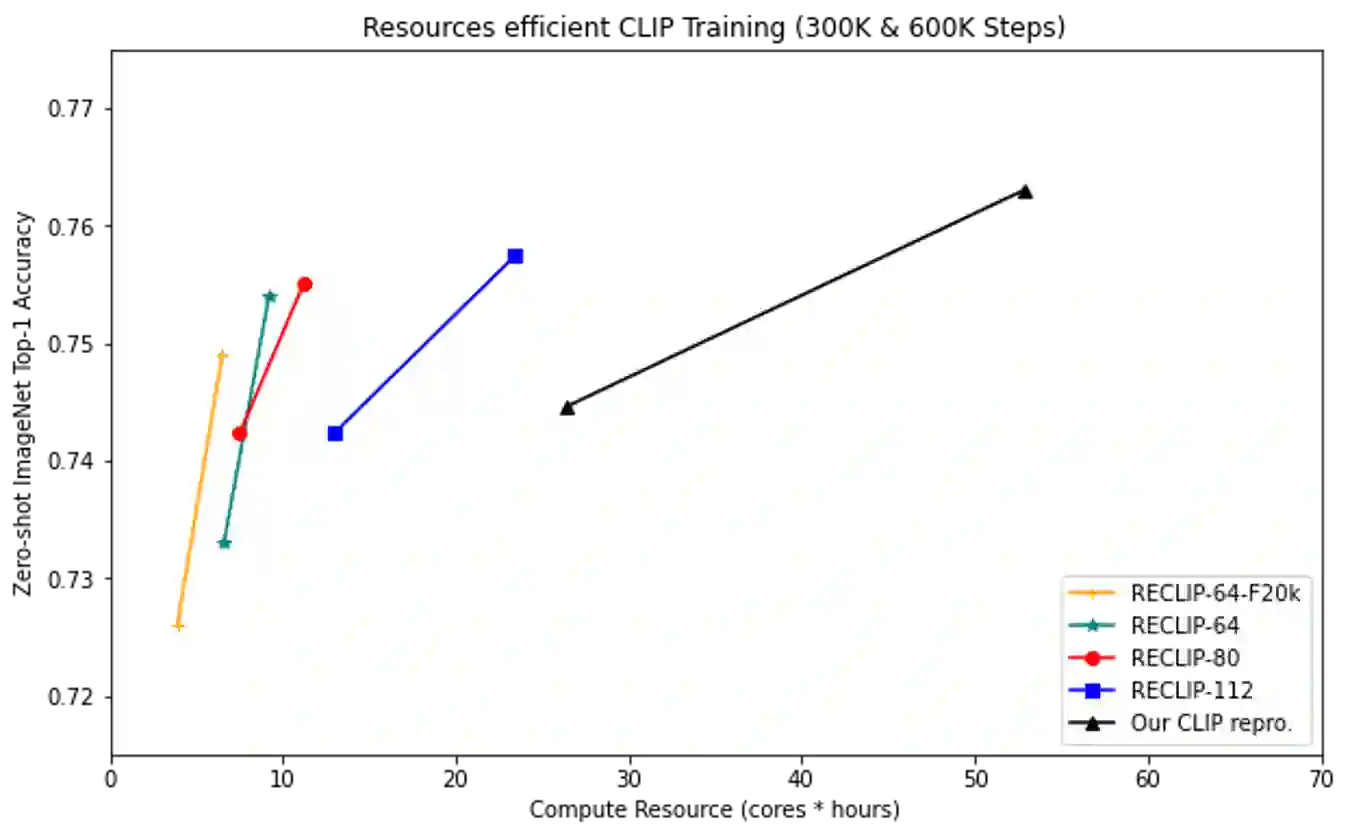
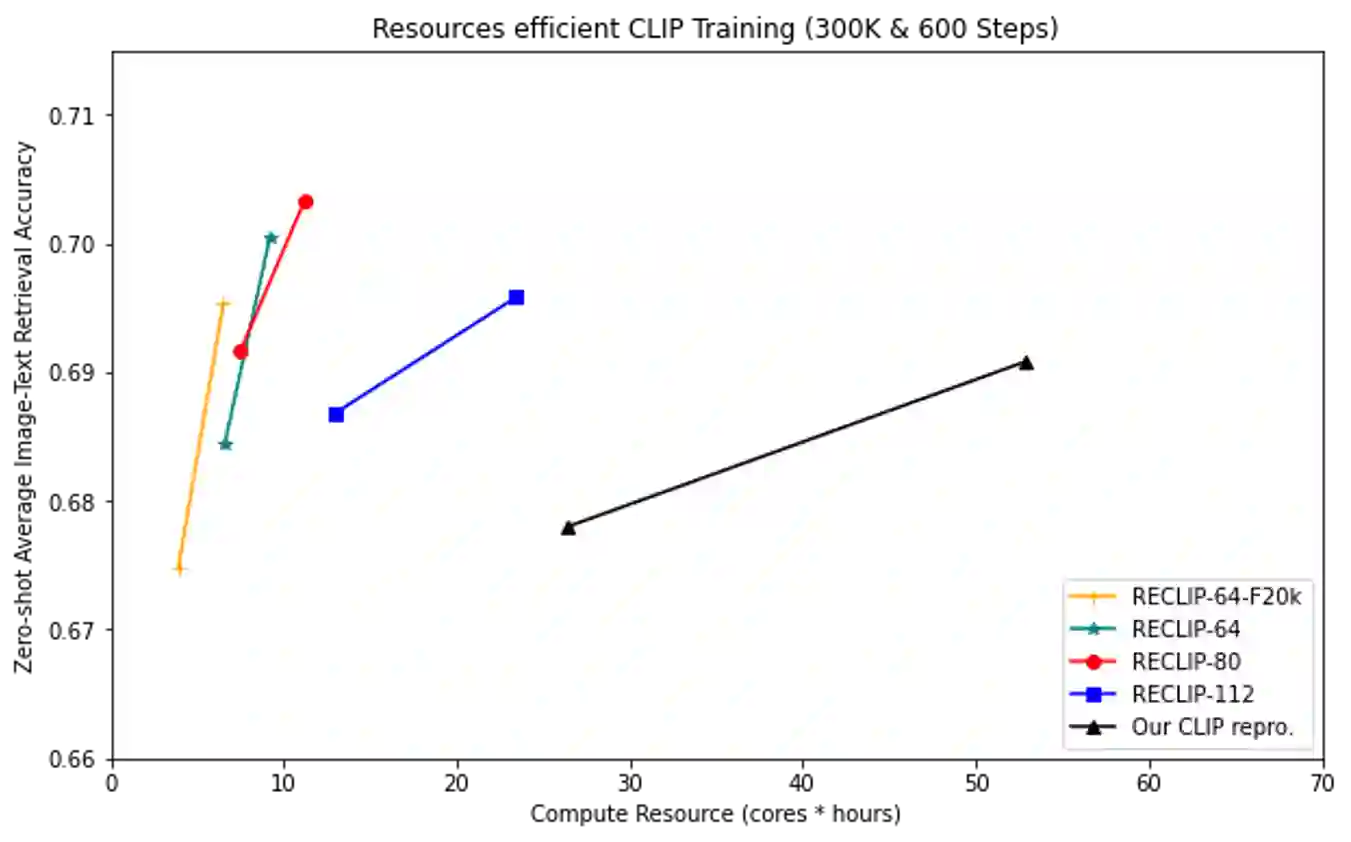
We present RECLIP (Resource-efficient CLIP), a simple method that minimizes computational resource footprint for CLIP (Contrastive Language Image Pretraining). Inspired by the notion of coarse-to-fine in computer vision, we leverage small images to learn from large-scale language supervision efficiently, and finetune the model with high-resolution data in the end. Since the complexity of the vision transformer heavily depends on input image size, our approach significantly reduces the training resource requirements both in theory and in practice. Using the same batch size and training epoch, RECLIP achieves highly competitive zero-shot classification and image text retrieval accuracy with 6 to 8$\times$ less computational resources and 7 to 9$\times$ fewer FLOPs than the baseline. Compared to the state-of-the-art contrastive learning methods, RECLIP demonstrates 5 to 59$\times$ training resource savings while maintaining highly competitive zero-shot classification and retrieval performance. We hope this work will pave the path for the broader research community to explore language supervised pretraining in more resource-friendly settings.
翻译:我们提出了RECLIP(资源高效CLIP),这是一种简单的方法,可以最小化对CLIP(对比语言图像预训练)的计算资源要求。受计算机视觉中粗略到精细的概念启发,我们利用小图像以高效地从大规模语义监督中学习,并最终使用高分辨率数据微调模型。由于视觉变换器的复杂性严重依赖于输入图像的大小,因此我们的方法在理论和实践中都显着降低了训练资源需求。使用相同的批次大小和训练时期,RECLIP以6-8倍的计算资源和7-9倍的FLOPs比基线实现了极具竞争力的零次分类和图像文本检索准确性。与最先进的对比学习方法相比,RECLIP表现出5-59倍的训练资源节省,同时保持极具竞争力的零次分类和检索性能。我们希望这项工作将为更加资源友好的环境下探索语言监督预训练为更广泛的研究社区铺平道路。