
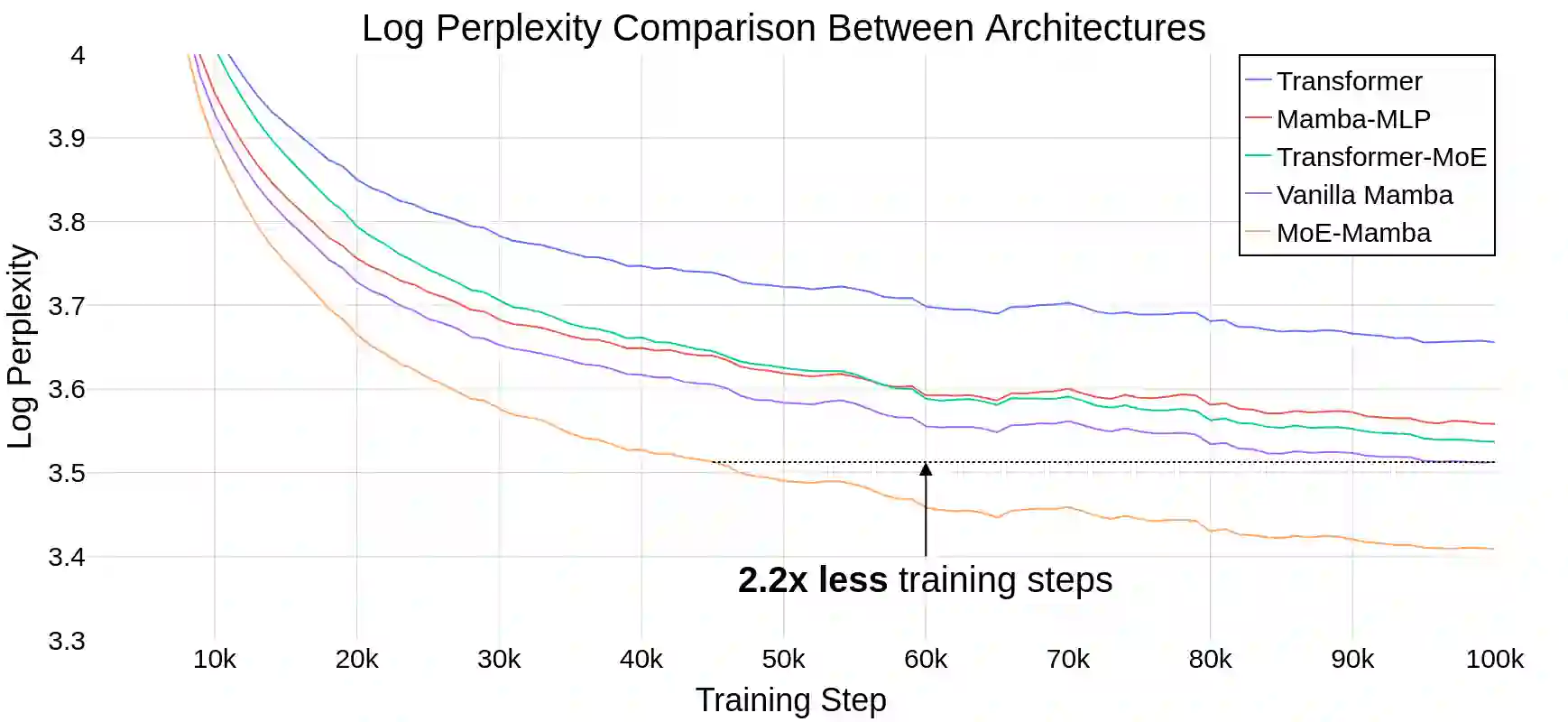
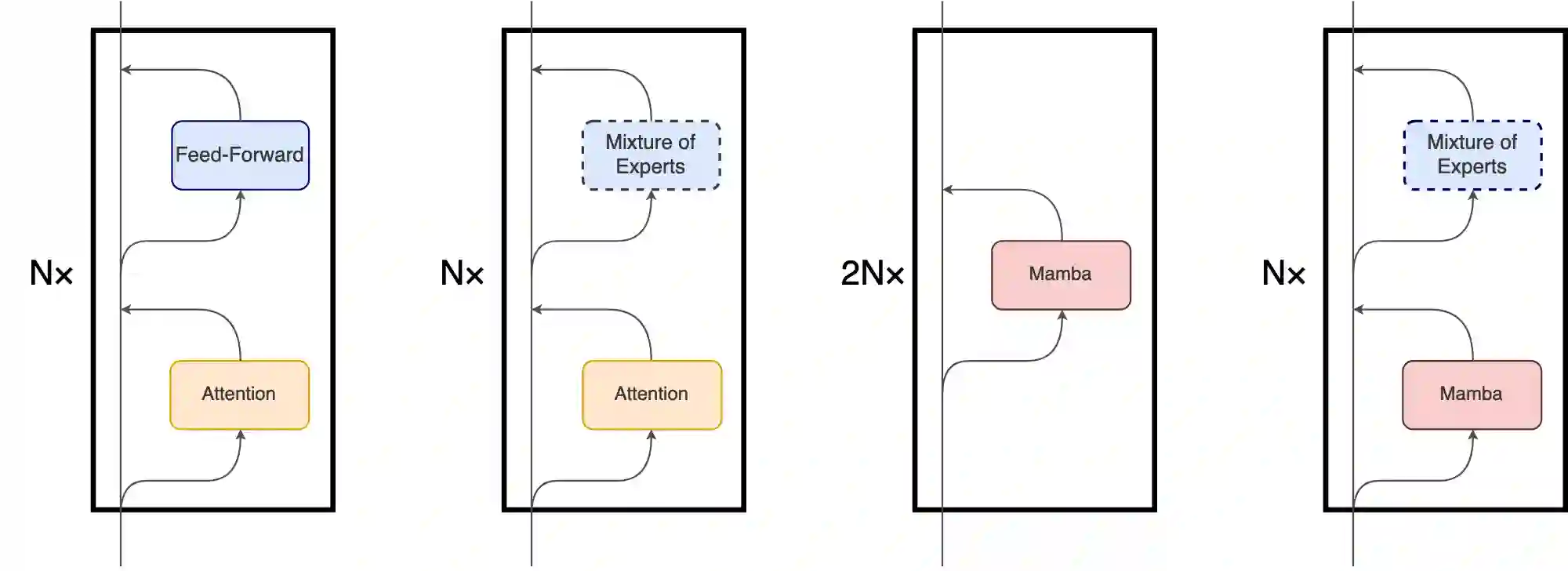
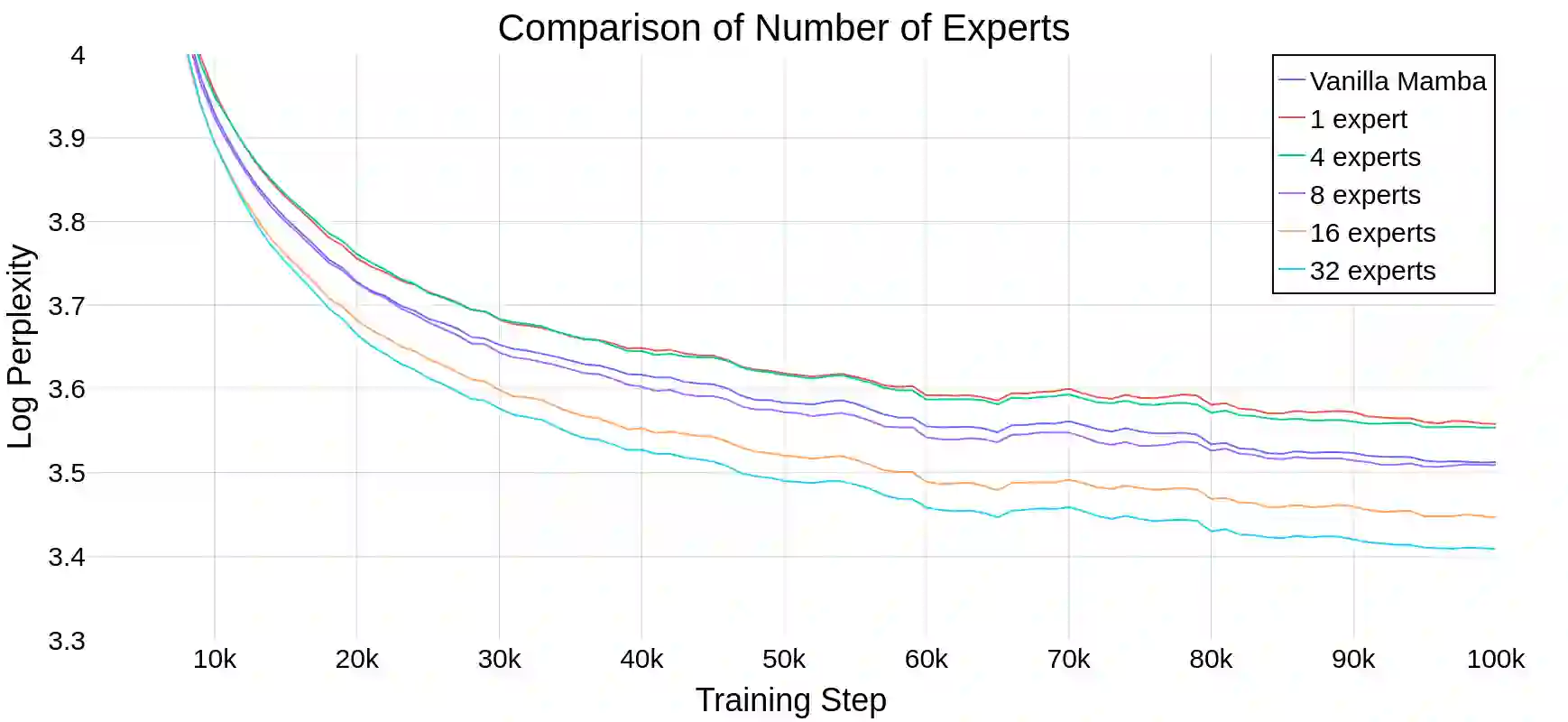
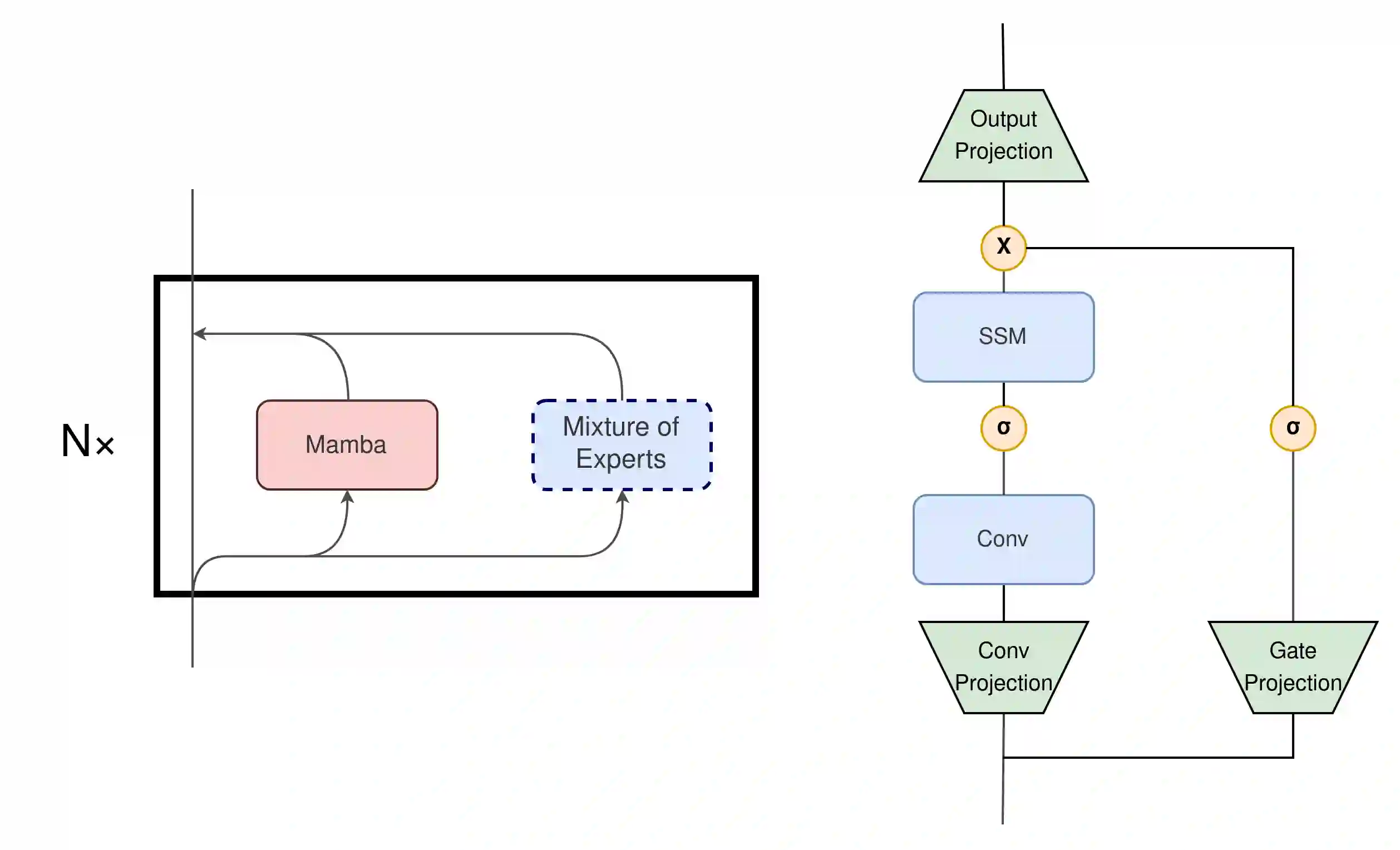
State Space Models (SSMs) have become serious contenders in the field of sequential modeling, challenging the dominance of Transformers. At the same time, Mixture of Experts (MoE) has significantly improved Transformer-based LLMs, including recent state-of-the-art open-source models. We propose that to unlock the potential of SSMs for scaling, they should be combined with MoE. We showcase this on Mamba, a recent SSM-based model that achieves remarkable, Transformer-like performance. Our model, MoE-Mamba, outperforms both Mamba and Transformer-MoE. In particular, MoE-Mamba reaches the same performance as Mamba in 2.2x less training steps while preserving the inference performance gains of Mamba against the Transformer.
翻译:暂无翻译
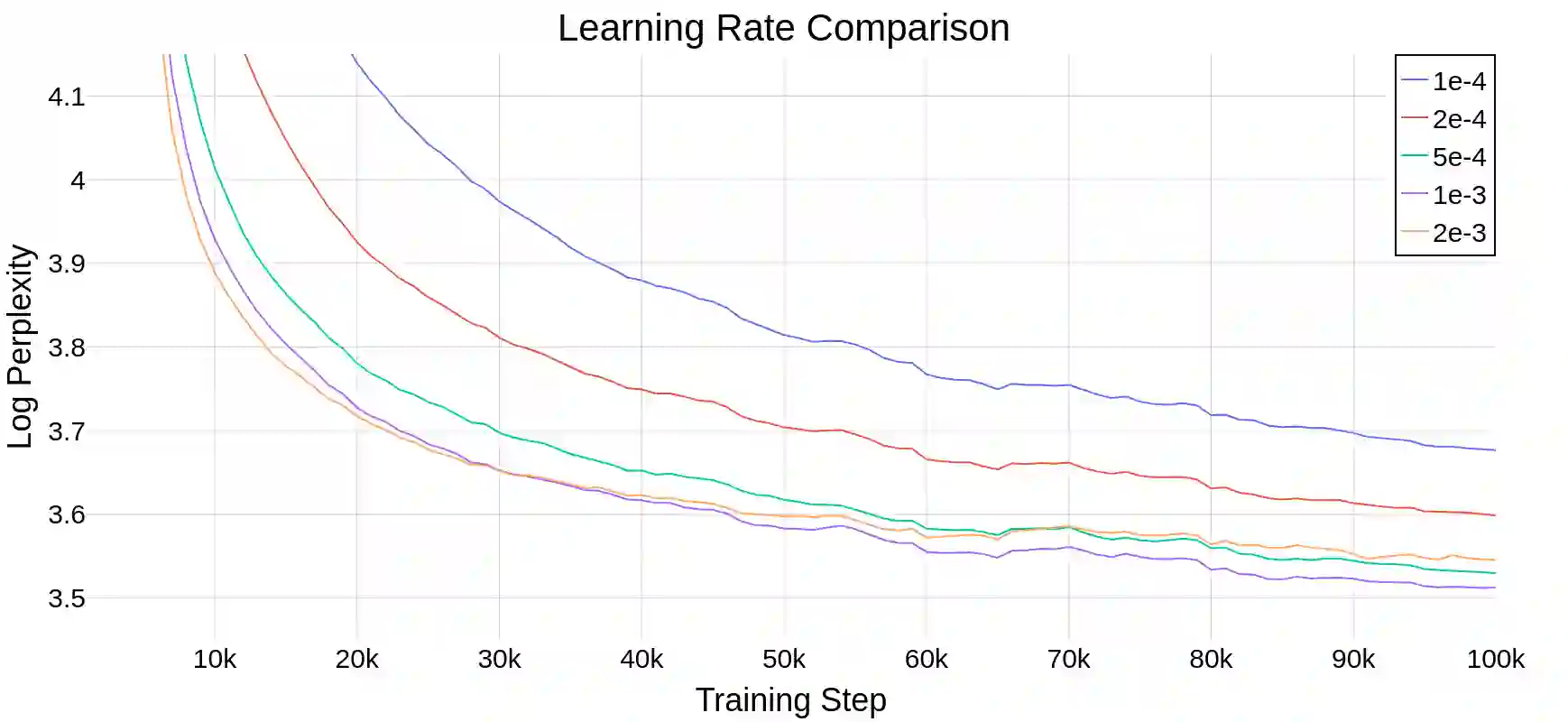
相关内容

专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
20+阅读 · 2021年5月10日

相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文
Arxiv
20+阅读 · 2021年5月10日