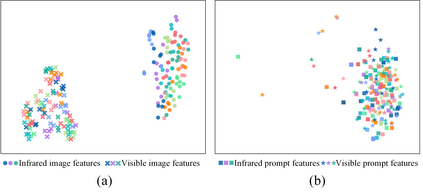
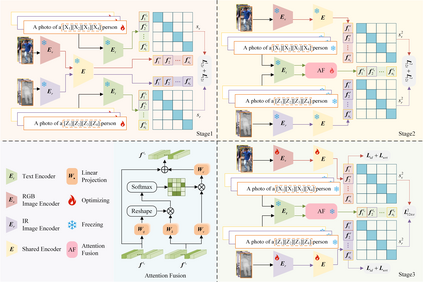
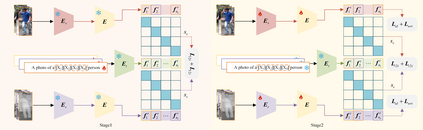
Visible-infrared person re-identification (VIReID) primarily deals with matching identities across person images from different modalities. Due to the modality gap between visible and infrared images, cross-modality identity matching poses significant challenges. Recognizing that high-level semantics of pedestrian appearance, such as gender, shape, and clothing style, remain consistent across modalities, this paper intends to bridge the modality gap by infusing visual features with high-level semantics. Given the capability of CLIP to sense high-level semantic information corresponding to visual representations, we explore the application of CLIP within the domain of VIReID. Consequently, we propose a CLIP-Driven Semantic Discovery Network (CSDN) that consists of Modality-specific Prompt Learner, Semantic Information Integration (SII), and High-level Semantic Embedding (HSE). Specifically, considering the diversity stemming from modality discrepancies in language descriptions, we devise bimodal learnable text tokens to capture modality-private semantic information for visible and infrared images, respectively. Additionally, acknowledging the complementary nature of semantic details across different modalities, we integrate text features from the bimodal language descriptions to achieve comprehensive semantics. Finally, we establish a connection between the integrated text features and the visual features across modalities. This process embed rich high-level semantic information into visual representations, thereby promoting the modality invariance of visual representations. The effectiveness and superiority of our proposed CSDN over existing methods have been substantiated through experimental evaluations on multiple widely used benchmarks. The code will be released at \url{https://github.com/nengdong96/CSDN}.
翻译:暂无翻译