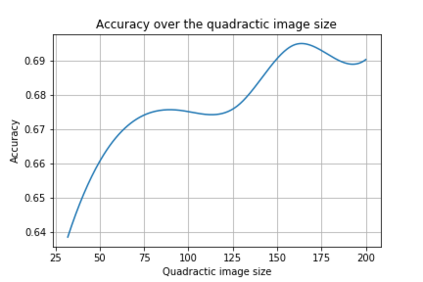
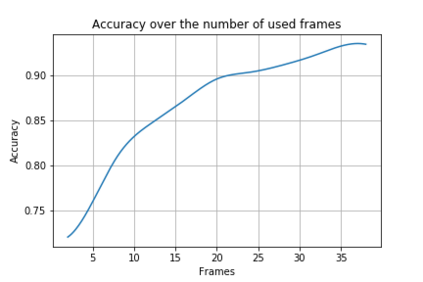
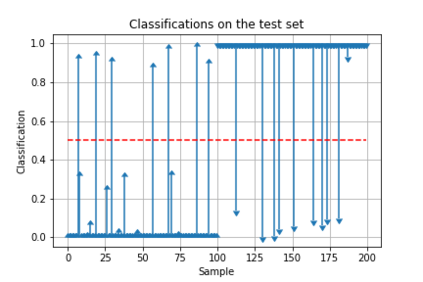
Robots are becoming everyday devices, increasing their interaction with humans. To make human-machine interaction more natural, cognitive features like Visual Voice Activity Detection (VVAD), which can detect whether a person is speaking or not, given visual input of a camera, need to be implemented. Neural networks are state of the art for tasks in Image Processing, Time Series Prediction, Natural Language Processing and other domains. Those Networks require large quantities of labeled data. Currently there are not many datasets for the task of VVAD. In this work we created a large scale dataset called the VVAD-LRS3 dataset, derived by automatic annotations from the LRS3 dataset. The VVAD-LRS3 dataset contains over 44K samples, over three times the next competitive dataset (WildVVAD). We evaluate different baselines on four kinds of features: facial and lip images, and facial and lip landmark features. With a Convolutional Neural Network Long Short Term Memory (CNN LSTM) on facial images an accuracy of 92% was reached on the test set. A study with humans showed that they reach an accuracy of 87.93% on the test set.
翻译:机器人正在成为日常的装置, 增加他们与人类的互动。 为了让人类机器的互动更加自然, 需要实施视觉语音活动检测(VVAD)等认知特征, 以摄像头的视觉输入为条件, 可以检测一个人是否在说话。 神经网络是图像处理、 时间序列预测、 自然语言处理和其他域的任务的最先进。 这些网络需要大量标签数据。 目前 VVAD 的任务没有太多的数据集。 在这项工作中, 我们创建了一个大型数据集, 称为 VVAD- LRS3 数据集, 由 LRS3 数据集的自动说明衍生出来。 VVVAD- LRS3 数据集包含44K 多个样本, 是下一个竞争性数据集( WildVAD)的三倍以上。 我们评估了四种特征的不同基线: 面部和嘴部图像, 面部和唇部标志性特征。 在脸部图像上, 具有一个革命性网络的长时程记忆( CNNLSTM) 。 在测试集上达到了92%的精确度。 。 与人类的一项研究表明, 测试显示它们达到87.93% 的精确度。