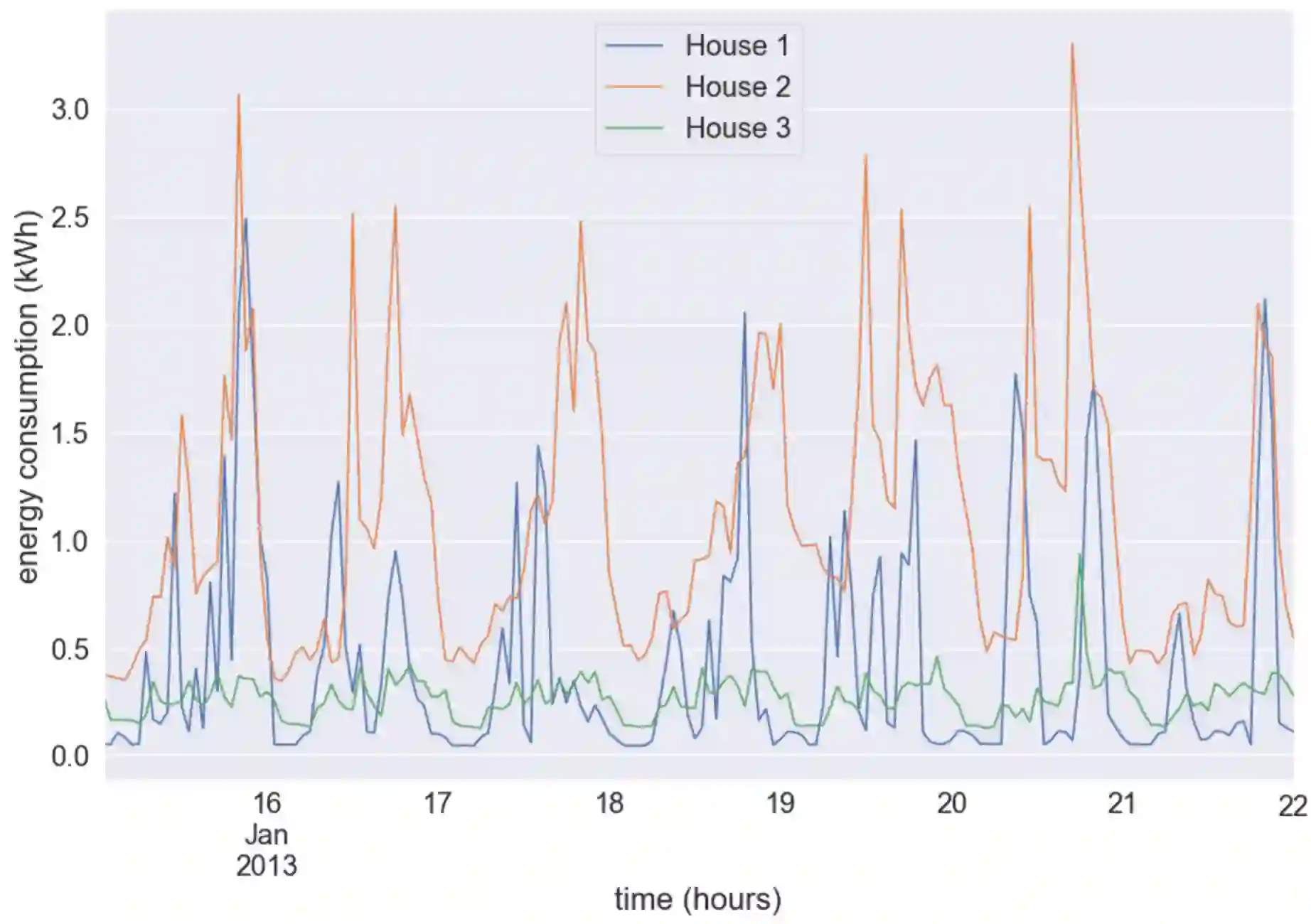
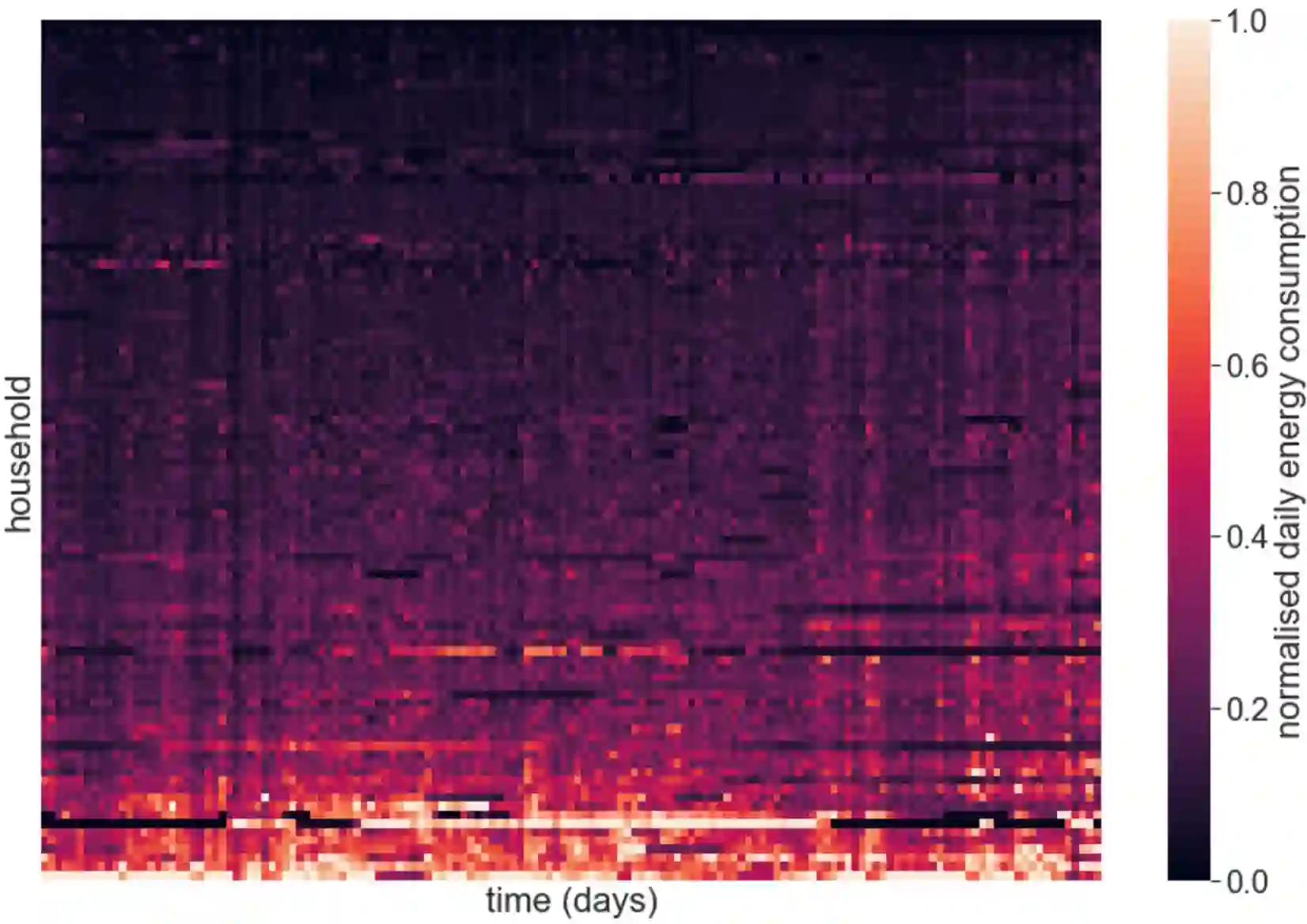
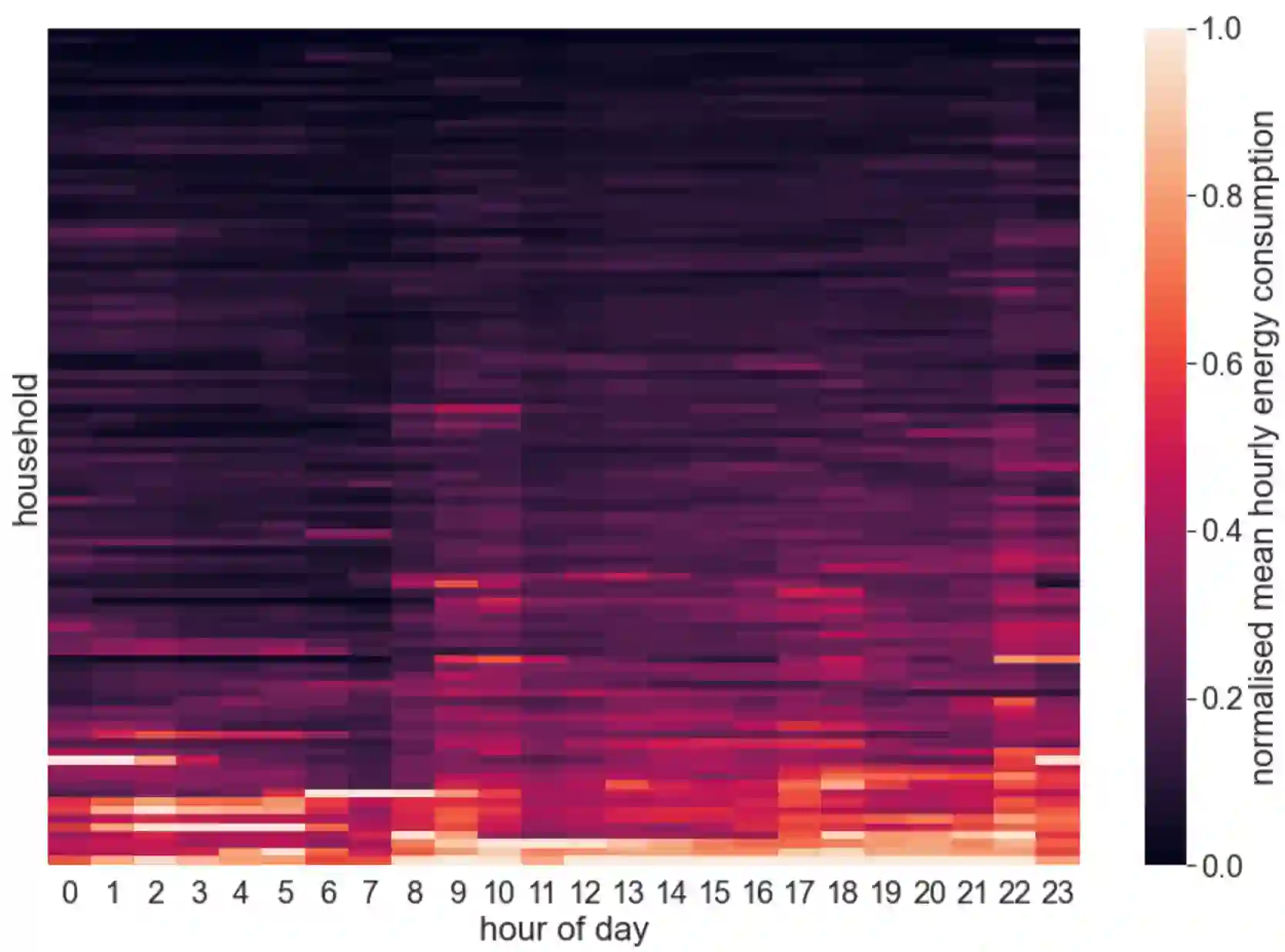
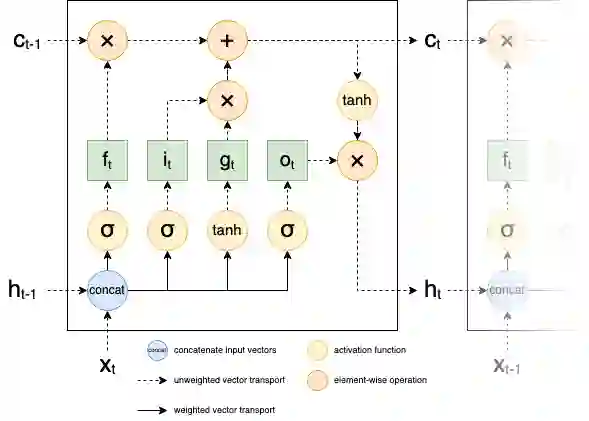
Energy demand forecasting is an essential task performed within the energy industry to help balance supply with demand and maintain a stable load on the electricity grid. As supply transitions towards less reliable renewable energy generation, smart meters will prove a vital component to aid these forecasting tasks. However, smart meter take-up is low among privacy-conscious consumers that fear intrusion upon their fine-grained consumption data. In this work we propose and explore a federated learning (FL) based approach for training forecasting models in a distributed, collaborative manner whilst retaining the privacy of the underlying data. We compare two approaches: FL, and a clustered variant, FL+HC against a non-private, centralised learning approach and a fully private, localised learning approach. Within these approaches, we measure model performance using RMSE and computational efficiency via the number of samples required to train models under each scenario. In addition, we suggest the FL strategies are followed by a personalisation step and show that model performance can be improved by doing so. We show that FL+HC followed by personalisation can achieve a $\sim$5% improvement in model performance with a $\sim$10x reduction in computation compared to localised learning. Finally we provide advice on private aggregation of predictions for building a private end-to-end energy demand forecasting application.
翻译:能源需求预测是能源工业的一项基本任务,有助于平衡供需并保持电网的稳定负荷。随着供应向不那么可靠的可再生能源发电过渡,智能米将证明是帮助这些预测任务的一个关键组成部分。然而,在有隐私意识的消费者中,智能计量接收率较低,他们担心微粒消费数据被侵入。在这项工作中,我们提议并探索一种基于联合学习(FL)的方法,以分散、合作的方式培训预测模型,同时保留基本数据的隐私。我们比较了两种方法:FL和一组变体,即FL+HC,以非私人集中学习方式和完全私人、地方化的学习方式。在这些方法中,我们通过每种情景下培训模型所需的样本数量来衡量使用RMSE的模型和计算效率。此外,我们建议FL战略遵循一个个化步骤,通过这样做可以改进模型的性能表现。我们显示FL+HC,然后是个性化的组合变体,在模型性化性化表现方面可以实现5美的改善,FL+HC,而采用非私人集中学习的学习方法,采用完全的私人预测方法,我们最后将10美元用于进行能源预测。我们进行本地的预测,最后进行能源预测。