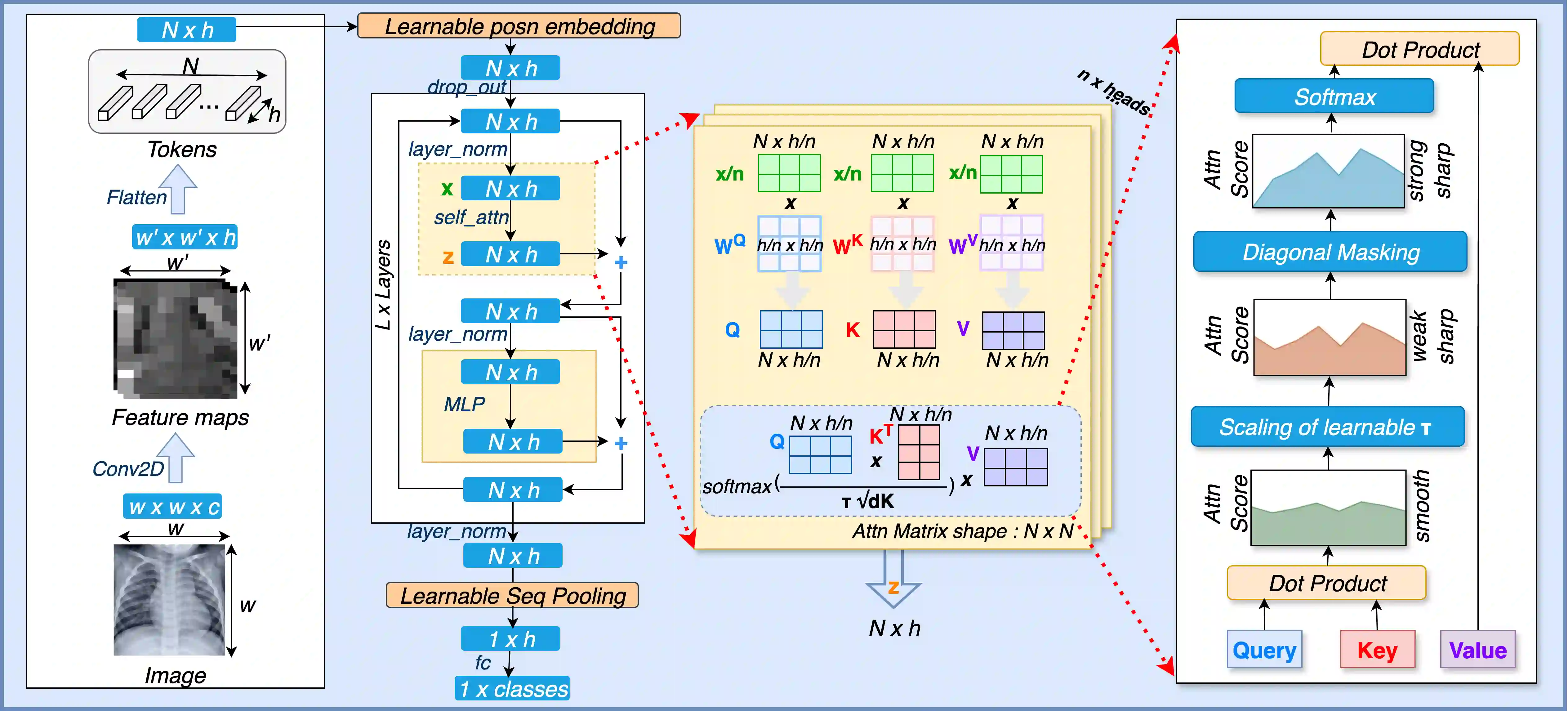
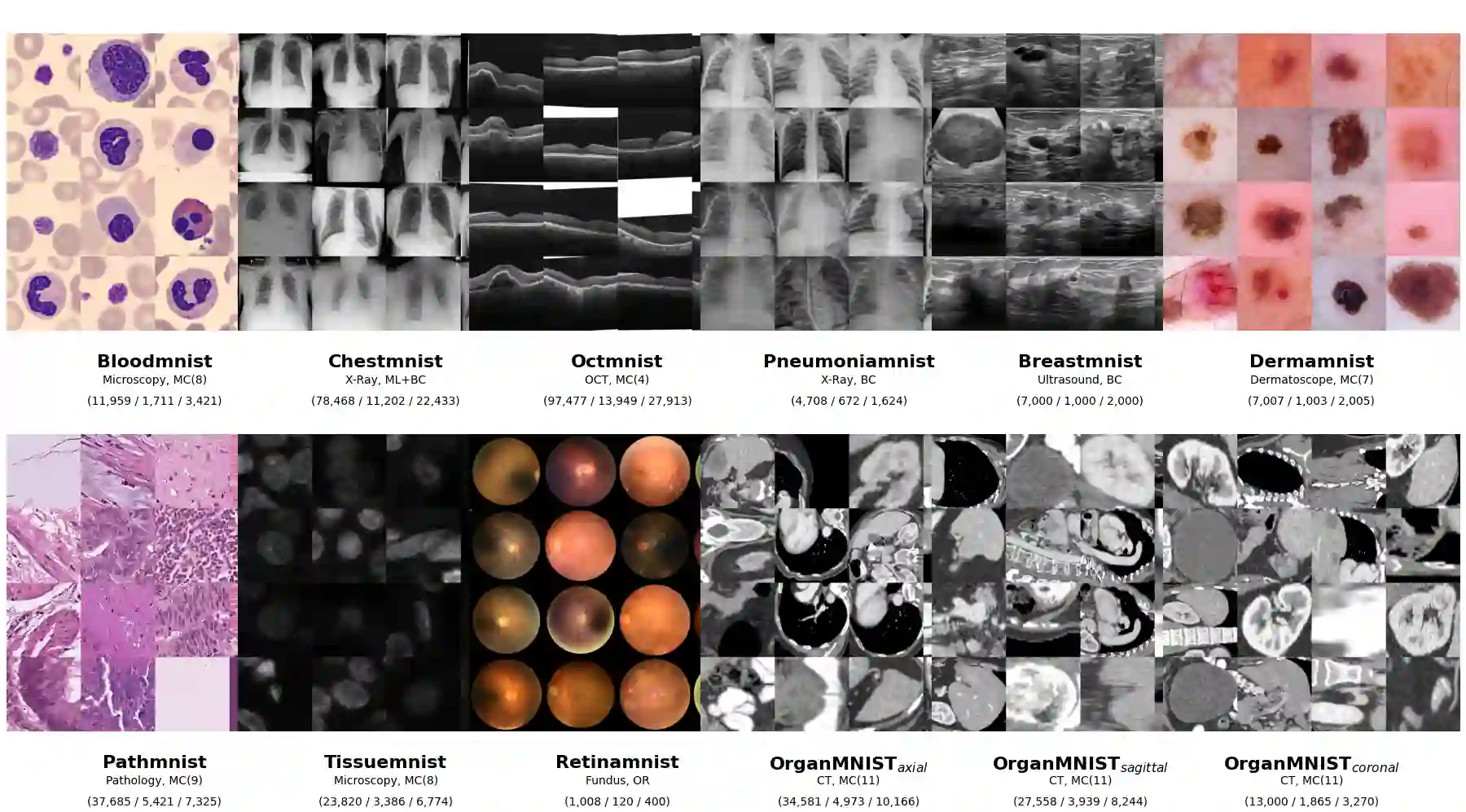
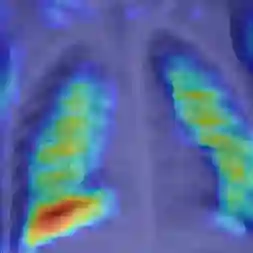
Vision Transformers (ViTs) have demonstrated strong potential in medical imaging; however, their high computational demands and tendency to overfit on small datasets limit their applicability in real-world clinical scenarios. In this paper, we present CoMViT, a compact and generalizable Vision Transformer architecture optimized for resource-constrained medical image analysis. CoMViT integrates a convolutional tokenizer, diagonal masking, dynamic temperature scaling, and pooling-based sequence aggregation to improve performance and generalization. Through systematic architectural optimization, CoMViT achieves robust performance across twelve MedMNIST datasets while maintaining a lightweight design with only ~4.5M parameters. It matches or outperforms deeper CNN and ViT variants, offering up to 5-20x parameter reduction without sacrificing accuracy. Qualitative Grad-CAM analyses show that CoMViT consistently attends to clinically relevant regions despite its compact size. These results highlight the potential of principled ViT redesign for developing efficient and interpretable models in low-resource medical imaging settings.
翻译:视觉Transformer(ViT)在医学影像领域已展现出强大潜力;然而,其高计算需求及在小数据集上易过拟合的特性限制了其在真实临床场景中的应用。本文提出CoMViT,一种专为资源受限的医学影像分析优化的紧凑且泛化能力强的视觉Transformer架构。CoMViT整合了卷积分词器、对角掩码、动态温度缩放及基于池化的序列聚合机制,以提升性能与泛化能力。通过系统性的架构优化,CoMViT在十二个MedMNIST数据集上实现了鲁棒性能,同时保持仅约450万参数的轻量化设计。其性能匹配或超越更深层的CNN及ViT变体,在保持精度不损失的前提下实现了高达5至20倍的参数量缩减。定性的Grad-CAM分析表明,尽管模型尺寸紧凑,CoMViT仍能持续关注临床相关区域。这些结果凸显了基于原则的ViT重新设计在低资源医学影像场景中开发高效可解释模型的潜力。