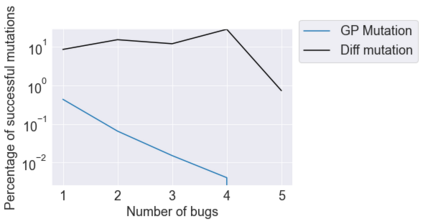
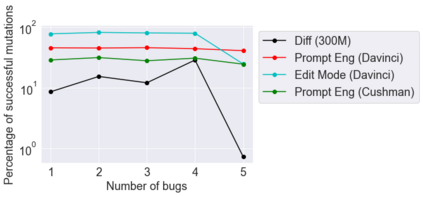
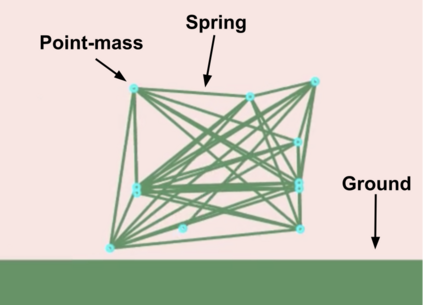
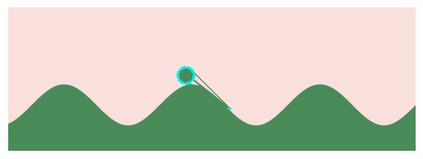
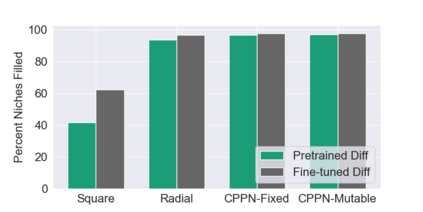
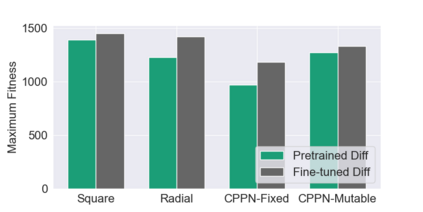
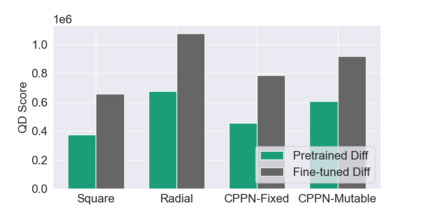
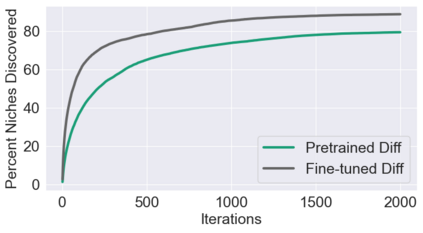
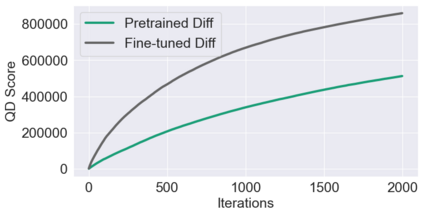
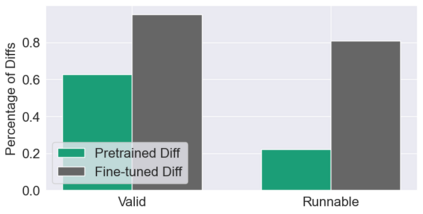
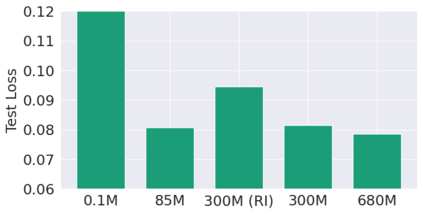
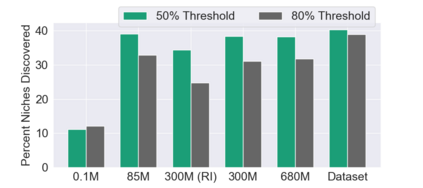
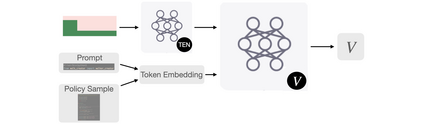
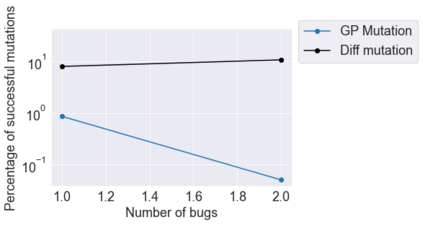
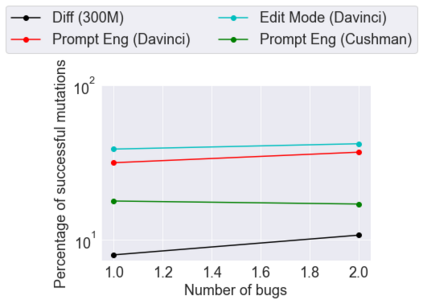
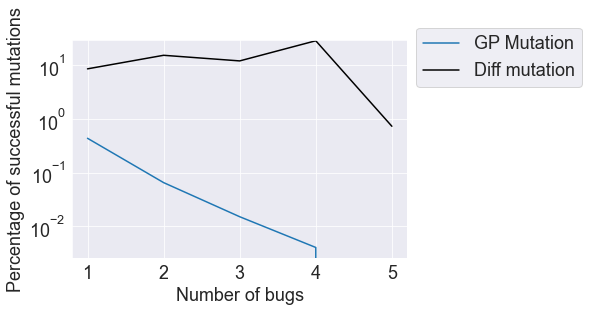
This paper pursues the insight that large language models (LLMs) trained to generate code can vastly improve the effectiveness of mutation operators applied to programs in genetic programming (GP). Because such LLMs benefit from training data that includes sequential changes and modifications, they can approximate likely changes that humans would make. To highlight the breadth of implications of such evolution through large models (ELM), in the main experiment ELM combined with MAP-Elites generates hundreds of thousands of functional examples of Python programs that output working ambulating robots in the Sodarace domain, which the original LLM had never seen in pre-training. These examples then help to bootstrap training a new conditional language model that can output the right walker for a particular terrain. The ability to bootstrap new models that can output appropriate artifacts for a given context in a domain where zero training data was previously available carries implications for open-endedness, deep learning, and reinforcement learning. These implications are explored here in depth in the hope of inspiring new directions of research now opened up by ELM.
翻译:本文深入地了解,经过培训生成代码的大型语言模型(LLMs)能够极大地提高基因程序(GP)应用的突变操作者的效力。由于这种LMs受益于包括顺序变化和修改在内的培训数据,它们可以估计人类可能做出的变化。为了突出这种演变通过大型模型(ELM)产生的广泛影响,在主要的实验ELM和MAP-Elites一起产生数十万个Python程序功能范例,在Sodarace域输出在模拟机器人中起作用的机器人,而最初的LLM在培训前从未见过这些范例。这些范例随后有助于导出一个新的有条件的语言模型,能够在特定地形上输出正确的行走器。在以前已有零培训数据的领域捕捉能够为特定环境输出适当文物的新模型的能力,对开放性、深层学习和强化学习产生了影响。在这里深入探讨这些影响,希望激发目前由ELM开启的新研究方向。