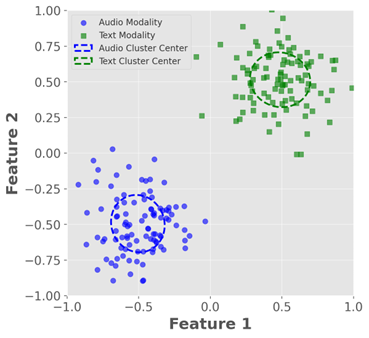
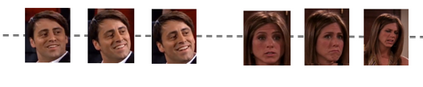
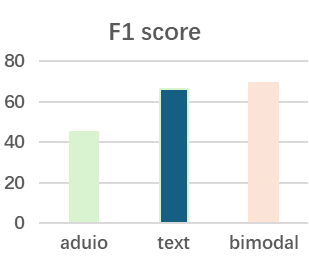
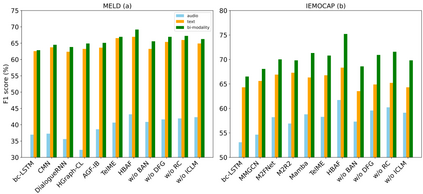
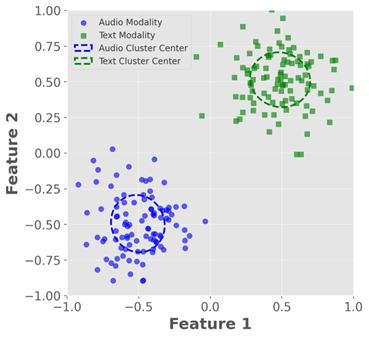
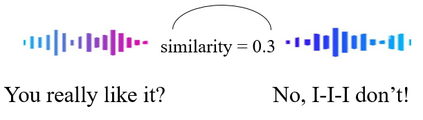Multi-modal emotion recognition in conversations is a challenging problem due to the complex and complementary interactions between different modalities. Audio and textual cues are particularly important for understanding emotions from a human perspective. Most existing studies focus on exploring interactions between audio and text modalities at the same representation level. However, a critical issue is often overlooked: the heterogeneous modality gap between low-level audio representations and high-level text representations. To address this problem, we propose a novel framework called Heterogeneous Bimodal Attention Fusion (HBAF) for multi-level multi-modal interaction in conversational emotion recognition. The proposed method comprises three key modules: the uni-modal representation module, the multi-modal fusion module, and the inter-modal contrastive learning module. The uni-modal representation module incorporates contextual content into low-level audio representations to bridge the heterogeneous multi-modal gap, enabling more effective fusion. The multi-modal fusion module uses dynamic bimodal attention and a dynamic gating mechanism to filter incorrect cross-modal relationships and fully exploit both intra-modal and inter-modal interactions. Finally, the inter-modal contrastive learning module captures complex absolute and relative interactions between audio and text modalities. Experiments on the MELD and IEMOCAP datasets demonstrate that the proposed HBAF method outperforms existing state-of-the-art baselines.
翻译:暂无翻译