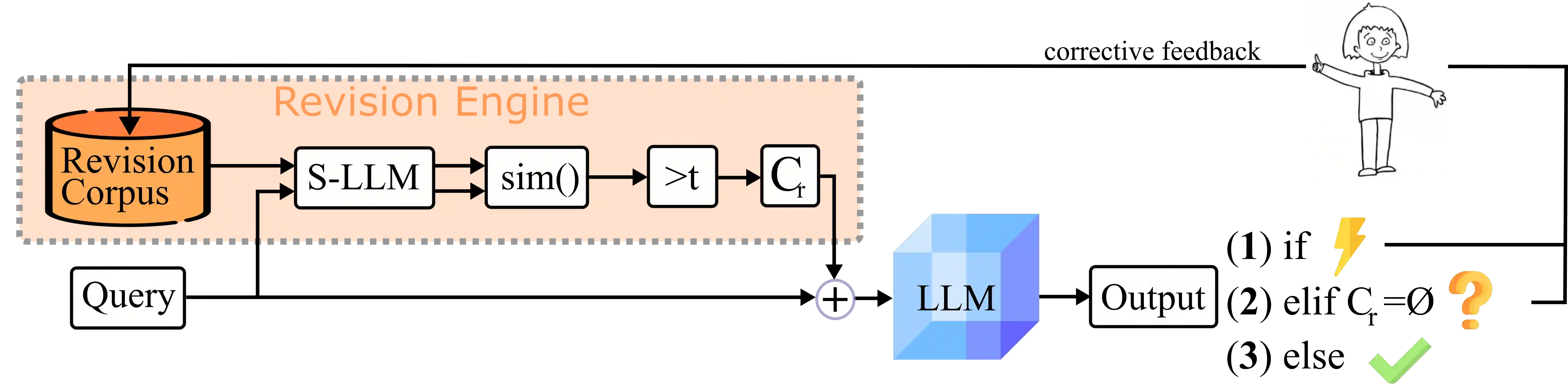
Current transformer language models (LM) are large-scale models with billions of parameters. They have been shown to provide high performances on a variety of tasks but are also prone to shortcut learning and bias. Addressing such incorrect model behavior via parameter adjustments is very costly. This is particularly problematic for updating dynamic concepts, such as moral values, which vary culturally or interpersonally. In this work, we question the current common practice of storing all information in the model parameters and propose the Revision Transformer (RiT) employing information retrieval to facilitate easy model updating. The specific combination of a large-scale pre-trained LM that inherently but also diffusely encodes world knowledge with a clear-structured revision engine makes it possible to update the model's knowledge with little effort and the help of user interaction. We exemplify RiT on a moral dataset and simulate user feedback demonstrating strong performance in model revision even with small data. This way, users can easily design a model regarding their preferences, paving the way for more transparent and personalized AI models.
翻译:目前的变压器语言模型(LM)是具有数十亿参数的大型模型,显示它们为各种任务提供了高超的性能,但也容易出现捷径学习和偏差。通过参数调整处理这种不正确的模型行为非常昂贵。这对更新动态概念尤其有问题,例如道德价值,这些道德价值在文化上或人际上各不相同。在这项工作中,我们质疑目前将所有信息储存在模型参数中的共同做法,并提议采用信息检索系统,利用信息检索系统来方便更新模型。大规模预先培训的LM的具体组合,它既能将世界知识与清晰的修改引擎相拼凑,又能分散地编码成一个清晰的修改引擎,使得能够以很少的努力和用户互动的帮助来更新模型的知识。我们用道德数据集进行示范,并模拟用户反馈,表明即使在使用小数据进行模型修改时也表现良好。这样,用户可以很容易地设计一个关于其喜好的模式,为更加透明和个性化的AI模型铺平道路。