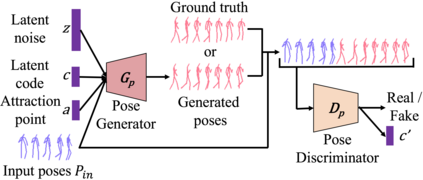
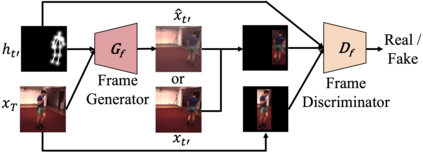
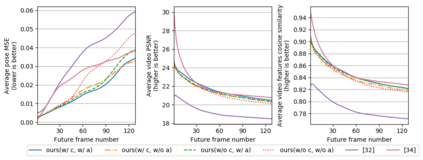
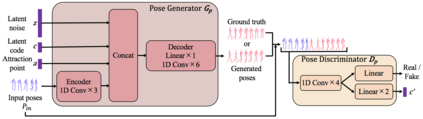
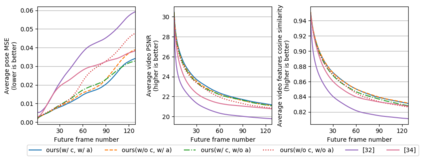
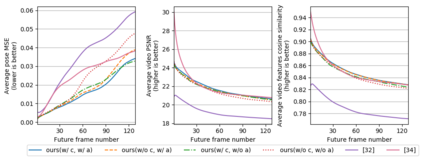
Predicting future human behavior from an input human video is a useful task for applications such as autonomous driving and robotics. While most previous works predict a single future, multiple futures with different behavior can potentially occur. Moreover, if the predicted future is too short (e.g., less than one second), it may not be fully usable by a human or other systems. In this paper, we propose a novel method for future human pose prediction capable of predicting multiple long-term futures. This makes the predictions more suitable for real applications. Also, from the input video and the predicted human behavior, we generate future videos. First, from an input human video, we generate sequences of future human poses (i.e., the image coordinates of their body-joints) via adversarial learning. Adversarial learning suffers from mode collapse, which makes it difficult to generate a variety of multiple poses. We solve this problem by utilizing two additional inputs to the generator to make the outputs diverse, namely, a latent code (to reflect various behaviors) and an attraction point (to reflect various trajectories). In addition, we generate long-term future human poses using a novel approach based on unidimensional convolutional neural networks. Last, we generate an output video based on the generated poses for visualization. We evaluate the generated future poses and videos using three criteria (i.e., realism, diversity and accuracy), and show that our proposed method outperforms other state-of-the-art works.
翻译:从输入的人类视频中预测未来人类行为对于自主驱动和机器人等应用来说是一项有用的任务。 虽然大多数前几部作品预测了一个单一的未来, 但不同行为的多重未来可能会发生。 此外, 如果预测的未来太短( 不到一秒), 人类或其他系统可能无法充分利用它。 在本文中, 我们为未来人类构成预测提出一种新的方法, 能够预测多种长期未来。 这样, 预测更适合真实应用。 此外, 通过输入的视频和预测的人类行为, 我们生成未来视频。 首先, 通过输入的人类视频, 我们生成未来人类姿势的序列( 即其身体- 连接的图像坐标) 。 反versarial 学习会受到模式崩溃的困扰, 从而难以产生多种组合。 我们通过对发电机的额外投入来解决这个问题, 使产出多样化, 即隐性代码( 反映各种行为) 和吸引点( 反映各种轨迹 ) 。 此外, 我们通过对抗性的研究, 将未来视觉的网络 形成一个基于我们所生成的视觉模式 。