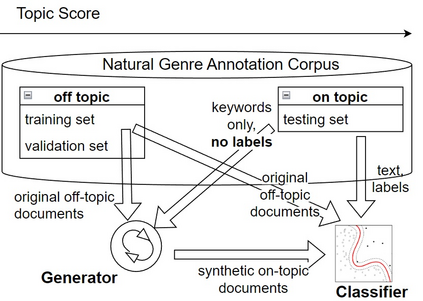
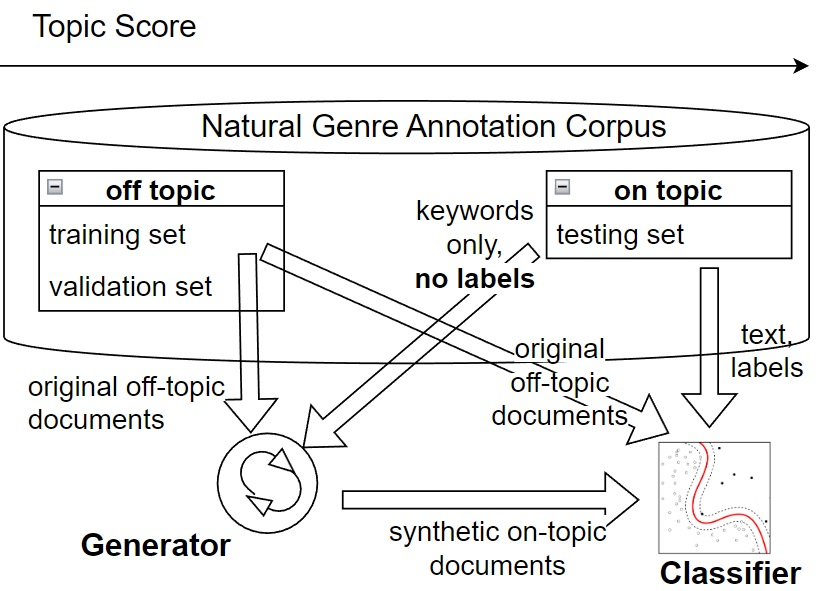
While performance of many text classification tasks has been recently improved due to Pre-trained Language Models (PLMs), in this paper we show that they still suffer from a performance gap when the underlying distribution of topics changes. For example, a genre classifier trained on \textit{political} topics often fails when tested on documents about \textit{sport} or \textit{medicine}. In this work, we quantify this phenomenon empirically with a large corpus and a large set of topics. Consequently, we verify that domain transfer remains challenging both for classic PLMs, such as BERT, and for modern large models, such as GPT-3. We also suggest and successfully test a possible remedy: after augmenting the training dataset with topically-controlled synthetic texts, the F1 score improves by up to 50\% for some topics, nearing on-topic training results, while others show little to no improvement. While our empirical results focus on genre classification, our methodology is applicable to other classification tasks such as gender, authorship, or sentiment classification. The code and data to replicate the experiments are available at https://github.com/dminus1/genre
翻译:暂无翻译