
The purpose of the research is to determine if currently available self-supervised learning techniques can accomplish human level comprehension of visual images using the same degree and amount of sensory input that people acquire from. Initial research on this topic solely considered data volume scaling. Here, we scale both the volume of data and the quality of the image. This scaling experiment is a self-supervised learning method that may be done without any outside financing. We find that scaling up data volume and picture resolution at the same time enables human-level item detection performance at sub-human sizes.We run a scaling experiment with vision transformers trained on up to 200000 images up to 256 ppi.
翻译:暂无翻译
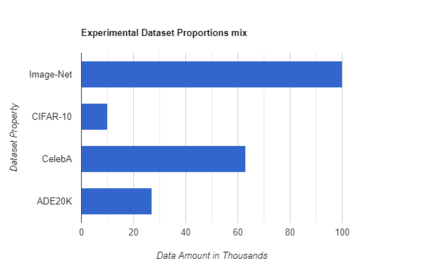
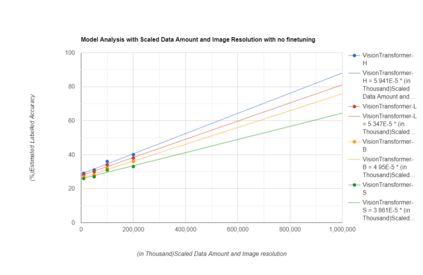
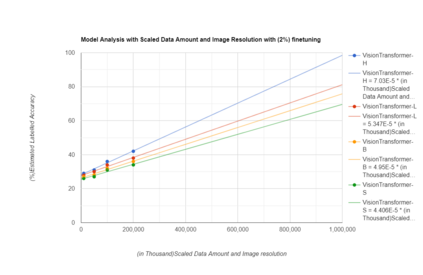
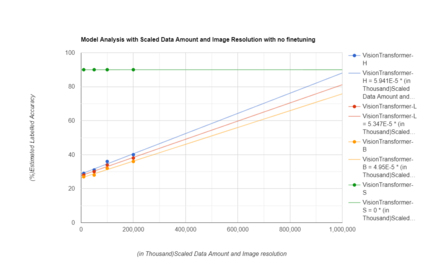
相关内容

专知会员服务
36+阅读 · 2019年10月17日
Arxiv
0+阅读 · 2023年9月28日
Arxiv
0+阅读 · 2023年9月26日

相关VIP内容
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文
Arxiv
0+阅读 · 2023年9月28日
Arxiv
0+阅读 · 2023年9月26日