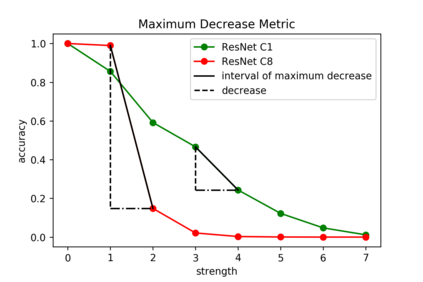
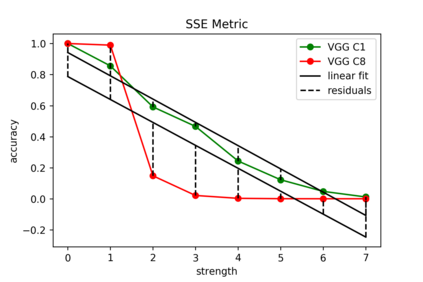
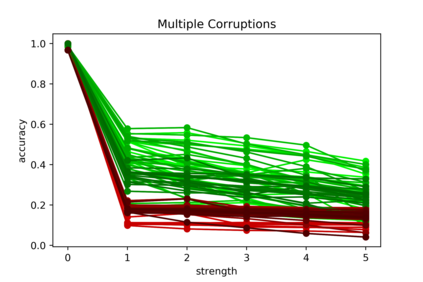
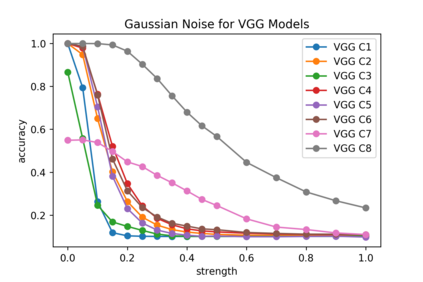
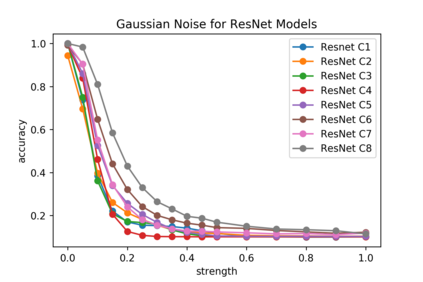
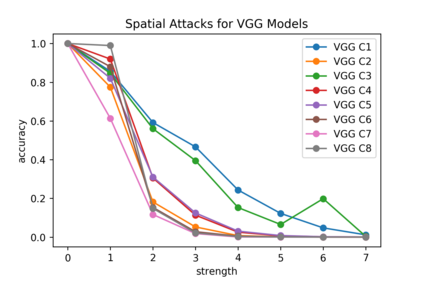
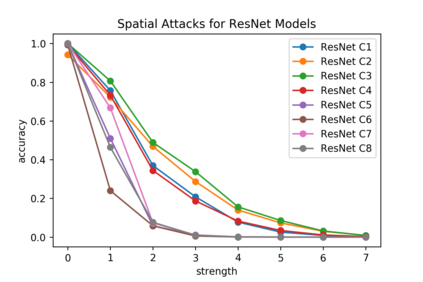
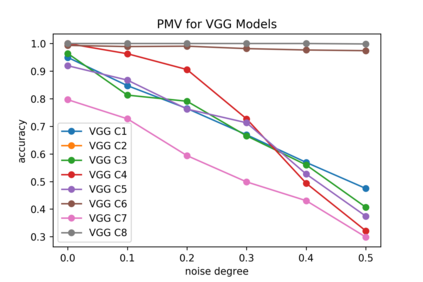
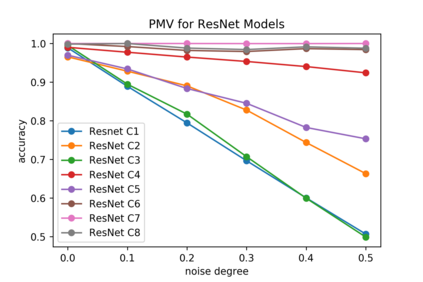
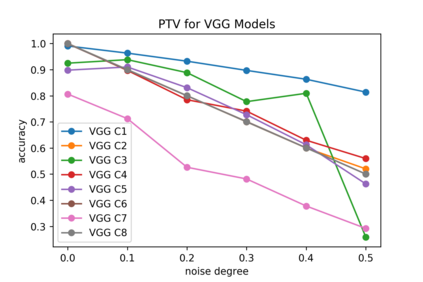
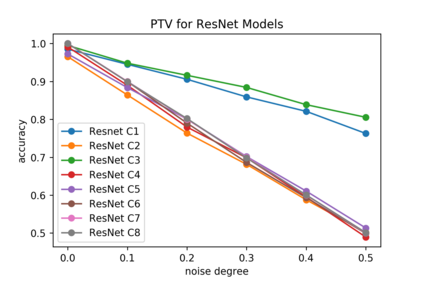
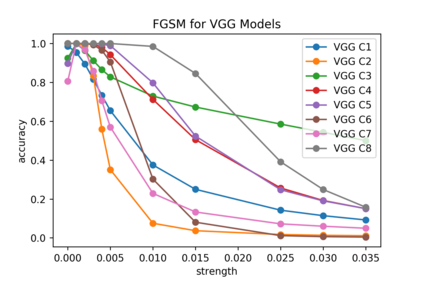
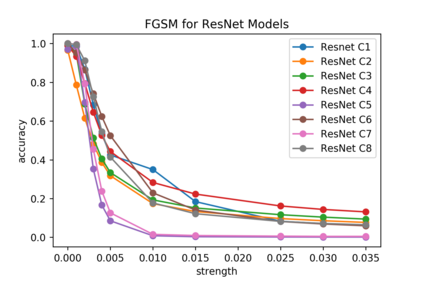
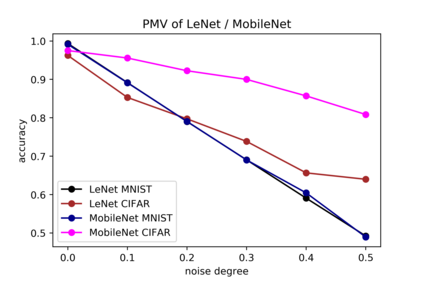
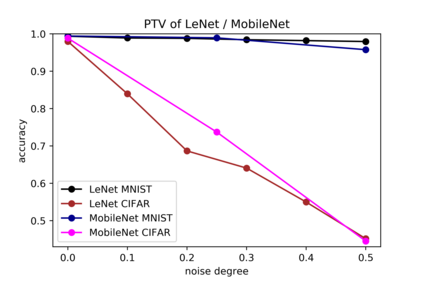
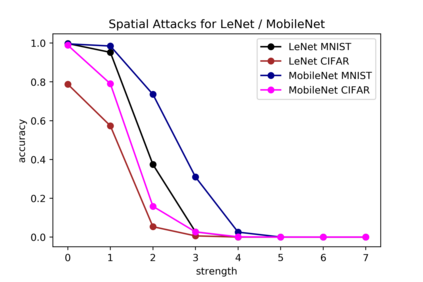
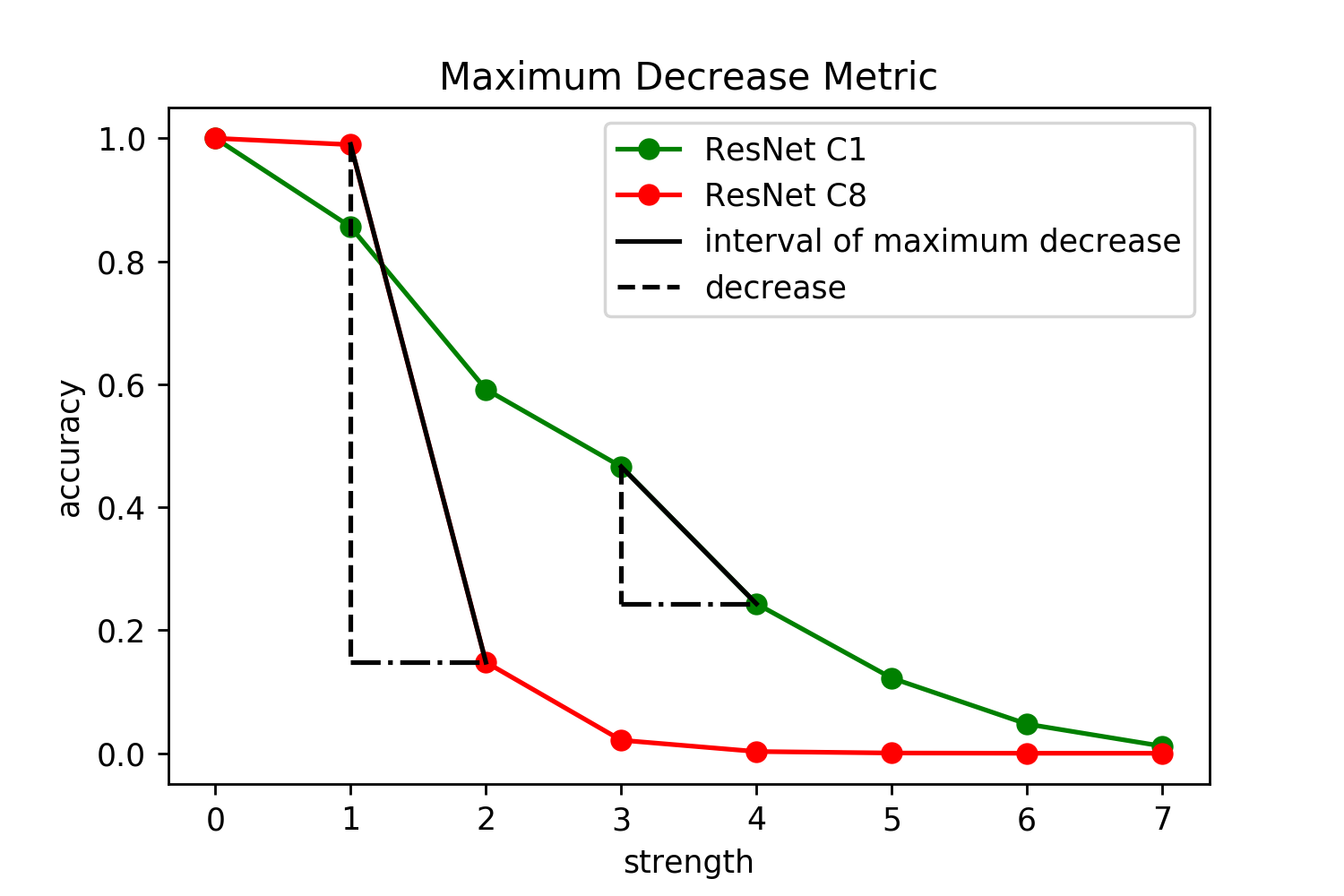
Although numerous methods to reduce the overfitting of convolutional neural networks (CNNs) exist, it is still not clear how to confidently measure the degree of overfitting. A metric reflecting the overfitting level might be, however, extremely helpful for the comparison of different architectures and for the evaluation of various techniques to tackle overfitting. Motivated by the fact that overfitted neural networks tend to rather memorize noise in the training data than generalize to unseen data, we examine how the training accuracy changes in the presence of increasing data perturbations and study the connection to overfitting. While previous work focused on label noise only, we examine a spectrum of techniques to inject noise into the training data, including adversarial perturbations and input corruptions. Based on this, we define two new metrics that can confidently distinguish between correct and overfitted models. For the evaluation, we derive a pool of models for which the overfitting behavior is known beforehand. To test the effect of various factors, we introduce several anti-overfitting measures in architectures based on VGG and ResNet and study their impact, including regularization techniques, training set size, and the number of parameters. Finally, we assess the applicability of the proposed metrics by measuring the overfitting degree of several CNN architectures outside of our model pool.
翻译:尽管存在许多减少过度配制进化神经网络的方法,但仍然不清楚如何自信地衡量过度装配的程度。不过,反映过度装配程度的衡量标准对于比较不同结构和评价各种处理过度装配的技术可能极为有用。由于过度装配神经网络倾向于在培训数据中将噪音混为一文,而不是一般化为隐蔽数据,因此我们考察在数据越多越好的情况下培训准确性的变化以及研究过度装配的关联性。虽然以前的工作仅侧重于标签噪音,但我们考察了将噪音注入培训数据的一系列技术,包括对抗性穿插和输入腐败。在此基础上,我们界定了两个能够自信地区分正确和过度装配模式的新指标。关于评估,我们编出一套模型,预先知道过度装配行为。为了检验各种因素的影响,我们在VGG和ResNet的架构中引入了几项反装配措施,并研究了其应用性,包括调控性技术、培训规模和拟议外部标准的程度,我们最后评估了若干标准框架的大小和程度。