
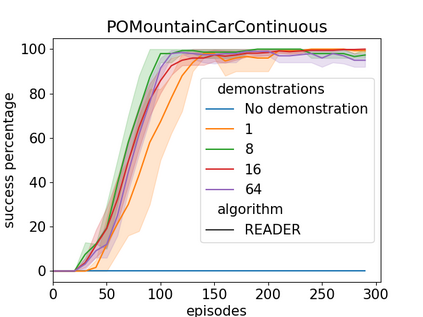
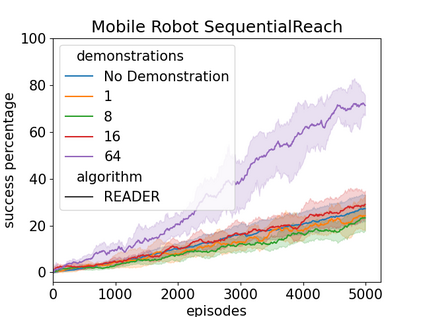
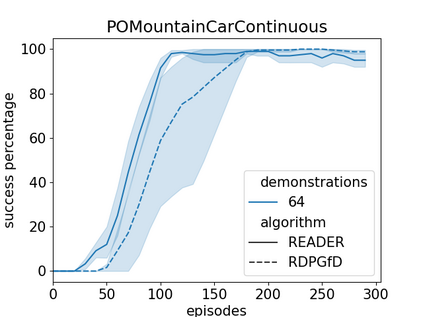
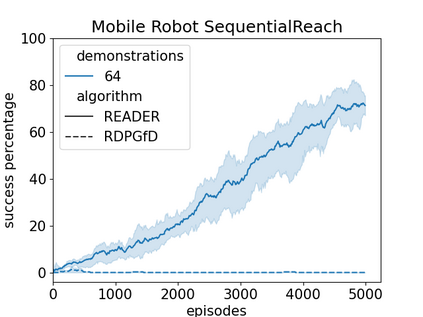
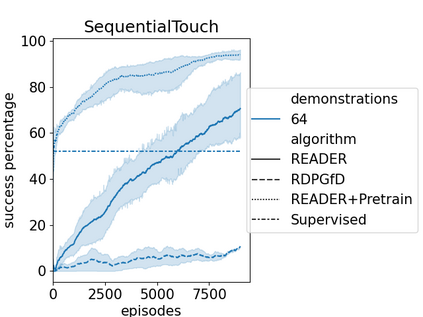
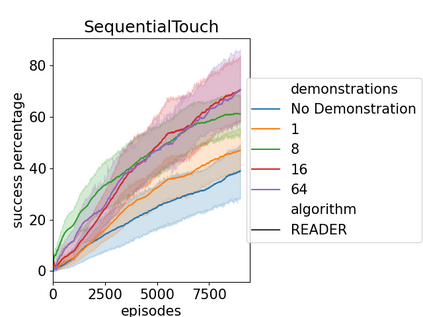
Efficient exploration has presented a long-standing challenge in reinforcement learning, especially when rewards are sparse. A developmental system can overcome this difficulty by learning from both demonstrations and self-exploration. However, existing methods are not applicable to most real-world robotic controlling problems because they assume that environments follow Markov decision processes (MDP); thus, they do not extend to partially observable environments where historical observations are necessary for decision making. This paper builds on the idea of replaying demonstrations for memory-dependent continuous control, by proposing a novel algorithm, Recurrent Actor-Critic with Demonstration and Experience Replay (READER). Experiments involving several memory-crucial continuous control tasks reveal significantly reduce interactions with the environment using our method with a reasonably small number of demonstration samples. The algorithm also shows better sample efficiency and learning capabilities than a baseline reinforcement learning algorithm for memory-based control from demonstrations.
翻译:有效探索在强化学习方面是一个长期的挑战,特别是在奖励很少的情况下,发展系统可以通过学习示范和自我探索来克服这一困难;然而,现有方法不适用于大多数真实世界的机器人控制问题,因为它们假定环境遵循Markov(MDP)的决定程序;因此,这些方法并不延伸到需要历史观察才能作出决定的部分可观测环境;本文件基于重播示范以记忆为依存的持续控制的想法,提出了一种新奇的算法,即经常的Actor-Critical与演示和经验再演(READER),涉及若干需要记忆的连续控制任务的实验表明,利用我们的方法与数量相当少的示范样本,大大减少了与环境的相互作用;算法还显示了比从演示中控制记忆的基线强化学习算法更好的抽样效率和学习能力。



相关内容

Source: Apple - iOS 8

