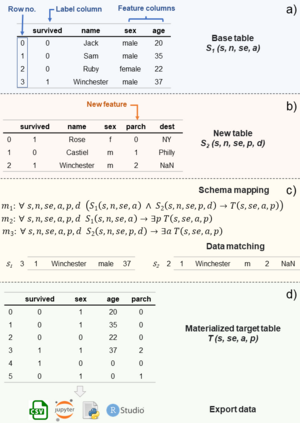
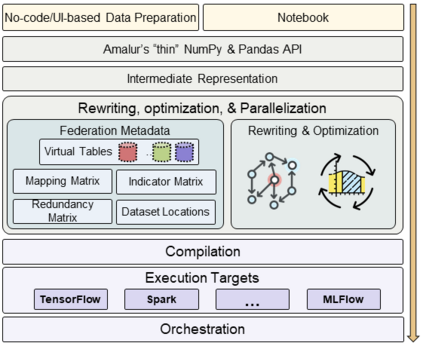
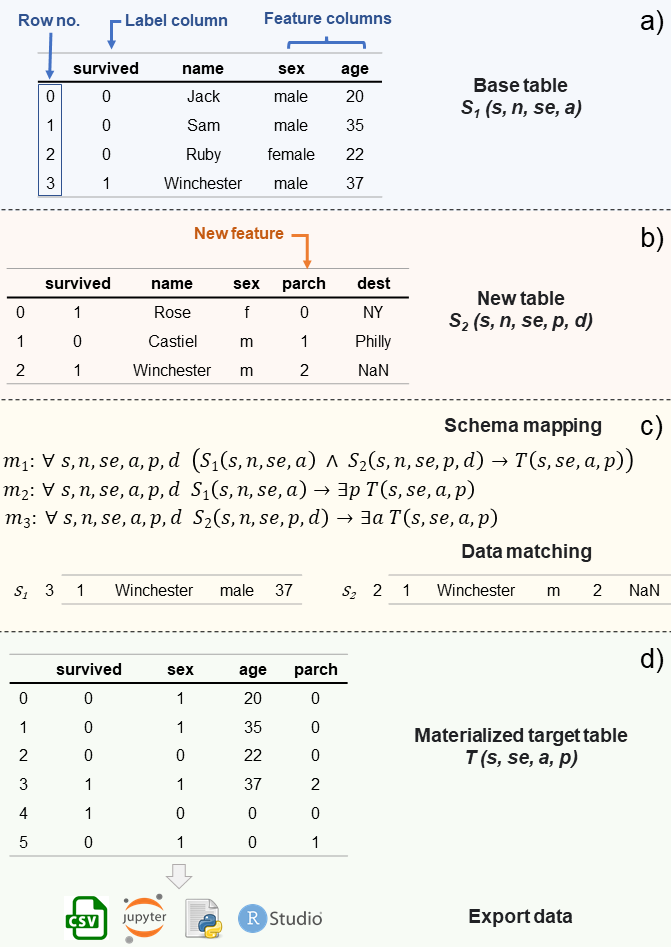
The data needed for machine learning (ML) model training and inference, can reside in different separate sites often termed data silos. For data-intensive ML applications, data silos present a major challenge: the integration and transformation of data, demand a lot of manual work and computational resources. Sometimes, data cannot leave the local store, and the model has to be trained in a decentralized manner. In this work, we propose three matrix-based dataset relationship representations, which bridge the classical data integration (DI) techniques with the requirements of modern machine learning. We discuss how those matrices pave the path for utilizing DI formalisms and techniques for our vision of ML optimization and automation over data silos.
翻译:机器学习(ML)模型培训和推断所需的数据可以存放在不同不同的地点,通常称为数据筒仓。对于数据密集的 ML 应用程序,数据仓是一个重大挑战:数据的整合和转换,需要大量的手工工作和计算资源。有时,数据不能离开本地仓库,模型必须分散培训。在这项工作中,我们提议三个基于矩阵的数据集关系表,将传统数据集成(DI)技术与现代机器学习要求连接起来。我们讨论这些矩阵如何铺设道路,利用数据筒仓的形式主义和技术实现数据筒仓的优化和自动化。