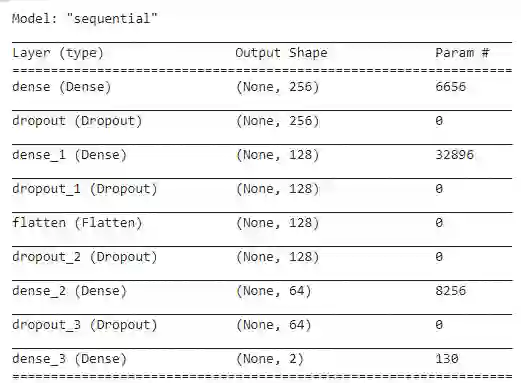
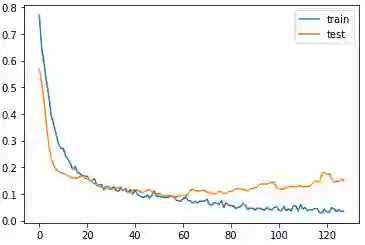
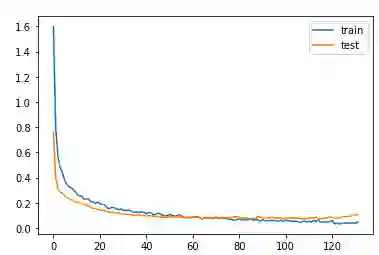
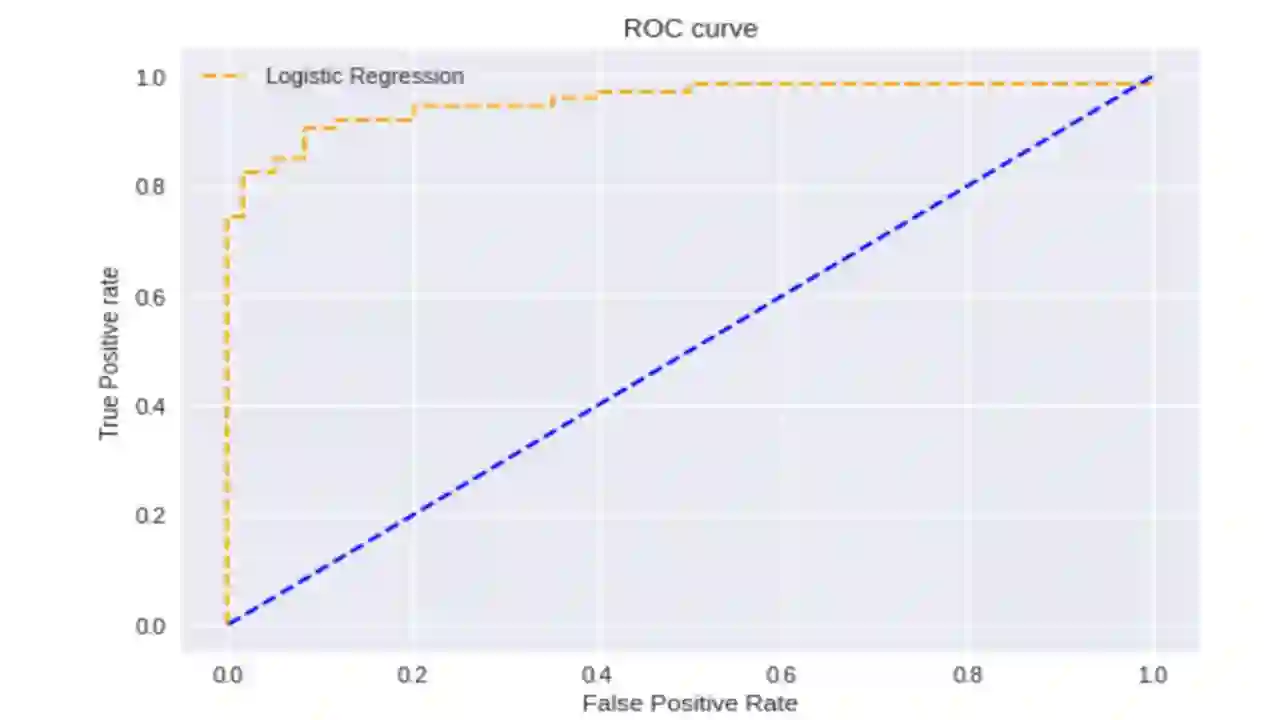
Audio is one of the most used way of human communication, but at the same time it can be easily misused by to trick people. With the revolution of AI, the related technologies are now accessible to almost everyone thus making it simple for the criminals to commit crimes and forgeries. In this work, we introduce a deep learning method to develop a classifier that will blindly classify an input audio as real or mimicked. The proposed model was trained on a set of important features extracted from a large dataset of audios to get a classifier that was tested on the same set of features from different audios. Two datasets were created for this work; an all English data set and a mixed data set (Arabic and English). These datasets have been made available through GitHub for the use of the research community at https://github.com/SaSs7/Dataset. For the purpose of comparison, the audios were also classified through human inspection with the subjects being the native speakers. The ensued results were interesting and exhibited formidable accuracy.
翻译:音频是人类最常用的通信方式之一,但与此同时,它很容易被人们误用。随着AI的革命,相关的技术现在几乎每个人都可以使用,从而使罪犯犯罪和伪造的罪犯简单易行。在这项工作中,我们引入了一种深层次的学习方法来开发一个分类器,将输入的音频盲目地归类为真实的或仿制的。提议的模式在从大量音频数据集提取的一套重要特征上进行了培训,以获得一个分类器,该分类器在不同音频的同一组特征上进行了测试。为这项工作创建了两套数据集;所有英国数据集和混合数据集(阿拉伯文和英文)。这些数据集通过GitHub提供,供https://github.com/SaS7/Dataset的研究界使用。为了比较的目的,这些音频也通过人类检查分类,主题是当地语者。随后的结果令人感兴趣,并表现出惊人的准确性。