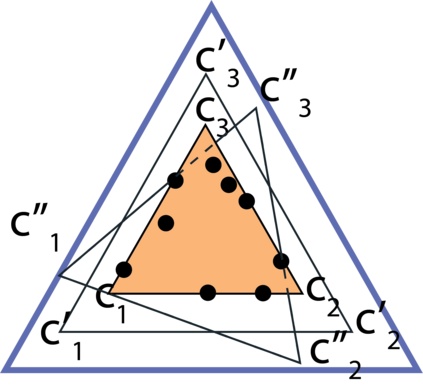
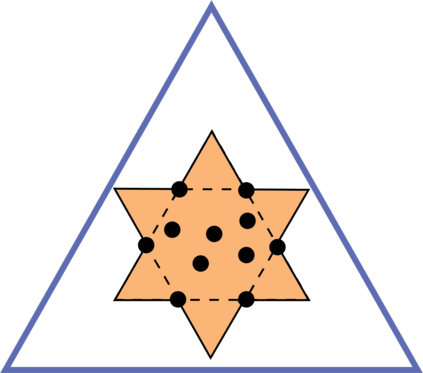
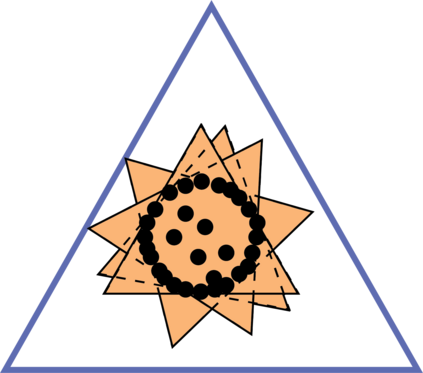
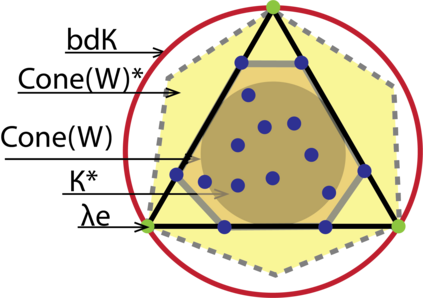
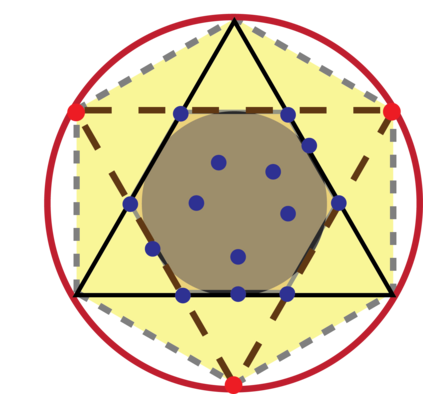
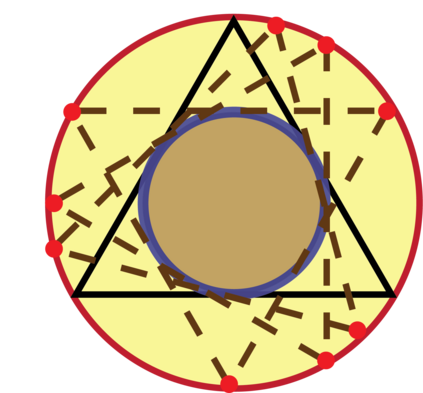
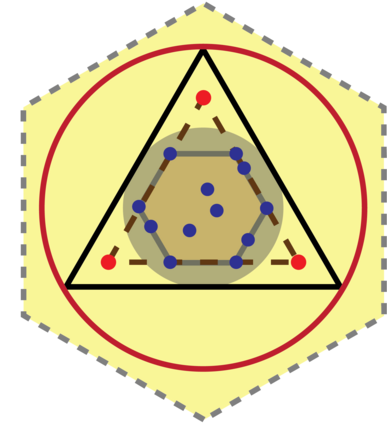
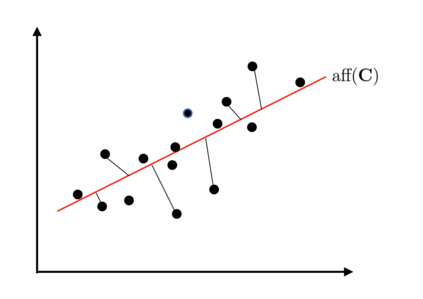
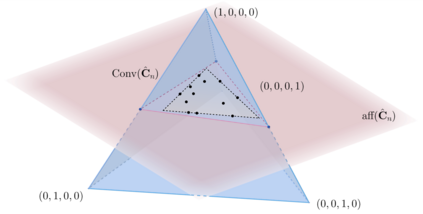
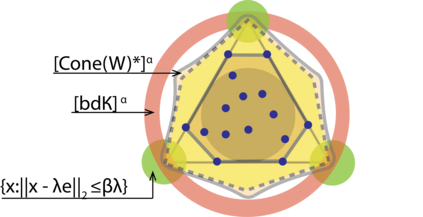
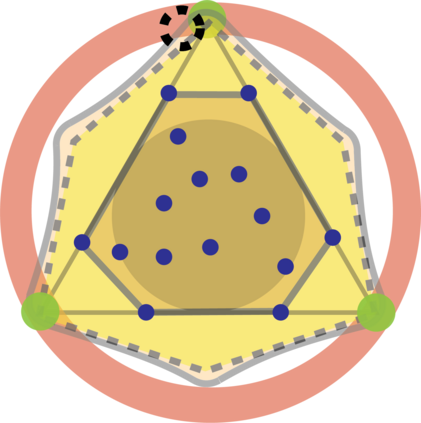
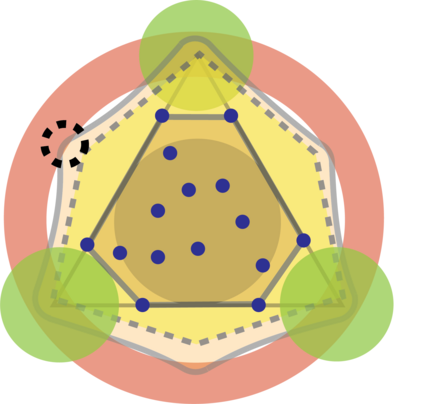
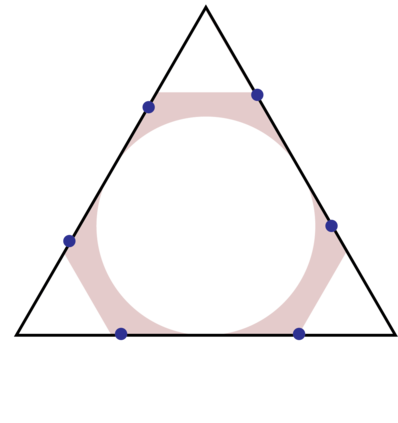
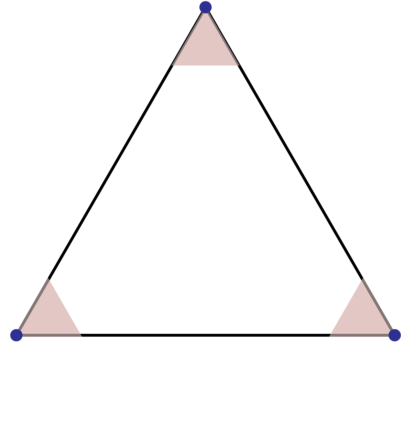
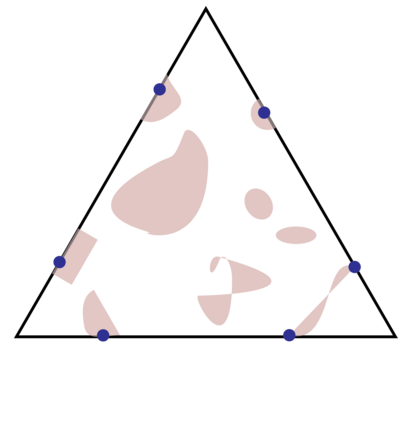
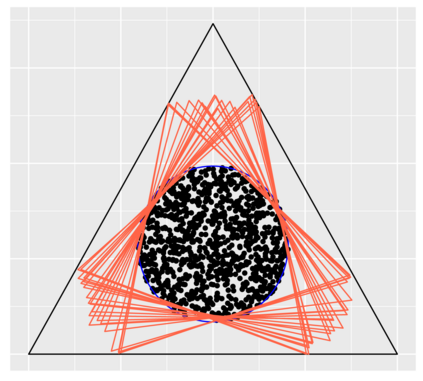
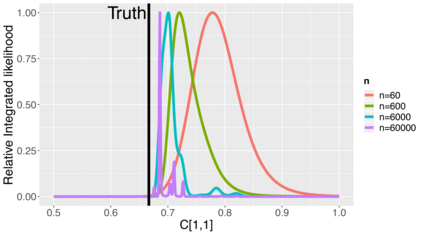
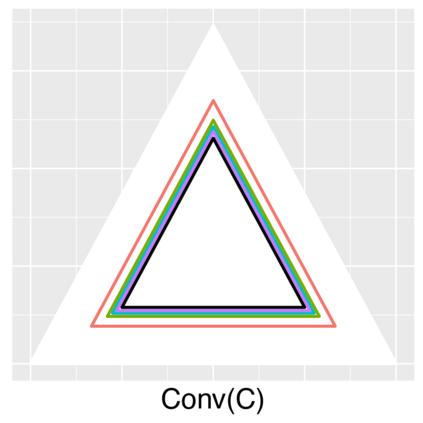
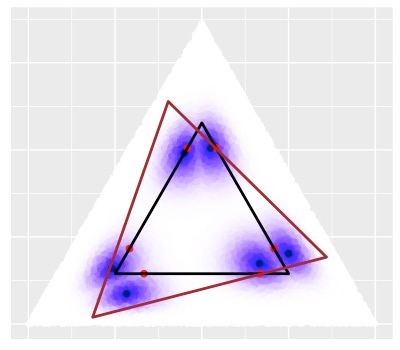
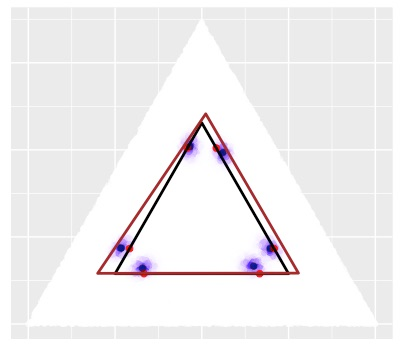
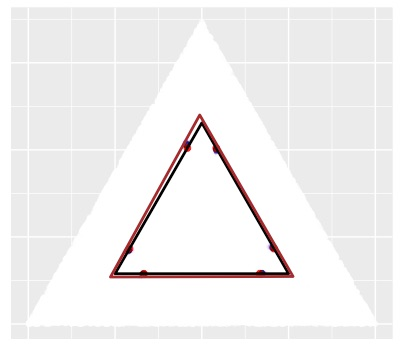
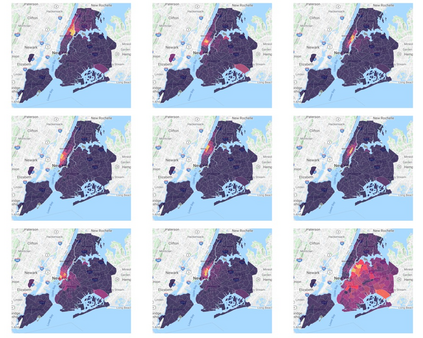
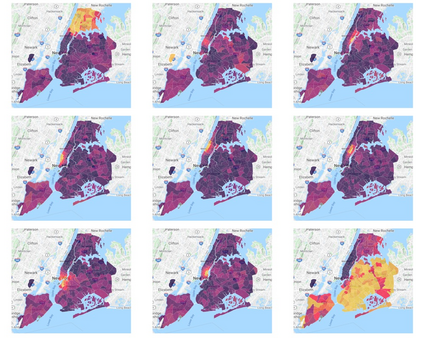
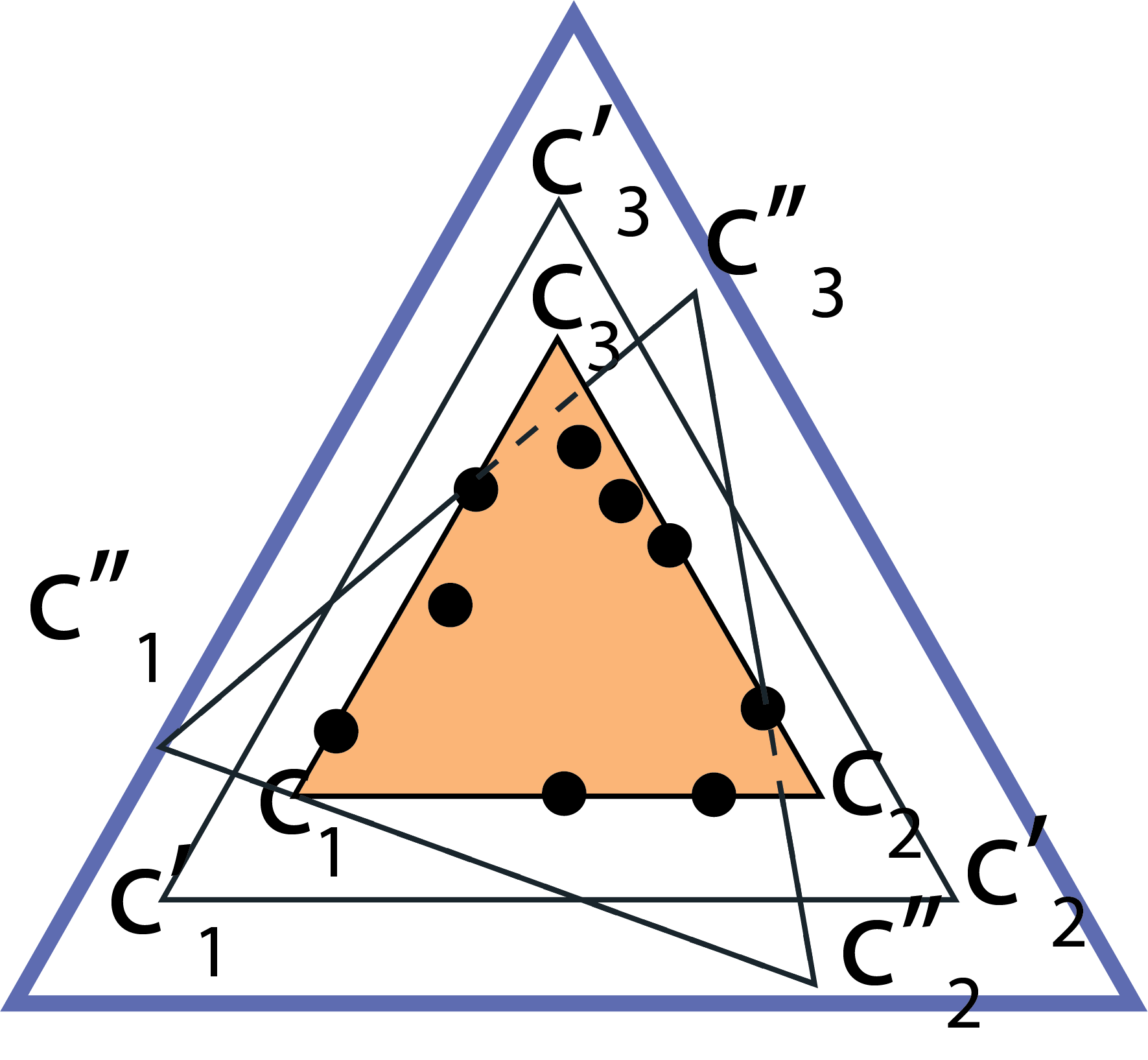
Topic models provide a useful text-mining tool for learning, extracting and discovering latent structures in large text corpora. Although a plethora of methods have been proposed for topic modeling, a formal theoretical investigation on the statistical identifiability and accuracy of latent topic estimation is lacking in the literature. In this paper, we propose a maximum likelihood estimator (MLE) of latent topics based on a specific integrated likelihood, which is naturally connected to the concept of volume minimization in computational geometry. Theoretically, we introduce a new set of geometric conditions for topic model identifiability, which are weaker than conventional separability conditions relying on the existence of anchor words or pure topic documents. We conduct finite-sample error analysis for the proposed estimator and discuss the connection of our results with existing ones. We conclude with empirical studies on both simulated and real datasets.
翻译:专题模型为在大型文本集体中学习、提取和发现潜在结构提供了有用的文字挖掘工具。虽然为专题建模提出了大量方法,但文献中缺乏对潜在专题估计的统计可识别性和准确性的正式理论调查。在本文件中,我们提议根据具体综合可能性对潜在专题进行最大可能性估计,这自然与计算几何中数量最小化的概念相关。理论上,我们为专题模型可识别性引入了一套新的几何条件,这些条件比依赖固定词或纯主题文件存在的常规可分离性条件弱。我们为拟议的估算员进行有限抽样错误分析,并讨论我们的结果与现有参数的联系。我们最后对模拟和真实数据集进行实验性研究。