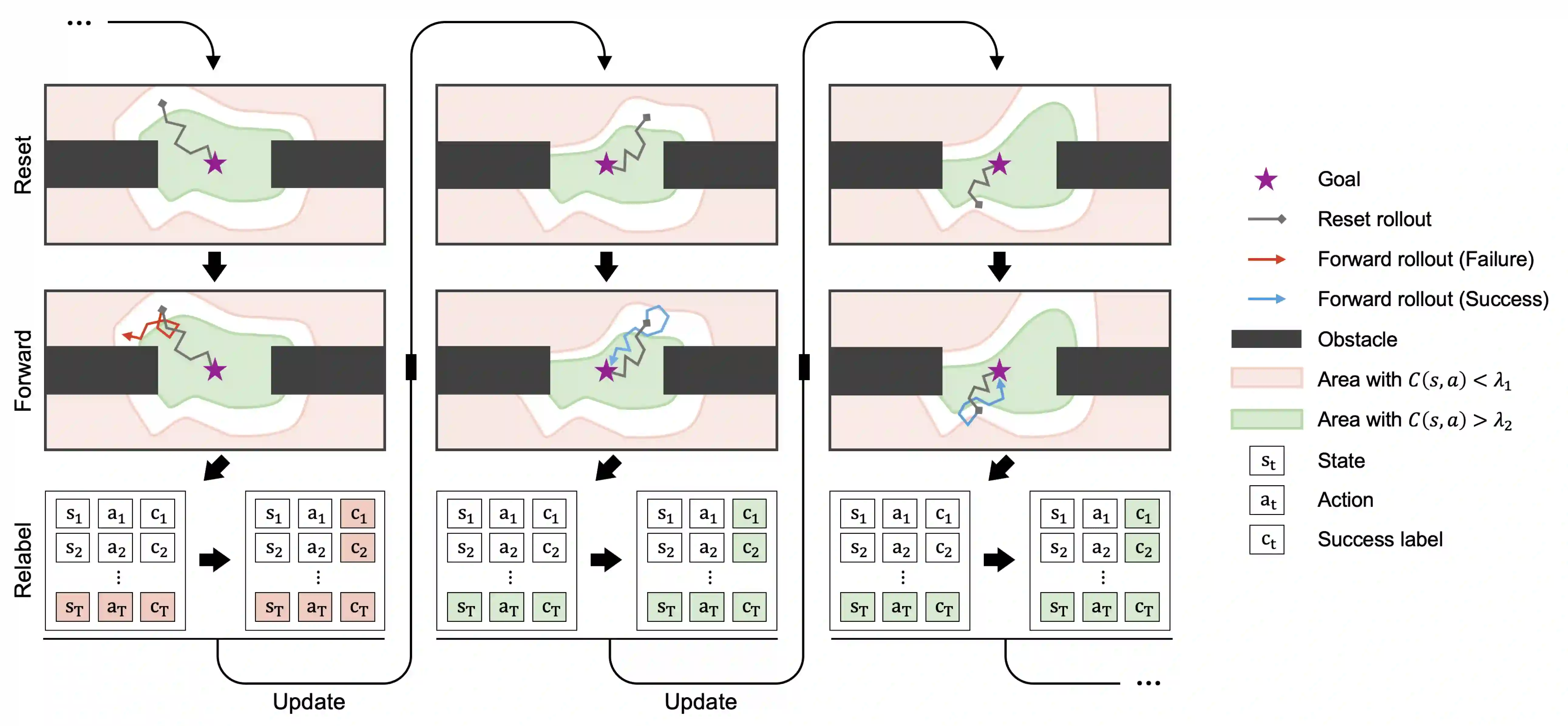
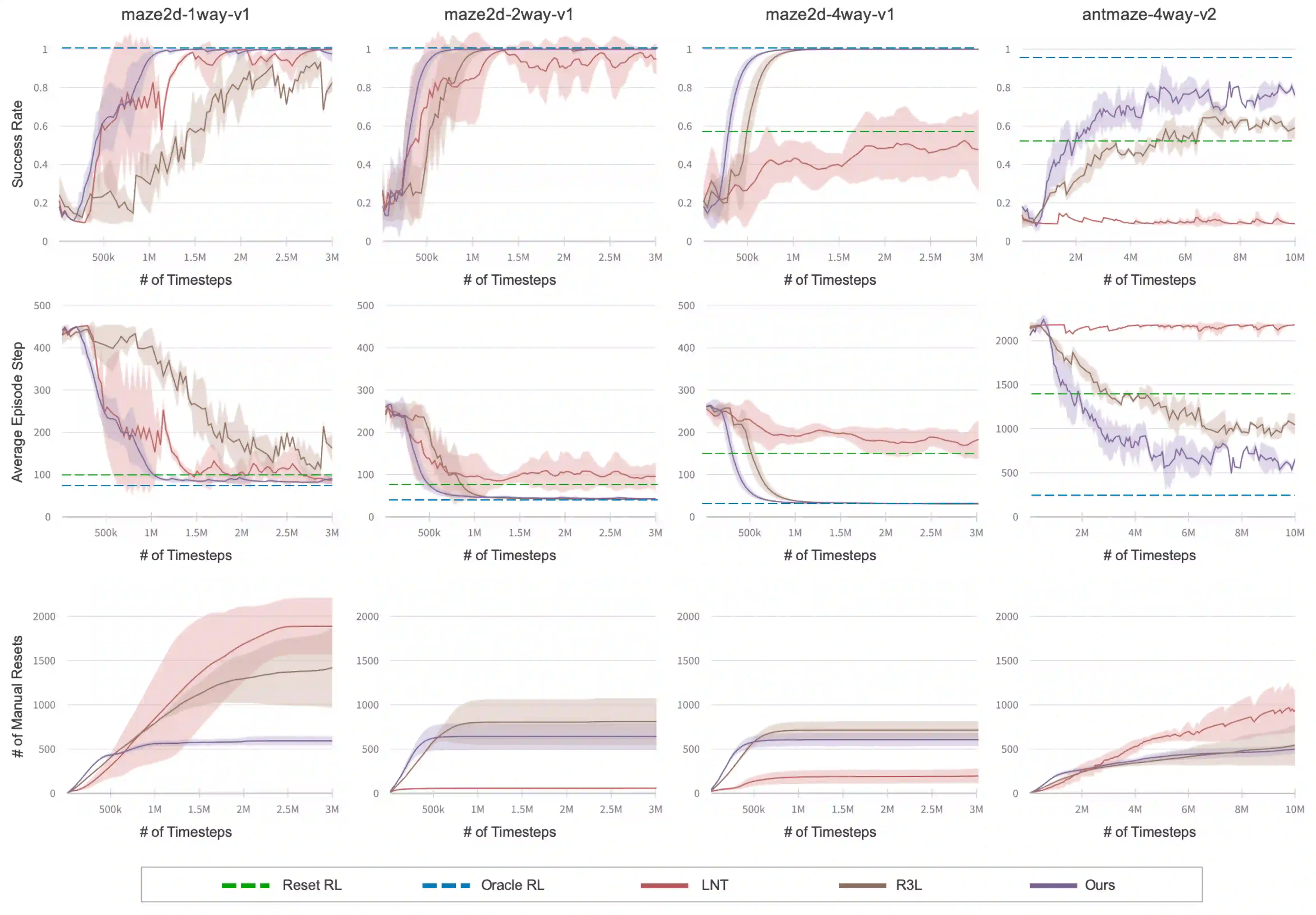
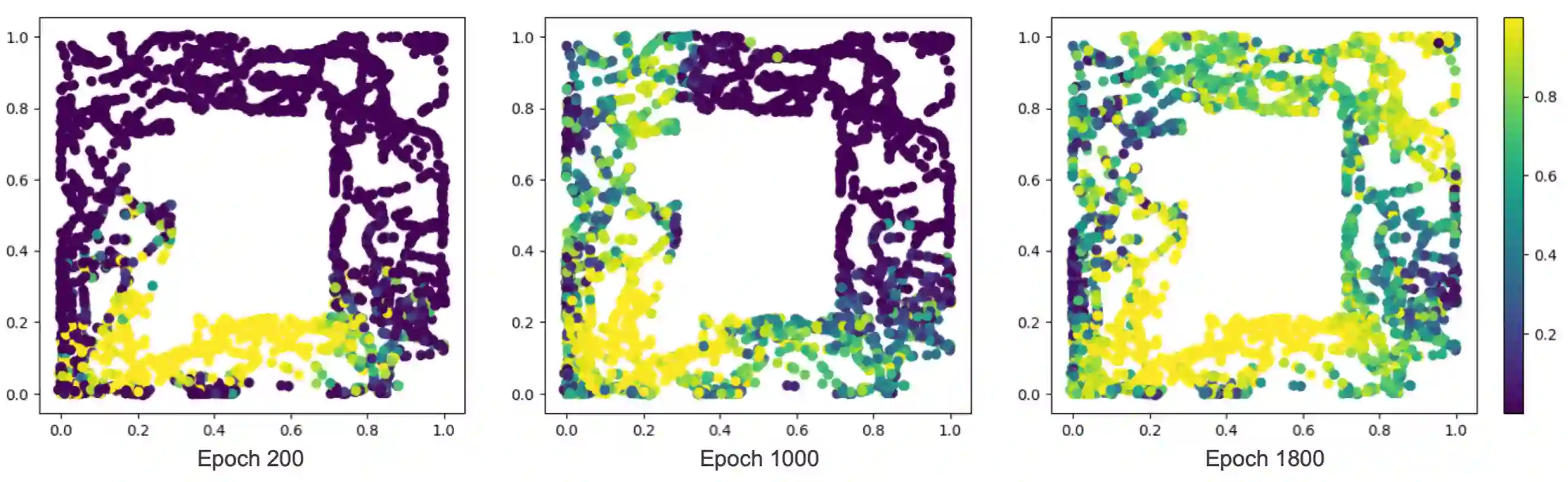
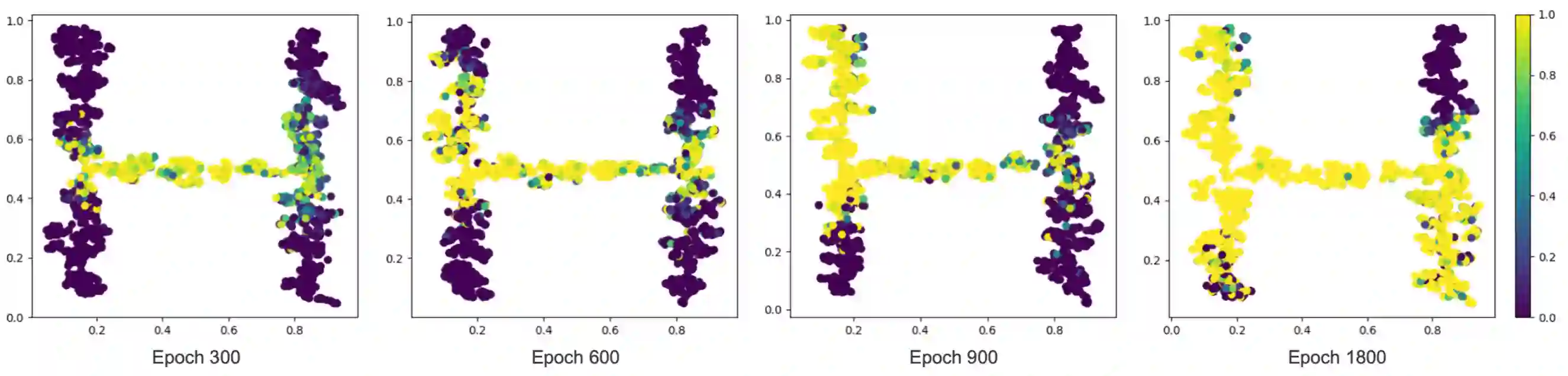
A significant bottleneck in applying current reinforcement learning algorithms to real-world scenarios is the need to reset the environment between every episode. This reset process demands substantial human intervention, making it difficult for the agent to learn continuously and autonomously. Several recent works have introduced autonomous reinforcement learning (ARL) algorithms that generate curricula for jointly training reset and forward policies. While their curricula can reduce the number of required manual resets by taking into account the agent's learning progress, they rely on task-specific knowledge, such as predefined initial states or reset reward functions. In this paper, we propose a novel ARL algorithm that can generate a curriculum adaptive to the agent's learning progress without task-specific knowledge. Our curriculum empowers the agent to autonomously reset to diverse and informative initial states. To achieve this, we introduce a success discriminator that estimates the success probability from each initial state when the agent follows the forward policy. The success discriminator is trained with relabeled transitions in a self-supervised manner. Our experimental results demonstrate that our ARL algorithm can generate an adaptive curriculum and enable the agent to efficiently bootstrap to solve sparse-reward maze navigation tasks, outperforming baselines with significantly fewer manual resets.
翻译:暂无翻译