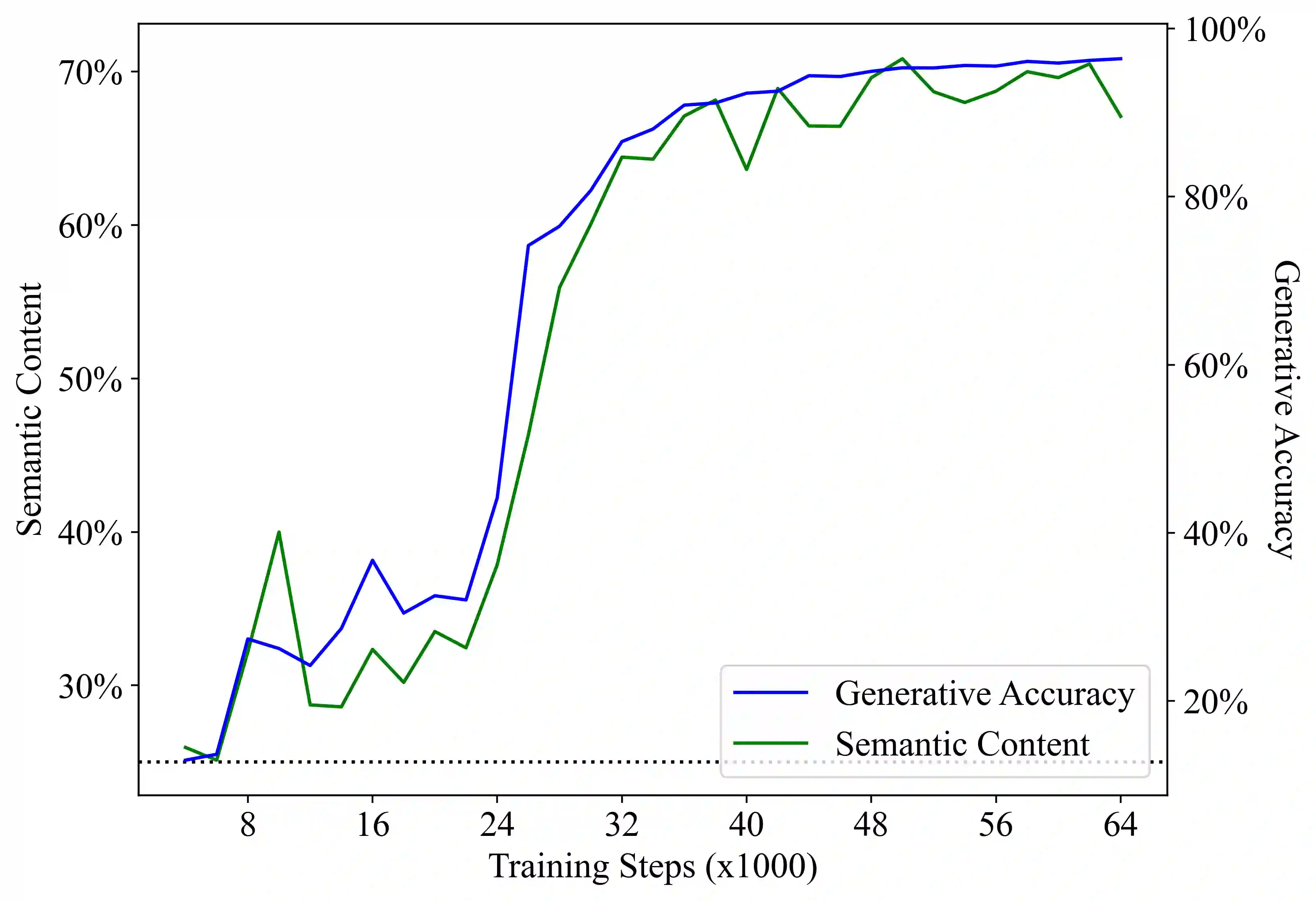
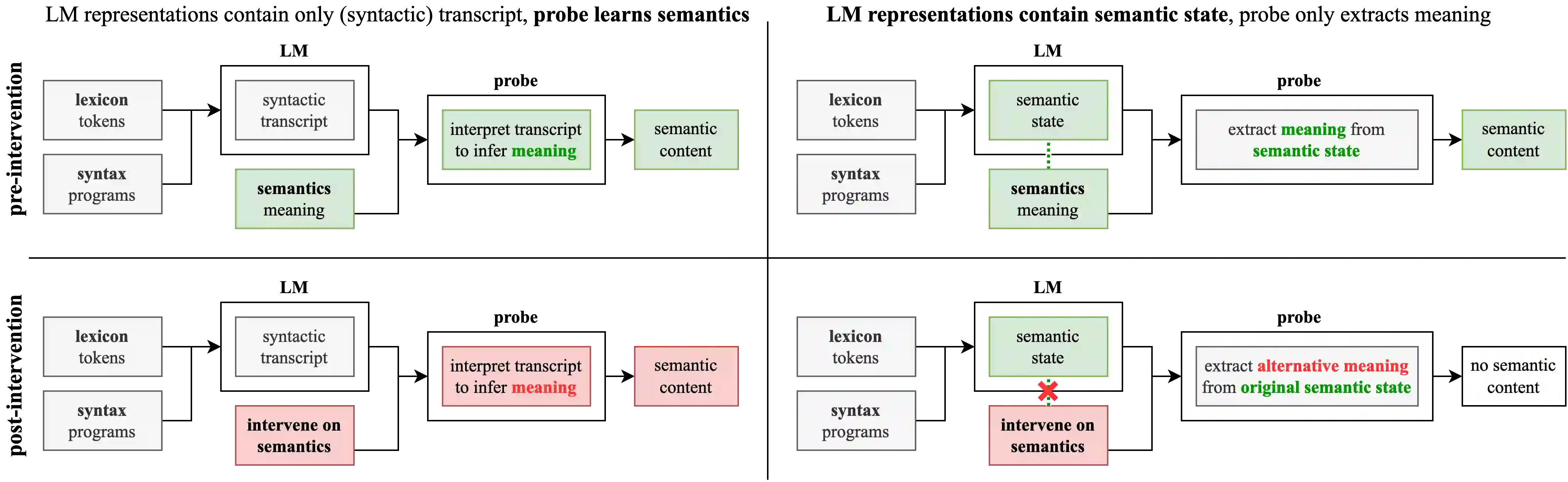
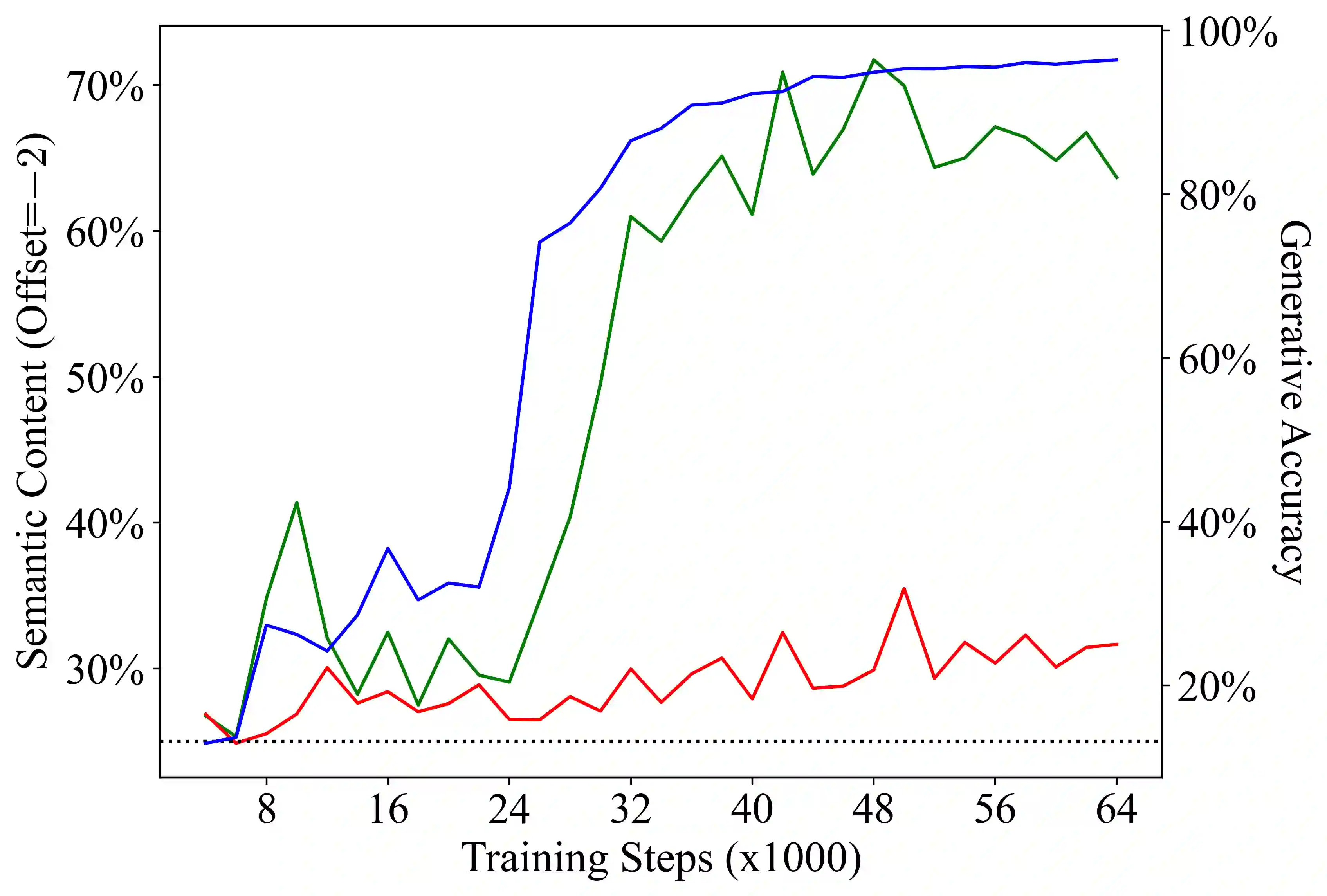
We present evidence that language models can learn meaning despite being trained only to perform next token prediction on text, specifically a corpus of programs. Each program is preceded by a specification in the form of (textual) input-output examples. Working with programs enables us to precisely define concepts relevant to meaning in language (e.g., correctness and semantics), making program synthesis well-suited as an intermediate testbed for characterizing the presence (or absence) of meaning in language models. We first train a Transformer model on the corpus of programs, then probe the trained model's hidden states as it completes a program given a specification. Despite providing no inductive bias toward learning the semantics of the language, we find that a linear probe is able to extract abstractions of both current and future program states from the model states. Moreover, there is a strong, statistically significant correlation between the accuracy of the probe and the model's ability to generate a program that implements the specification. To evaluate whether the semantics are represented in the model states rather than learned by the probe, we design a novel experimental procedure that intervenes on the semantics of the language while preserving the lexicon and syntax. We also demonstrate that the model learns to generate correct programs that are, on average, shorter than those in the training set, which is evidence that language model outputs may differ from the training distribution in semantically meaningful ways. In summary, this paper does not propose any new techniques for training language models, but develops an experimental framework for and provides insights into the acquisition and representation of (formal) meaning in language models.
翻译:暂无翻译