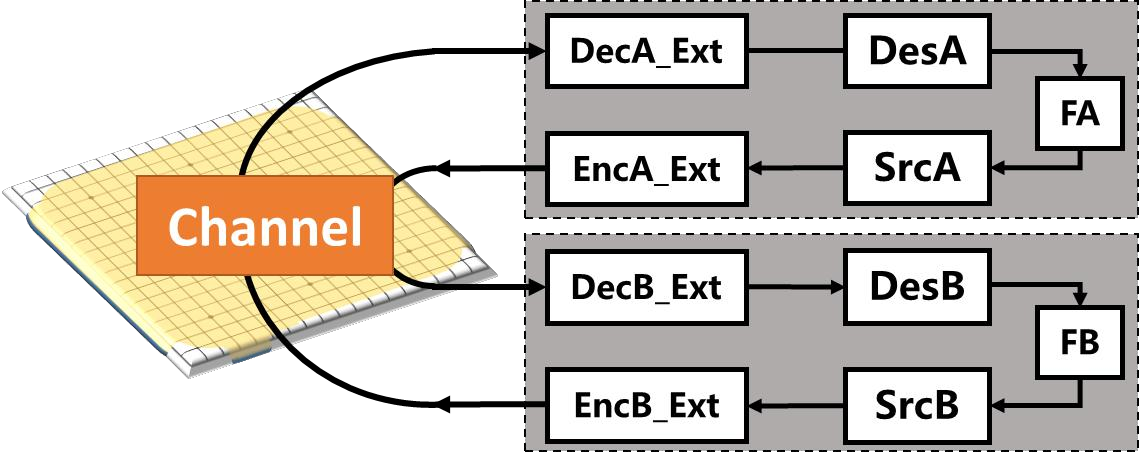
The recently released AlphaZero algorithm achieves superhuman performance in the games of chess, shogi and Go, which raises two open questions. Firstly, as there is a finite number of possibilities in the game, is there a quantifiable intelligence measurement for evaluating intelligent systems, e.g. AlphaZero? Secondly, AlphaZero introduces sophisticated reinforcement learning and self-play to efficiently encode the possible states, is there a simple information-theoretic model to represent the learning process and offer more insights in fostering strong AI systems? This paper explores the above two questions by proposing a simple variance of Shannon's communication model, the concept of intelligence entropy and the Unified Intelligence-Communication Model is proposed, which provide an information-theoretic metric for investigating the intelligence level and also provide an bound for intelligent agents in the form of Shannon's capacity, namely, the intelligence capacity. This paper then applies the concept and model to AlphaZero as a case study and explains the learning process of intelligent agent as turbo-like iterative decoding, so that the learning performance of AlphaZero may be quantitatively evaluated. Finally, conclusions are provided along with theoretical and practical remarks.
翻译:最近公布的阿尔法泽罗算法在象棋、Shogi和Go的游戏中取得了超人性表现,这引起了两个未决问题。首先,由于游戏中的可能性有限,是否有评估智能系统(如阿尔法泽罗)的量化情报测量方法?第二,阿尔法泽罗引入了精密的强化学习和自我游戏,以有效地将可能的状态编码,是否有一个简单的信息理论模型来代表学习过程,并在培养强大的AI系统方面提供更多见解?本文探讨了上述两个问题,提出了香农交流模式的简单差异,即情报信箱概念和统一情报通信模式,为调查情报水平提供了信息理论衡量标准,并以香农的能力(即情报能力)的形式为智能剂提供了约束。本文随后将阿尔法泽罗的概念和模型作为案例研究,并将智能剂的学习过程解释为涡轮式的迭代解码,因此可以对阿尔法泽罗的学习表现进行定量评估。最后,本文件提供了理论和实践性评论。