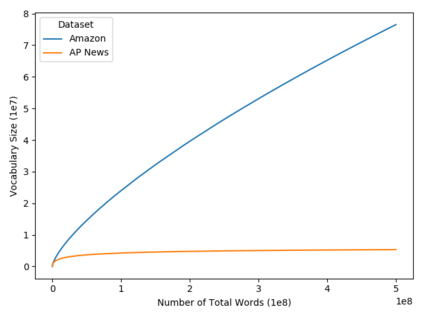
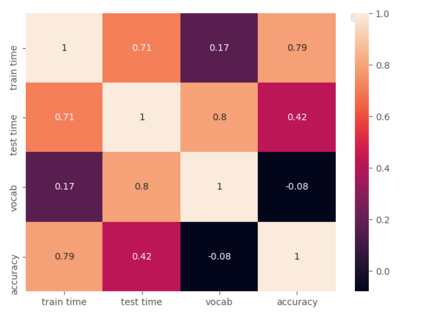
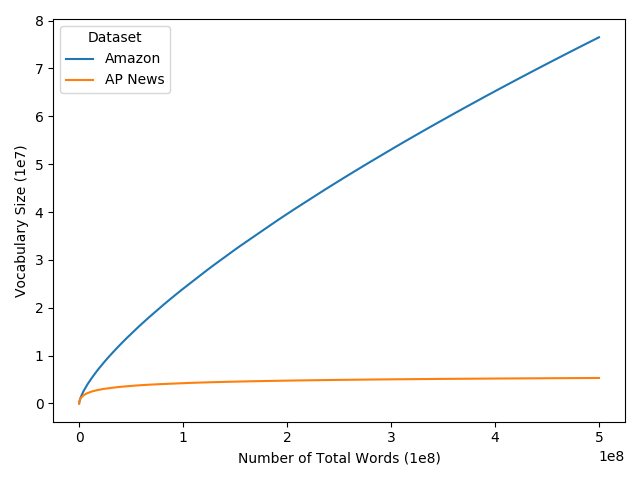
Text classification is a significant branch of natural language processing, and has many applications including document classification and sentiment analysis. Unsurprisingly, those who do text classification are concerned with the run-time of their algorithms, many of which depend on the size of the corpus' vocabulary due to their bag-of-words representation. Although many studies have examined the effect of preprocessing techniques on vocabulary size and accuracy, none have examined how these methods affect a model's run-time. To fill this gap, we provide a comprehensive study that examines how preprocessing techniques affect the vocabulary size, model performance, and model run-time, evaluating ten techniques over four models and two datasets. We show that some individual methods can reduce run-time with no loss of accuracy, while some combinations of methods can trade 2-5% of the accuracy for up to a 65% reduction of run-time. Furthermore, some combinations of preprocessing techniques can even provide a 15% reduction in run-time while simultaneously improving model accuracy.
翻译:文本分类是自然语言处理的一个重要分支,它有许多应用,包括文件分类和情绪分析。 毫不奇怪,那些进行文本分类的人关心其算法的运行时间,其中许多由于其一袋字的表达方式而取决于本体词汇的大小。虽然许多研究都审查了预处理技术对词汇大小和准确性的影响,但没有一项研究研究这些方法如何影响模型的运行时间。为了填补这一空白,我们提供了一项全面研究,研究预处理技术如何影响词汇大小、模型性能和模型运行时间,对四个模型和两个数据集的十种技术进行评估。我们表明,有些单个方法可以减少运行时间,而不会失去准确性,而一些方法组合可以将精度的2%-5%用于降低运行时间的65%。此外,一些预处理技术组合甚至可以减少运行时间的15%,同时提高模型的准确性。