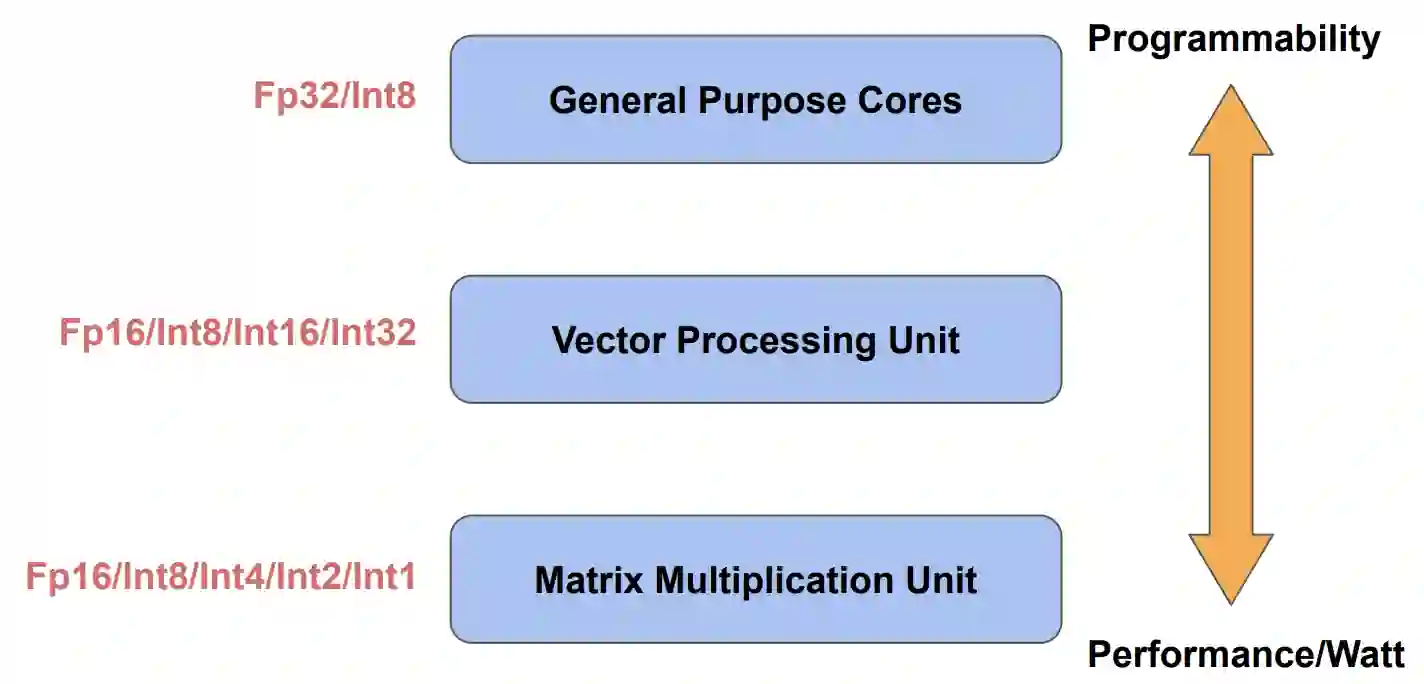
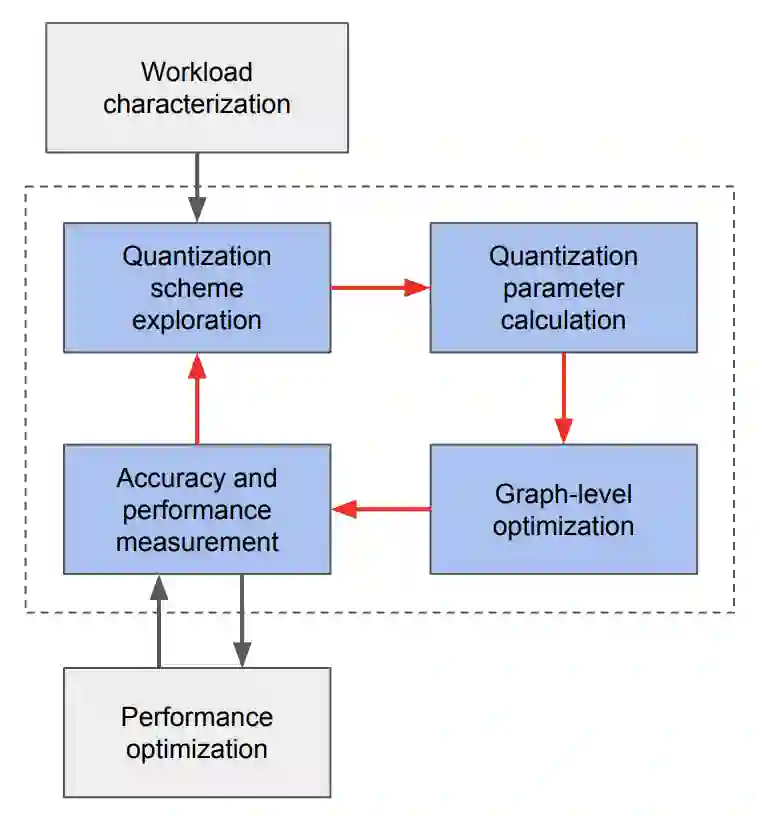
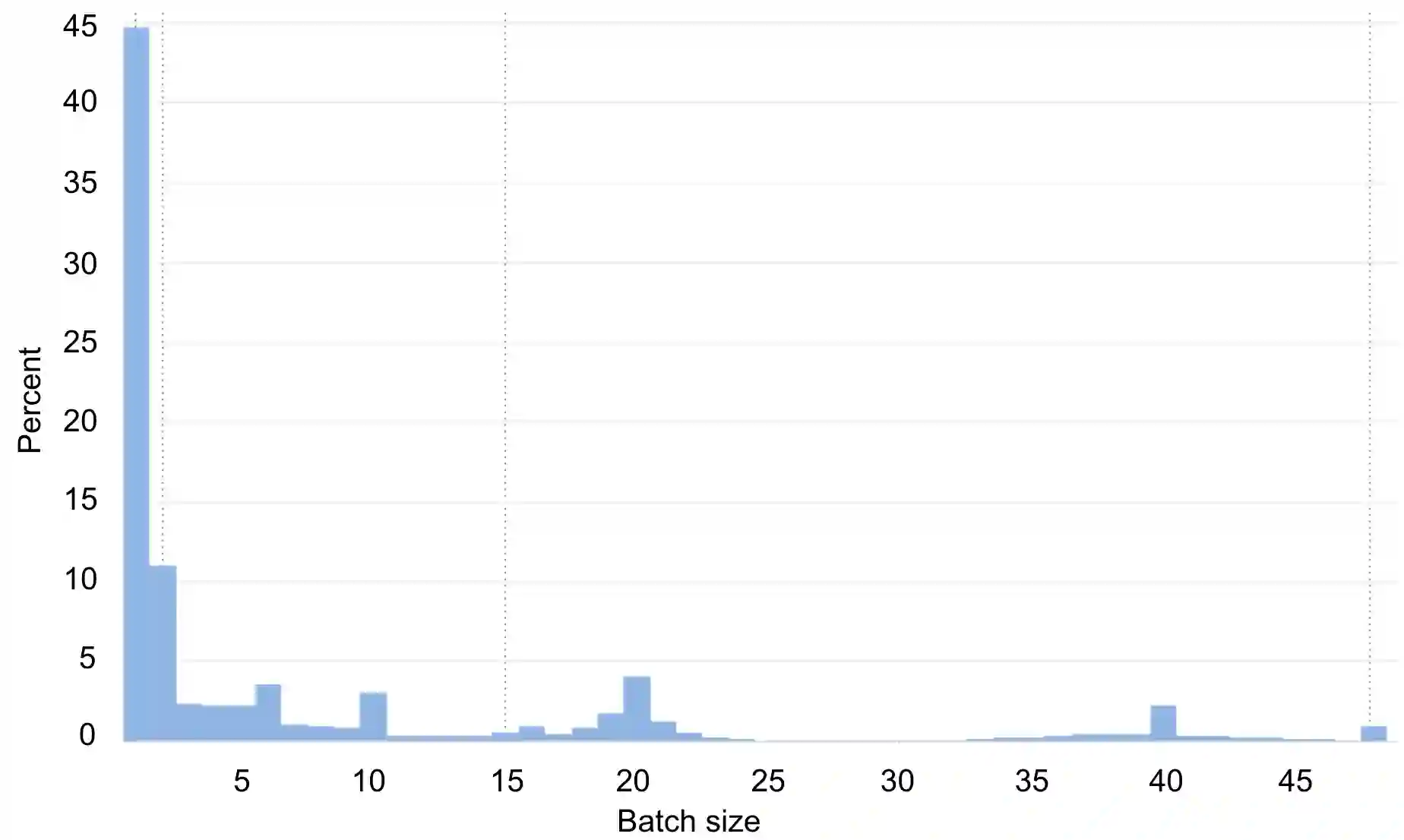
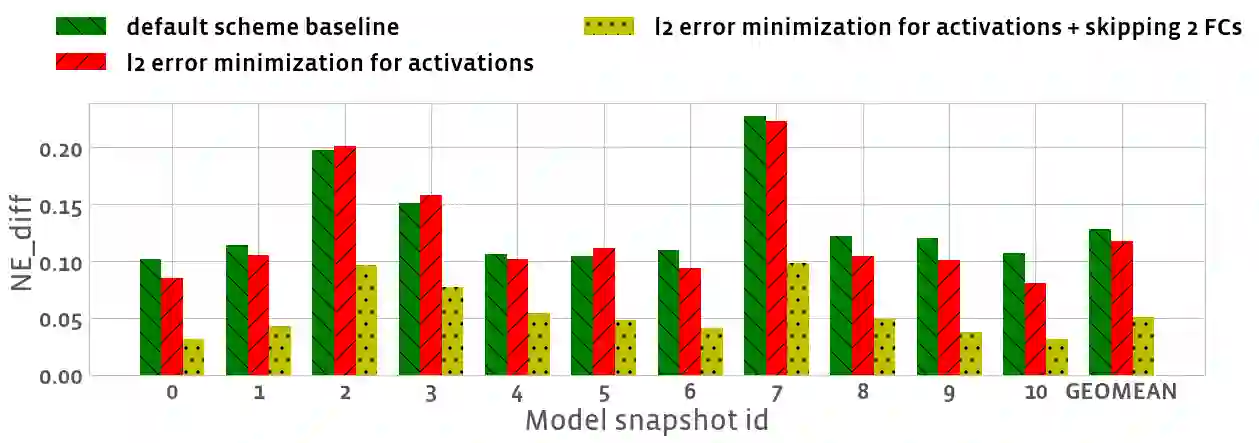
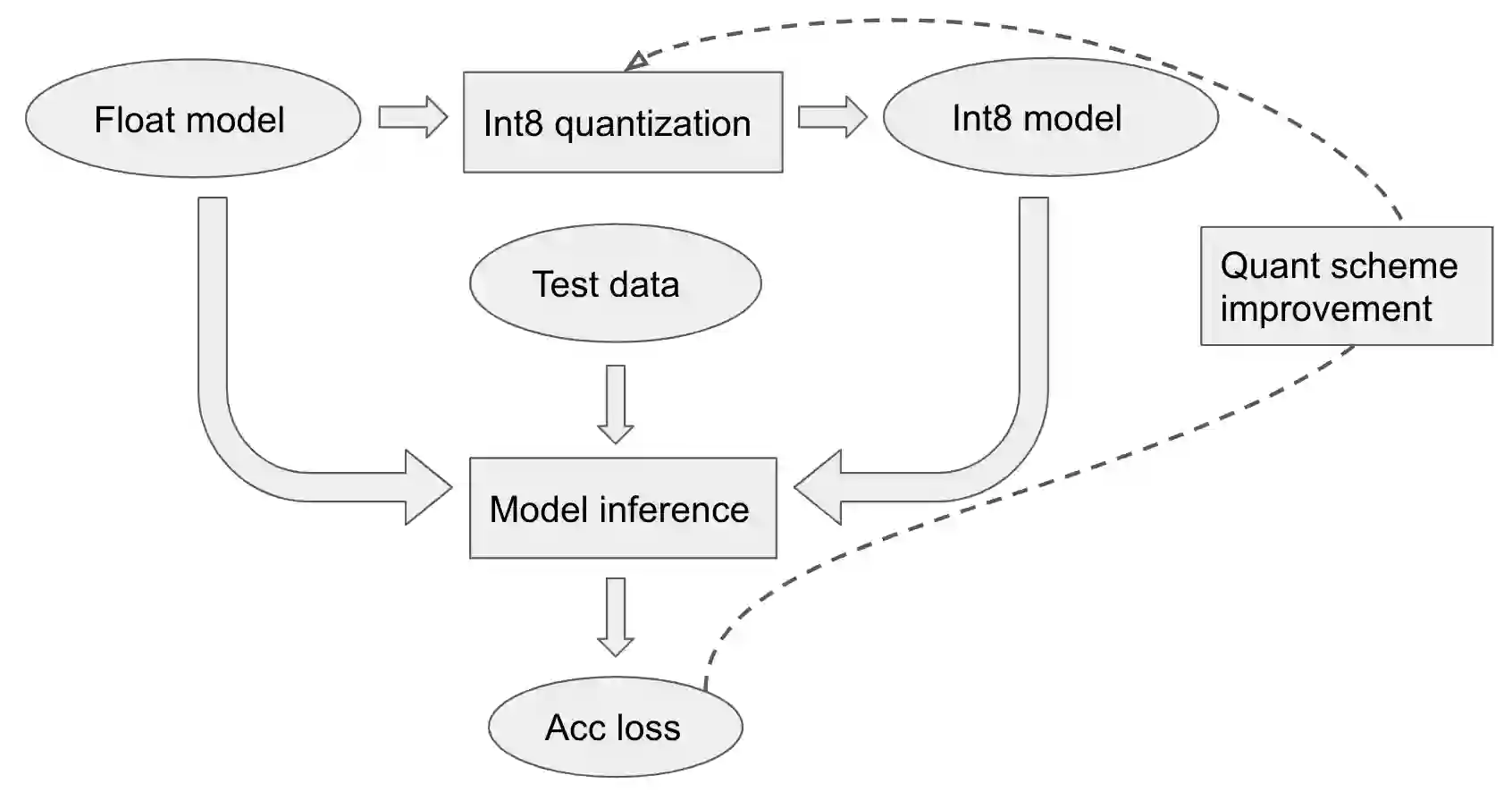
Tremendous success of machine learning (ML) and the unabated growth in ML model complexity motivated many ML-specific designs in both CPU and accelerator architectures to speed up the model inference. While these architectures are diverse, highly optimized low-precision arithmetic is a component shared by most. Impressive compute throughputs are indeed often exhibited by these architectures on benchmark ML models. Nevertheless, production models such as recommendation systems important to Facebook's personalization services are demanding and complex: These systems must serve billions of users per month responsively with low latency while maintaining high prediction accuracy, notwithstanding computations with many tens of billions parameters per inference. Do these low-precision architectures work well with our production recommendation systems? They do. But not without significant effort. We share in this paper our search strategies to adapt reference recommendation models to low-precision hardware, our optimization of low-precision compute kernels, and the design and development of tool chain so as to maintain our models' accuracy throughout their lifespan during which topic trends and users' interests inevitably evolve. Practicing these low-precision technologies helped us save datacenter capacities while deploying models with up to 5X complexity that would otherwise not be deployed on traditional general-purpose CPUs. We believe these lessons from the trenches promote better co-design between hardware architecture and software engineering and advance the state of the art of ML in industry.
翻译:机器学习(ML)的成功以及ML模型复杂程度的不断增长,使机器学习(ML)和ML模型复杂程度的持续增长激励了CPU和加速器结构中许多针对ML的设计,从而加速模型推断。这些结构是多种多样的,但高度优化的低精度计算算术是多数人共有的组成部分。这些基准ML模型的这些结构确实经常展示令人印象深刻的计算分数。然而,对Facebook个人化服务十分重要的建议系统等生产模型要求既复杂又复杂:这些系统必须每月为数十亿用户提供适应性低潜伏的设计,同时保持高预测准确性,尽管以数十亿参数进行计算,以加速模型推导出。这些低精度结构是否与我们的生产建议系统运作良好?它们确实如此。我们在本文中分享我们的搜索战略是将参考建议模型改用低精度的硬件,我们优化了低精度计算内核内核的内核,以及工具链的设计和发展都是为了保持我们模型整个寿命的准确性,在此期间,尽管有数十亿个参数参数参数参数和用户的利益,我们无法避免在常规工程结构结构上发展中提升我们。