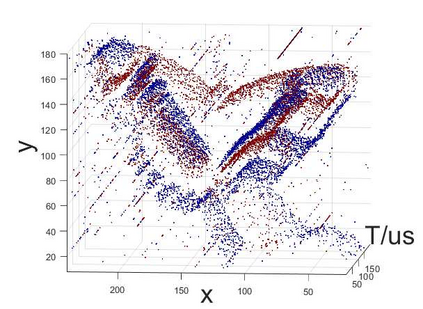
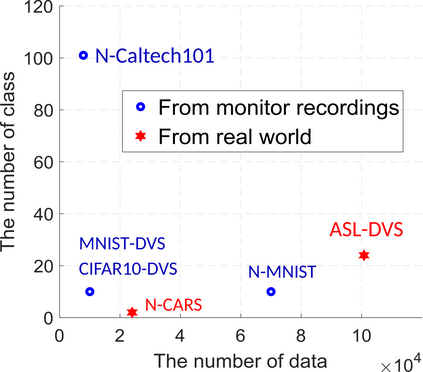
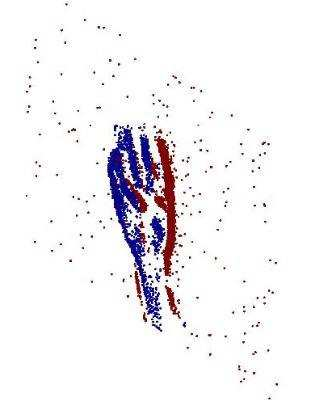
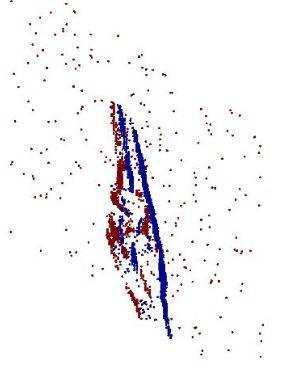
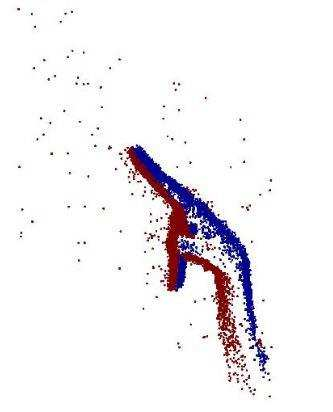
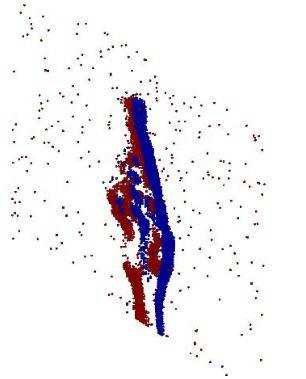
Neuromorphic vision sensing (NVS)\ devices represent visual information as sequences of asynchronous discrete events (a.k.a., ``spikes'') in response to changes in scene reflectance. Unlike conventional active pixel sensing (APS), NVS allows for significantly higher event sampling rates at substantially increased energy efficiency and robustness to illumination changes. However, object classification with NVS streams cannot leverage on state-of-the-art convolutional neural networks (CNNs), since NVS does not produce frame representations. To circumvent this mismatch between sensing and processing with CNNs, we propose a compact graph representation for NVS. We couple this with novel residual graph CNN architectures and show that, when trained on spatio-temporal NVS data for object classification, such residual graph CNNs preserve the spatial and temporal coherence of spike events, while requiring less computation and memory. Finally, to address the absence of large real-world NVS datasets for complex recognition tasks, we present and make available a 100k dataset of NVS recordings of the American sign language letters, acquired with an iniLabs DAVIS240c device under real-world conditions.
翻译:神经地貌视觉感测(NVS)设备代表了视觉信息,作为非同步离散事件(a.k.a.a.,“spikes'”)序列的视觉信息,以回应场景反射的变化。与常规活性像素感测(APS)不同,NVS允许以大幅度提高能源效率和对光化变化的稳健性来大幅提高采样率。然而,NVS流的物体分类无法影响最先进的神经神经网络(CNNs),因为NVS没有产生框架表示。为绕过与CNN的感测和处理之间的这种不匹配,我们提议为NVS提供一个缩略图表示。我们将此与新型的CNN光电图结构合并,并表明,在接受关于用于物体分类的spatio-时空 NVSS数据的培训时,这类残余CNNSs保持了峰值事件的空间和时间一致性,同时需要较少计算和记忆。最后,为了解决没有大型真实世界的NVS数据集用于复杂识别任务的问题,我们提出并提供了在DAS-L设备下100公里的NVS记录。