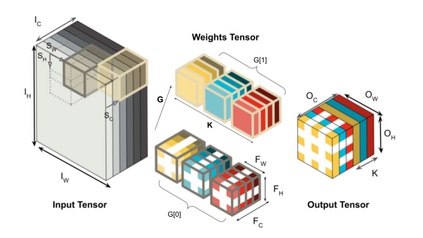
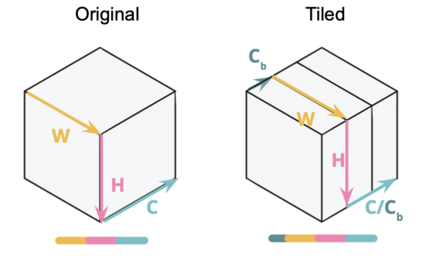
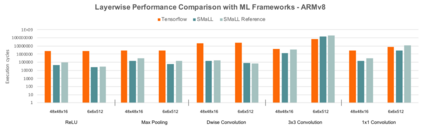
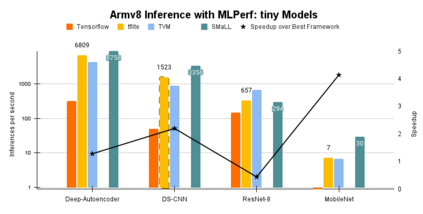
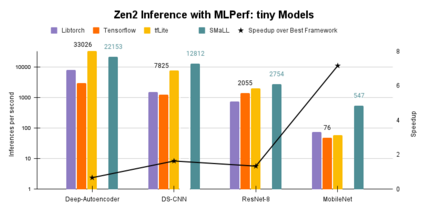
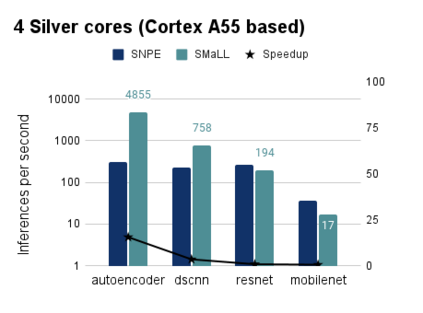
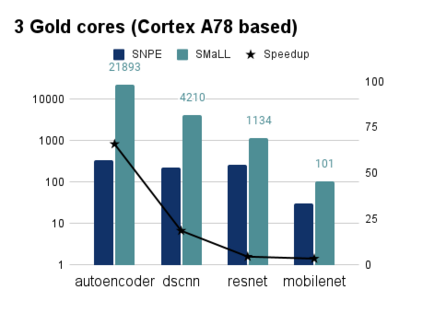
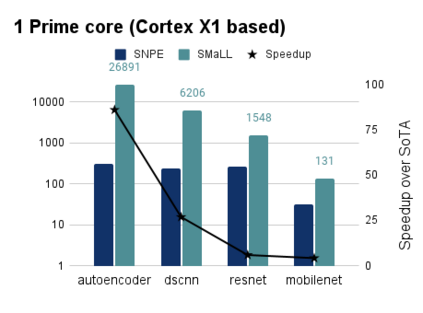
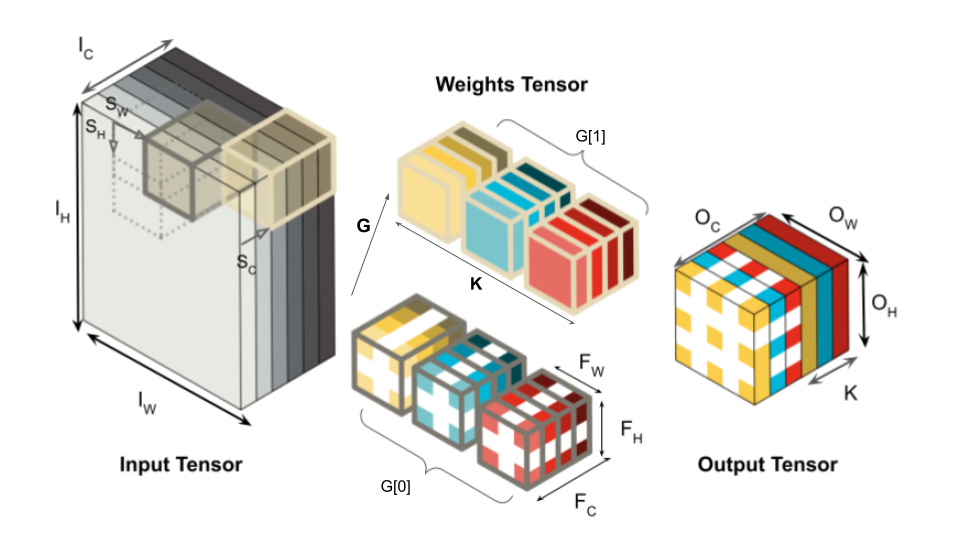
Interest in deploying Deep Neural Network (DNN) inference on edge devices has resulted in an explosion of the number and types of hardware platforms to use. While the high-level programming interface, such as TensorFlow, can be readily ported across different devices, high-performance inference implementations rely on a good mapping of the high-level interface to the target hardware platform. Commonly, this mapping may use optimizing compilers to generate code at compile time or high-performance vendor libraries that have been specialized to the target platform. Both approaches rely on expert knowledge to produce the mapping, which may be time-consuming and difficult to extend to new architectures. In this work, we present a DNN library framework, SMaLL, that is easily extensible to new architectures. The framework uses a unified loop structure and shared, cache-friendly data format across all intermediate layers, eliminating the time and memory overheads incurred by data transformation between layers. Layers are implemented by simply specifying the layer's dimensions and a kernel -- the key computing operations of each layer. The unified loop structure and kernel abstraction allows us to reuse code across layers and computing platforms. New architectures only require the 100s of lines in the kernel to be redesigned. To show the benefits of our approach, we have developed software that supports a range of layer types and computing platforms, which is easily extensible for rapidly instantiating high performance DNN libraries. We evaluate our software by instantiating networks from the TinyMLPerf benchmark suite on 5 ARM platforms and 1 x86 platform ( an AMD Zen 2). Our framework shows end-to-end performance that is comparable to or better than ML Frameworks such as TensorFlow, TVM and LibTorch.
翻译:在边缘设备上部署深神经网络(DNN) 的兴趣推算, 导致要使用的硬件平台的数量和类型爆炸。 虽然TensorFlow等高级编程界面可以在不同的设备中轻易移植, 但高性能推导执行取决于目标硬件平台的高级界面的妥善映射。 通常, 此映射可能利用优化编译器在编译时生成代码, 或为目标平台专门设计的高性能供应商图书馆。 两种方法都依靠专家知识来生成映射, 可能耗时且难以扩展至新架构。 在这项工作中, 我们推出一个 DNNNT 库图书馆框架, SMaLL, 很容易扩展到新结构。 框架使用统一的环形结构, 共享、 缓存方便的数据格式, 消除各层之间数据转换产生的时间和记忆管理。 层的实施方式是简单地指定层的尺寸和内核 -- 每一层的关键计算操作。 只有统一的环流结构和内存式服务器, 才能让我们在高级平台上重新使用可比较的代码, 显示我们的直径平台 。</s>