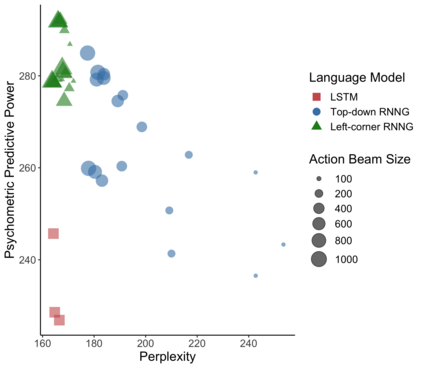
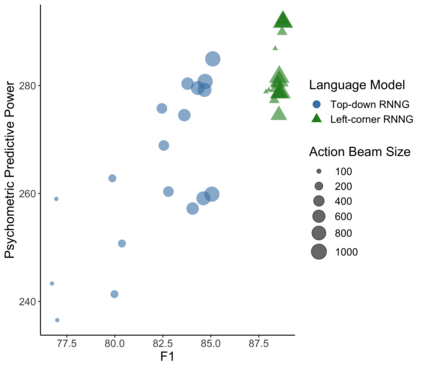
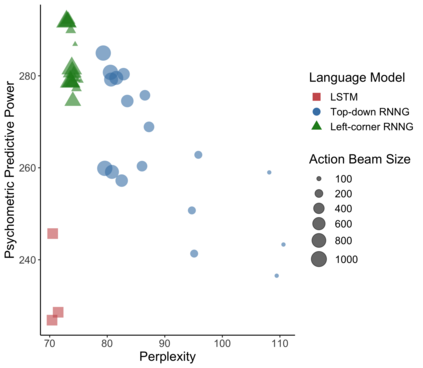
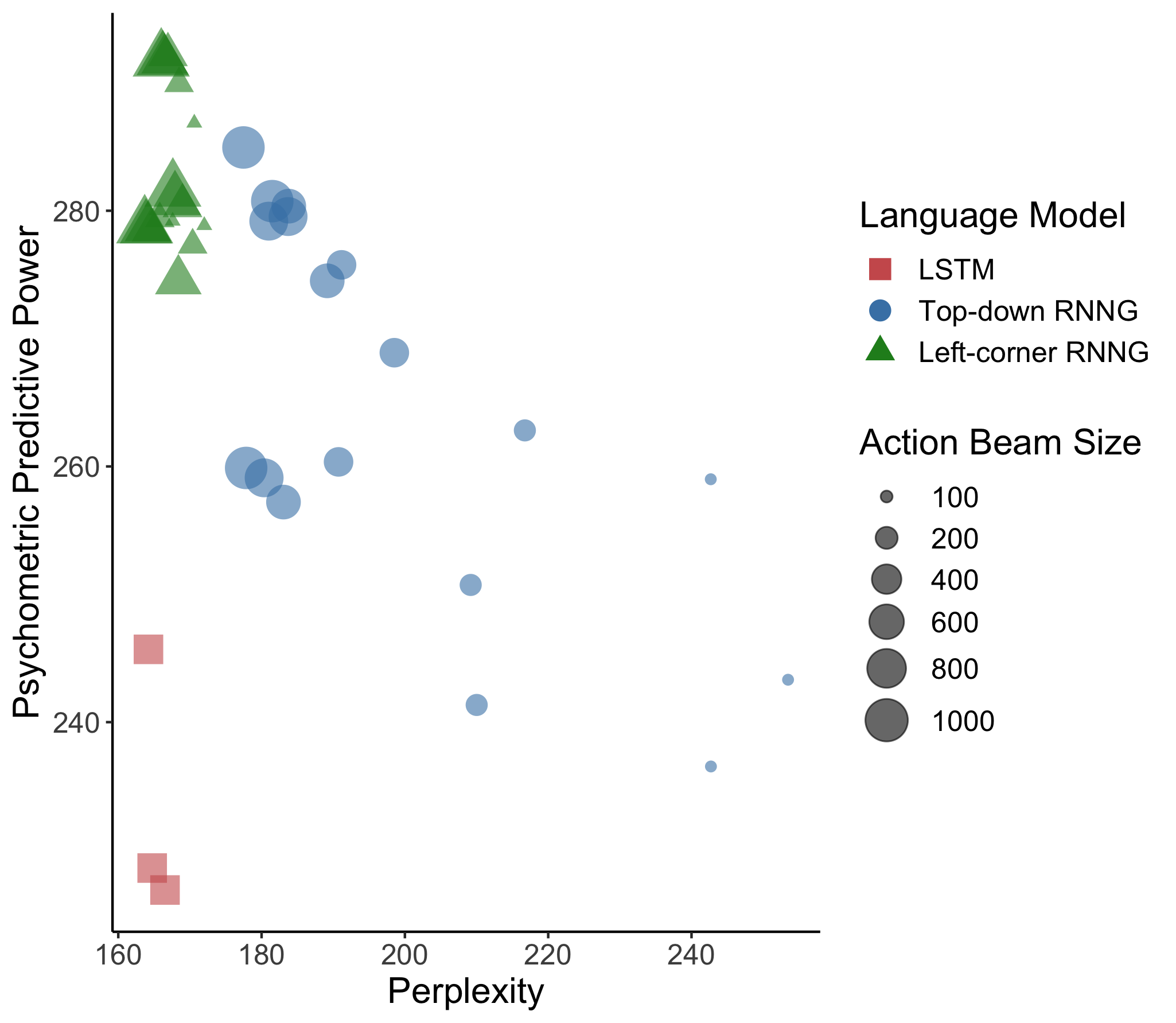
In computational linguistics, it has been shown that hierarchical structures make language models (LMs) more human-like. However, the previous literature has been agnostic about a parsing strategy of the hierarchical models. In this paper, we investigated whether hierarchical structures make LMs more human-like, and if so, which parsing strategy is most cognitively plausible. In order to address this question, we evaluated three LMs against human reading times in Japanese with head-final left-branching structures: Long Short-Term Memory (LSTM) as a sequential model and Recurrent Neural Network Grammars (RNNGs) with top-down and left-corner parsing strategies as hierarchical models. Our computational modeling demonstrated that left-corner RNNGs outperformed top-down RNNGs and LSTM, suggesting that hierarchical and left-corner architectures are more cognitively plausible than top-down or sequential architectures. In addition, the relationships between the cognitive plausibility and (i) perplexity, (ii) parsing, and (iii) beam size will also be discussed.
翻译:在计算语言学中,人们发现,等级结构使语言模型(LMs)更加人性化。然而,以前的文献对等级模型的分解策略是不可知的。在本文中,我们调查了等级结构是否使LMs更像人,如果是的话,哪个分解策略在认知上最可信。为了解决这个问题,我们用头等左分层结构对日本人的阅读时间进行了三个LMs:长期短期内存(LSTM)作为顺序模型,经常的神经网络语法网(RNNNGs)作为上下和左角的分级模型。我们的计算模型表明,左角RNNGs的自上而下的RNGs和LSTM的形状优于自上而下的RNGs和LSTM。这表明,等级和左角结构比上下或顺序结构在认知上下更可信。此外,还将讨论认知性常识和(i)不易懂、(ii)和(iii)波段大小之间的关系。