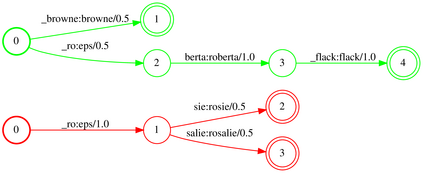
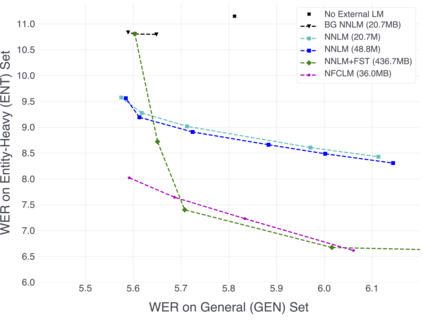
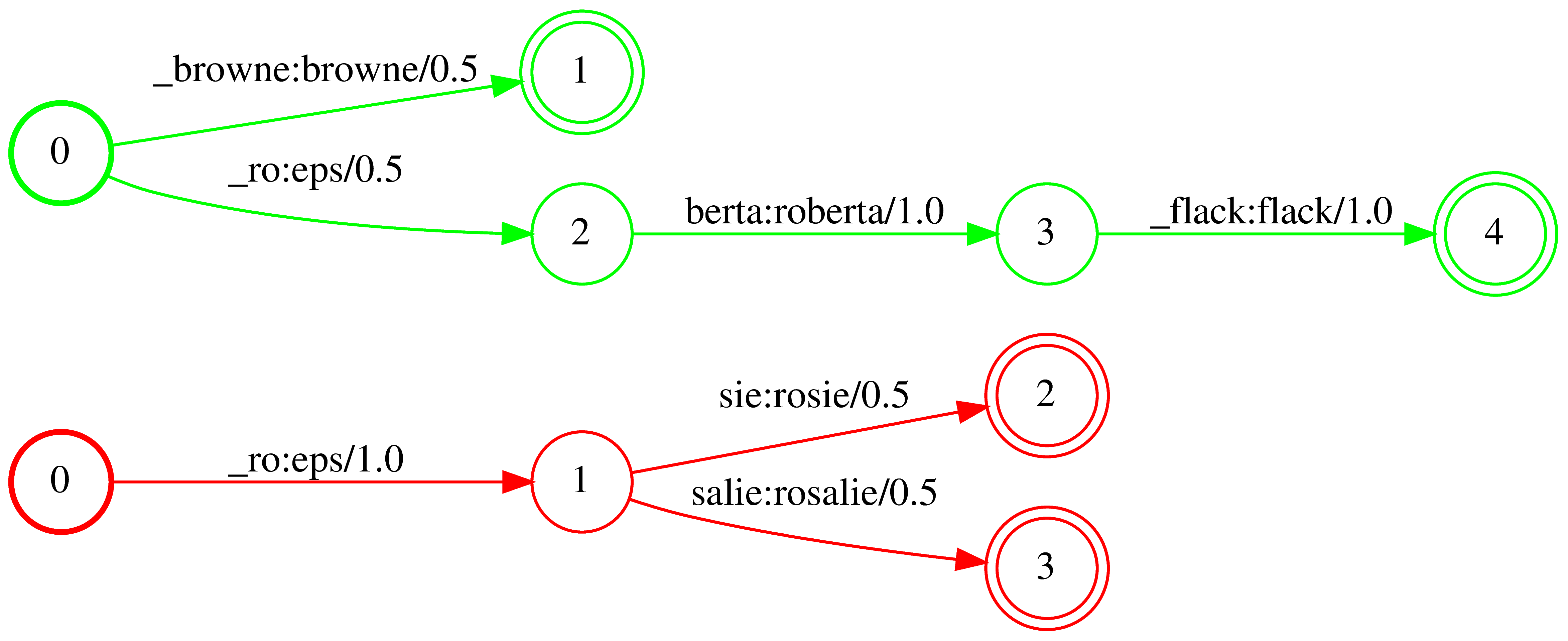
We propose Neural-FST Class Language Model (NFCLM) for end-to-end speech recognition, a novel method that combines neural network language models (NNLMs) and finite state transducers (FSTs) in a mathematically consistent framework. Our method utilizes a background NNLM which models generic background text together with a collection of domain-specific entities modeled as individual FSTs. Each output token is generated by a mixture of these components; the mixture weights are estimated with a separately trained neural decider. We show that NFCLM significantly outperforms NNLM by 15.8% relative in terms of Word Error Rate. NFCLM achieves similar performance as traditional NNLM and FST shallow fusion while being less prone to overbiasing and 12 times more compact, making it more suitable for on-device usage.
翻译:我们建议使用神经-FST类语言模型(NFLM)进行终端到终端语音识别,这是一种在数学上一致的框架内将神经网络语言模型(NNLM)和有限状态传感器(FSTs)相结合的新颖方法。我们的方法是使用一个背景 NNLM来模拟通用背景文本和以单个FSTs为模型的一组特定域实体。每种输出符号都是由这些组成部分的混合产生的;混合重量由经过单独培训的神经决定器来估算。我们显示,NFCLM在字型错误率方面明显比NNNLM高出15.8%。 NFCLM取得了与传统的NNLMM和FST浅质融合相似的性能,同时不那么容易过分偏差,而且比常规要多12倍,因此更适合在设计中使用。