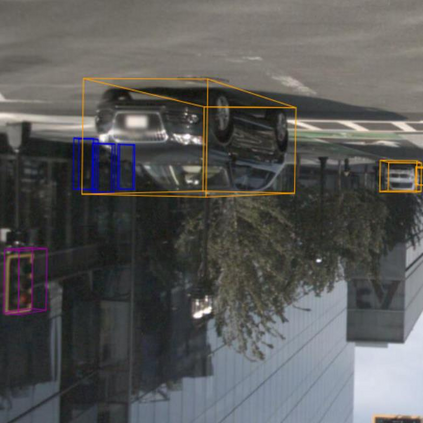
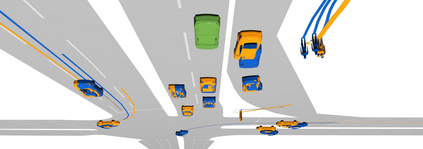
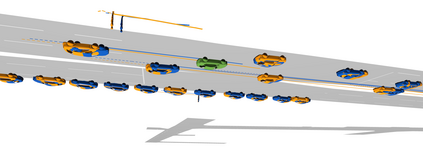
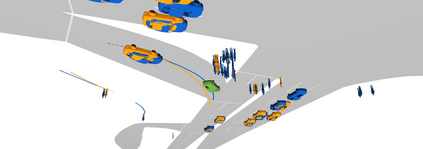
Existing autonomous driving pipelines separate the perception module from the prediction module. The two modules communicate via hand-picked features such as agent boxes and trajectories as interfaces. Due to this separation, the prediction module only receives partial information from the perception module. Even worse, errors from the perception modules can propagate and accumulate, adversely affecting the prediction results. In this work, we propose ViP3D, a visual trajectory prediction pipeline that leverages the rich information from raw videos to predict future trajectories of agents in a scene. ViP3D employs sparse agent queries throughout the pipeline, making it fully differentiable and interpretable. Furthermore, we propose an evaluation metric for this novel end-to-end visual trajectory prediction task. Extensive experimental results on the nuScenes dataset show the strong performance of ViP3D over traditional pipelines and previous end-to-end models.
翻译:现有的自主驱动管道将感知模块与预测模块分开。 两个模块通过人工选择的特征(如代理箱和作为界面的轨迹)进行沟通。 由于这种分离,预测模块只能从感知模块获得部分信息。 更糟糕的是,感知模块的错误会传播和累积,对预测结果产生不利影响。 在这项工作中,我们提议ViP3D, 一种视觉轨迹预测管道,利用原始视频的丰富信息预测现场物剂的未来轨迹。 ViP3D在整个管道中都使用稀疏的物剂查询,使其完全可以区分和解释。 此外,我们提议了一个新颖的端到端视觉轨迹预测任务的评价指标。 NuScens数据集的广泛实验结果显示VP3D对传统管道和以前的端到端模型的强劲表现。