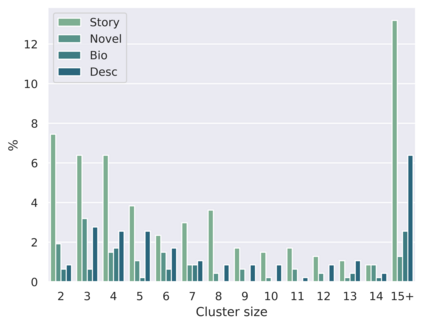
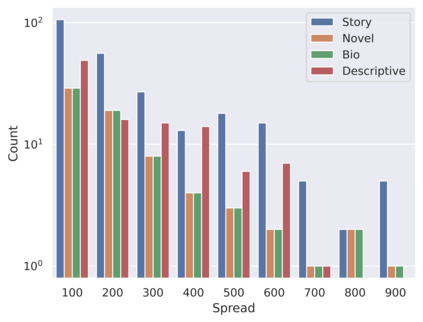
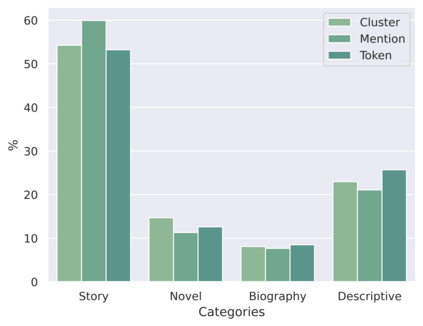
Coreference Resolution is a well studied problem in NLP. While widely studied for English and other resource-rich languages, research on coreference resolution in Bengali largely remains unexplored due to the absence of relevant datasets. Bengali, being a low-resource language, exhibits greater morphological richness compared to English. In this article, we introduce a new dataset, BenCoref, comprising coreference annotations for Bengali texts gathered from four distinct domains. This relatively small dataset contains 5200 mention annotations forming 502 mention clusters within 48,569 tokens. We describe the process of creating this dataset and report performance of multiple models trained using BenCoref. We anticipate that our work sheds some light on the variations in coreference phenomena across multiple domains in Bengali and encourages the development of additional resources for Bengali. Furthermore, we found poor crosslingual performance at zero-shot setting from English, highlighting the need for more language-specific resources for this task.
翻译:核心ference解决是NLP中一个研究十分广泛的问题。尽管针对英文和其他资源丰富的语言的核心参考分辨率得到了广泛的研究,但由于缺乏相关数据集,孟加拉语的核心参考分辨率研究在很大程度上仍未被开发。孟加拉语作为一种低资源语言,与英语相比具有更大的形态学丰富性。在本文中,我们介绍了一个新的数据集BenCoref,其中包含从四个不同领域收集的孟加拉文文本的核心参照注释。这个相对较小的数据集包含5200个提及注释,形成48,569个标记中的502个提及簇。我们描述了创建此数据集的过程,并报告了使用BenCoref训练的多个模型的性能。我们预计我们的工作将在多个领域的Bengali中揭示核心参考现象的变化,并鼓励开发更多的Bengali语言资源。此外,我们发现在从英文进行零-shot设置时,跨语言性能较差,强调了这一任务需要更多的语言特定资源。