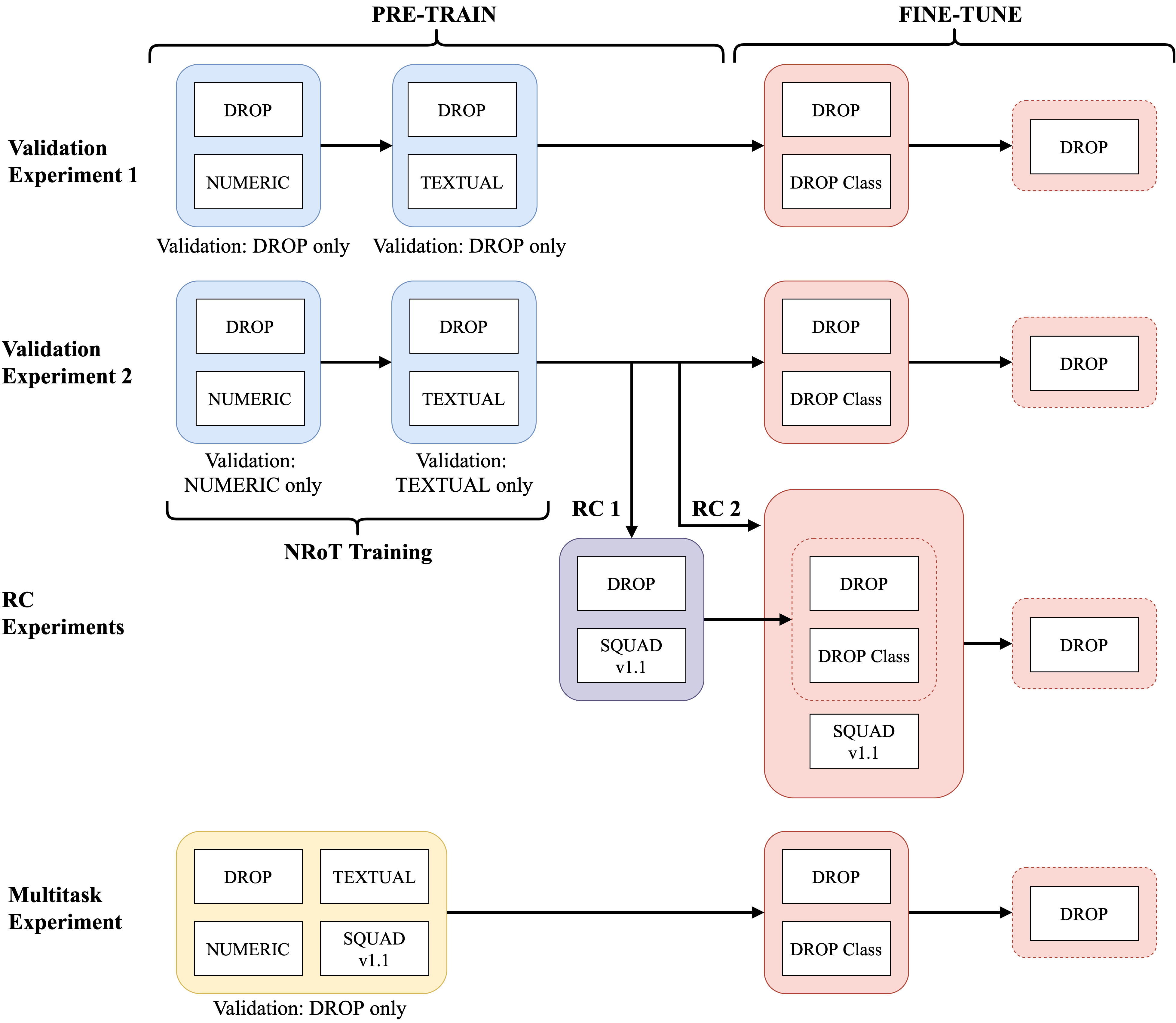
Numerical reasoning over text (NRoT) presents unique challenges that are not well addressed by existing pre-training objectives. We explore five sequential training schedules that adapt a pre-trained T5 model for NRoT. Our final model is adapted from T5, but further pre-trained on three datasets designed to strengthen skills necessary for NRoT and general reading comprehension before being fine-tuned on the Discrete Reasoning over Text (DROP) dataset. The training improves DROP's adjusted F1 performance (a numeracy-focused score) from 45.90 to 70.83. Our model closes in on GenBERT (72.4), a custom BERT-Base model using the same datasets with significantly more parameters. We show that training the T5 multitasking framework with multiple numerical reasoning datasets of increasing difficulty, good performance on DROP can be achieved without manually engineering partitioned functionality between distributed and symbol modules.
翻译:对文本(NROT)的量化推理提出了独特的挑战,而现有的培训前目标没有很好地解决这些挑战。我们探索了五个连续培训时间表,以调整培训前的T5模型。我们的最后模型来自T5,但是在三个数据集方面进行了进一步预先培训,这些数据集旨在加强NROT和一般阅读理解所需的技能,然后才对文本分解(DROP)数据集进行微调。培训使DROP的调整F1性能(以算术为重点的分数)从45.90提高到70.83。我们在GENBERT的模型(72.4)上关闭了,GENBERT的定制BERT-Base模型,使用相同的数据集,参数大大增加。我们表明,在培训T5多任务框架时,多数字推理数据集越来越困难,DROP的良好性能可以在没有分布模块和符号模块之间手动工程分解功能的情况下实现。