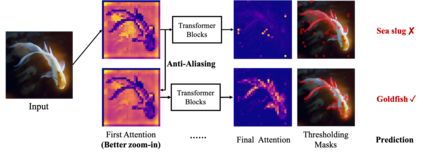
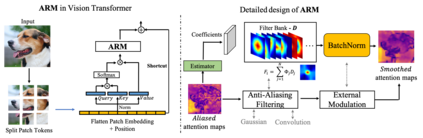
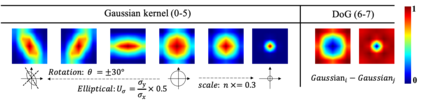
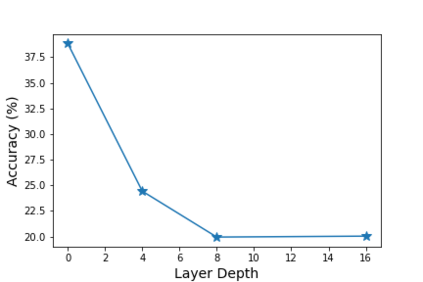
The transformer architectures, based on self-attention mechanism and convolution-free design, recently found superior performance and booming applications in computer vision. However, the discontinuous patch-wise tokenization process implicitly introduces jagged artifacts into attention maps, arising the traditional problem of aliasing for vision transformers. Aliasing effect occurs when discrete patterns are used to produce high frequency or continuous information, resulting in the indistinguishable distortions. Recent researches have found that modern convolution networks still suffer from this phenomenon. In this work, we analyze the uncharted problem of aliasing in vision transformer and explore to incorporate anti-aliasing properties. Specifically, we propose a plug-and-play Aliasing-Reduction Module(ARM) to alleviate the aforementioned issue. We investigate the effectiveness and generalization of the proposed method across multiple tasks and various vision transformer families. This lightweight design consistently attains a clear boost over several famous structures. Furthermore, our module also improves data efficiency and robustness of vision transformers.
翻译:以自我注意机制和无革命性设计为基础的变压器结构最近发现计算机视觉中的超强性能和蓬勃应用。然而,不连续的无节制象征性化过程暗含地将胡作非曲的人工制品引入关注地图,由此产生了对视觉变压器进行别名的传统问题。当使用离散模式生成高频率或连续信息,导致无法区分的扭曲时,就会产生异样效应。最近的研究发现现代变压网络仍受这一现象的影响。在这项工作中,我们分析了在视觉变压器中进行别名的未知问题,并探索了反丑化特性。具体地说,我们提议了一个插和玩的变压模块(ARM)来缓解上述问题。我们调查了多种任务和各种视觉变压器组合的拟议方法的有效性和概括性。这一轻量设计始终在几个著名结构上得到明显的提升。此外,我们的模块还提高了视觉变压器的数据效率和坚固性。