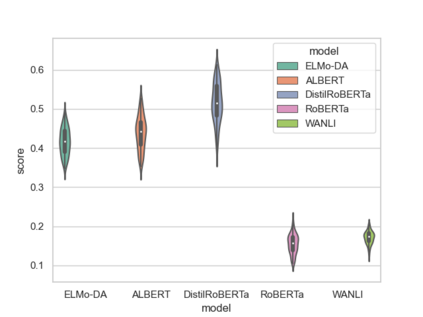
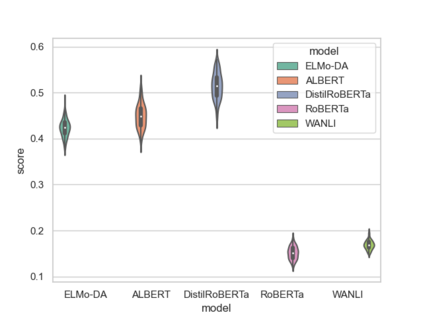
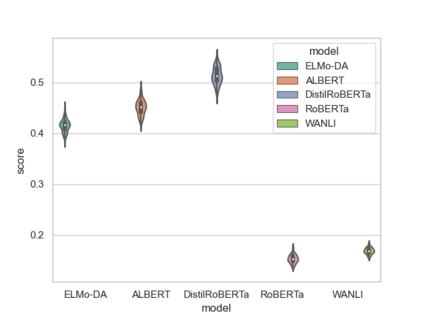
How reliably can we trust the scores obtained from social bias benchmarks as faithful indicators of problematic social biases in a given language model? In this work, we study this question by contrasting social biases with non-social biases stemming from choices made during dataset construction that might not even be discernible to the human eye. To do so, we empirically simulate various alternative constructions for a given benchmark based on innocuous modifications (such as paraphrasing or random-sampling) that maintain the essence of their social bias. On two well-known social bias benchmarks (Winogender and BiasNLI) we observe that these shallow modifications have a surprising effect on the resulting degree of bias across various models. We hope these troubling observations motivate more robust measures of social biases.
翻译:我们如何可靠地相信从社会偏见基准中获得的分数是特定语言模式中问题社会偏见的忠实指标?在这项工作中,我们研究这一问题的方法是,将社会偏见与在数据集构建过程中作出的、甚至人类眼中都看不到的选择所产生的非社会偏见加以对比。为此,我们用经验模拟各种替代结构,以基于无谓修改(例如抛光或随机抽样)的某种基准,以保持其社会偏见的本质。关于两个众所周知的社会偏见基准(Winogender和BiasNLI),我们观察到,这些浅薄的修改对由此产生的各种模式的偏差程度产生了惊人的影响。 我们希望这些令人不安的观察能够促使采取更强有力的社会偏见措施。