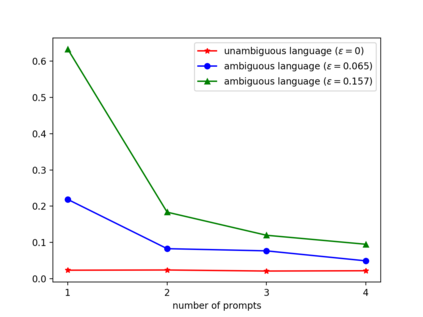
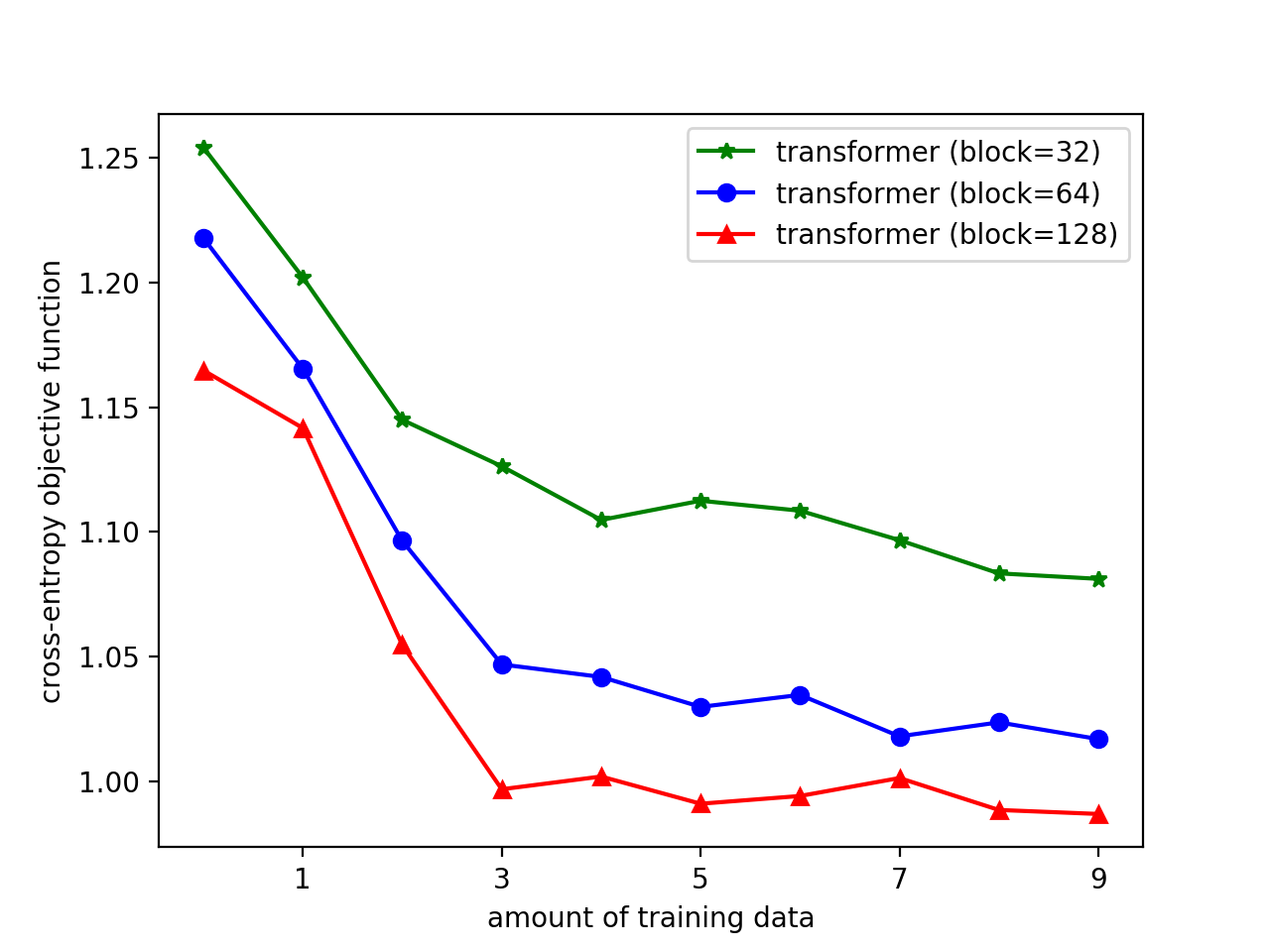
Languages are not created randomly but rather to communicate information. There is a strong association between languages and their underlying meanings, resulting in a sparse joint distribution that is heavily peaked according to their correlations. Moreover, these peak values happen to match with the marginal distribution of languages due to the sparsity. With the advent of LLMs trained on big data and large models, we can now precisely assess the marginal distribution of languages, providing a convenient means of exploring the sparse structures in the joint distribution for effective inferences. In this paper, we categorize languages as either unambiguous or {\epsilon}-ambiguous and present quantitative results to demonstrate that the emergent abilities of LLMs, such as language understanding, in-context learning, chain-of-thought prompting, and effective instruction fine-tuning, can all be attributed to Bayesian inference on the sparse joint distribution of languages.
翻译:暂无翻译