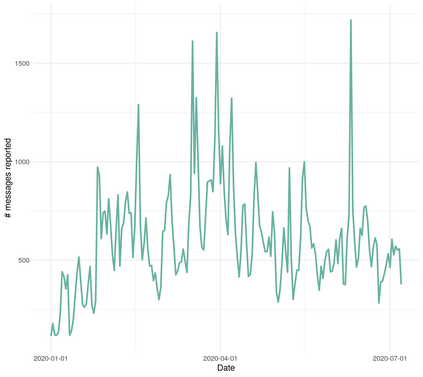
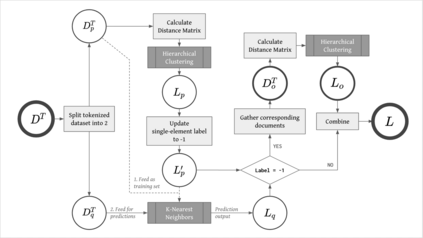
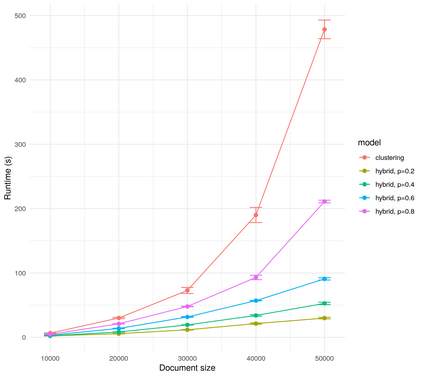
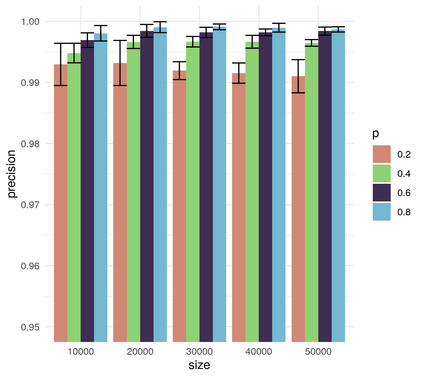
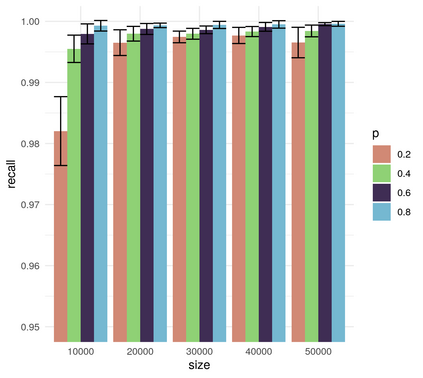
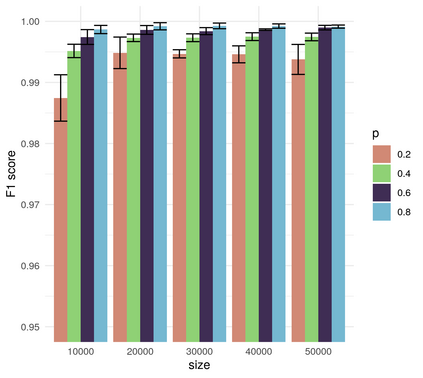
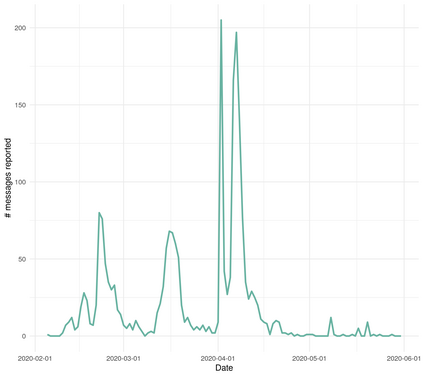
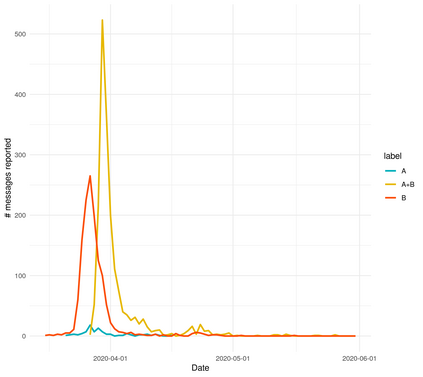
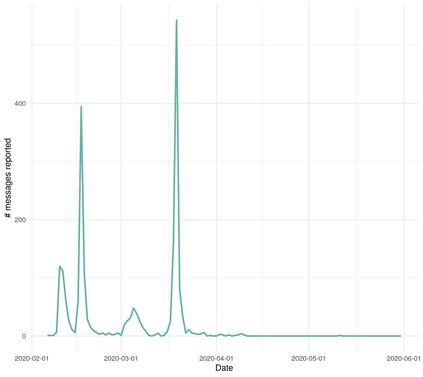
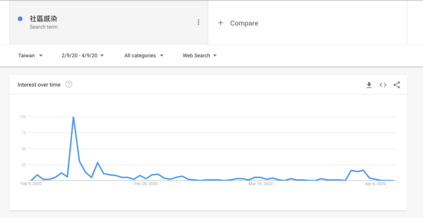
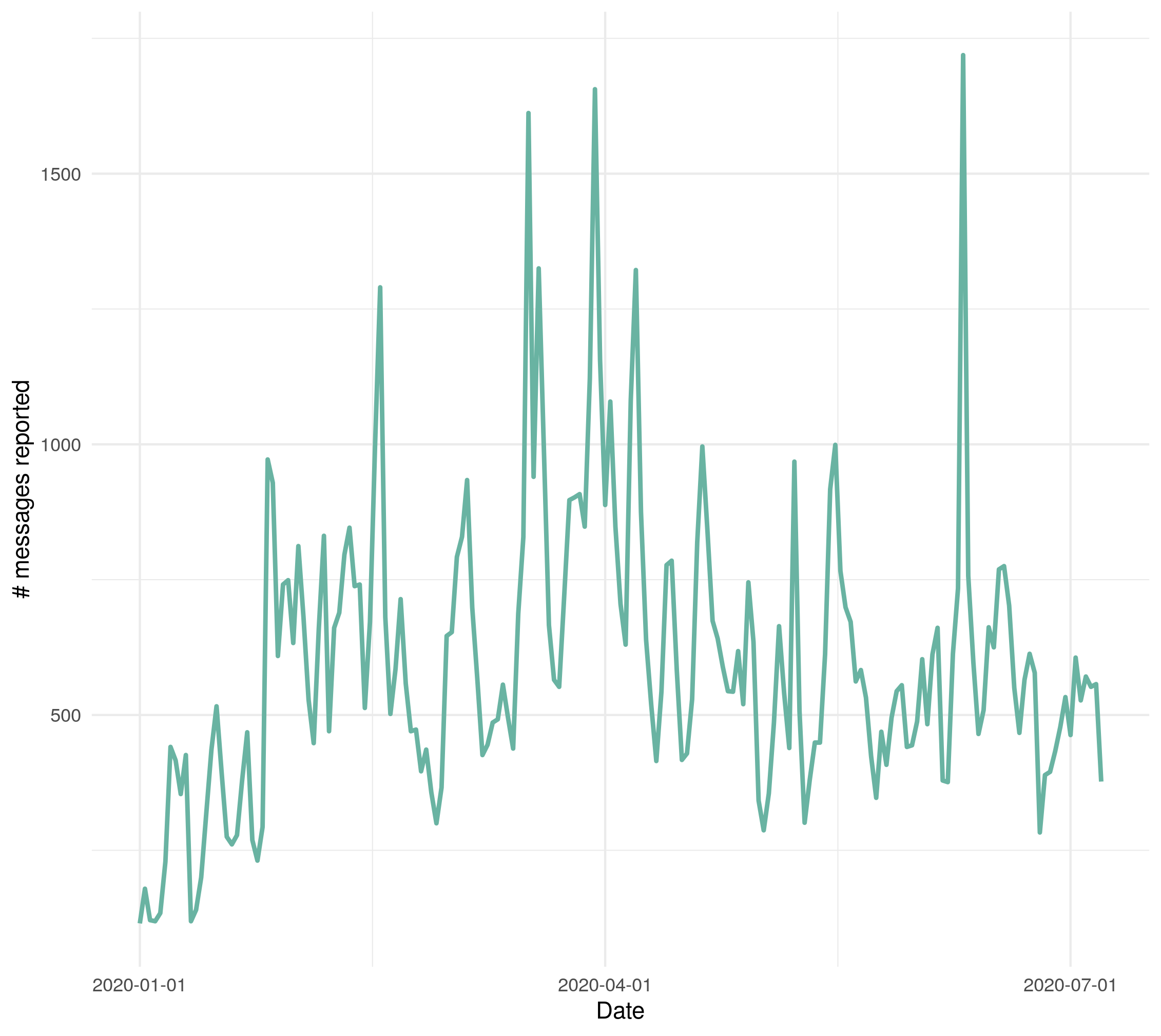
In this work we looked into a dataset of 114 thousands of suspicious messages collected from the most popular closed messaging platform in Taiwan between January and July, 2020. We proposed an hybrid algorithm that could efficiently cluster a large number of text messages according their topics and narratives. That is, we obtained groups of messages that are within a limited content alterations within each other. By employing the algorithm to the dataset, we were able to look at the content alterations and the temporal dynamics of each particular rumor over time. With qualitative case studies of three COVID-19 related rumors, we have found that key authoritative figures were often misquoted in false information. It was an effective measure to increase the popularity of one false information. In addition, fact-check was not effective in stopping misinformation from getting attention. In fact, the popularity of one false information was often more influenced by major societal events and effective content alterations.
翻译:在这项工作中,我们研究了从2020年1月至7月在台湾最流行的封闭信息平台收集的一亿四千条可疑信息数据集,我们建议采用混合算法,根据主题和叙事将大量文字信息有效组合在一起。也就是说,我们获得的一组信息在有限的内容内部作了有限的修改。通过对数据集使用算法,我们得以看一看每个特定谣言的内容变化和时间动态。通过对三个与COVID-19相关的流言进行定性案例研究,我们发现关键权威人物常常在虚假信息中被错误引用。这是提高一个虚假信息的受欢迎程度的有效措施。此外,事实检查对于阻止错误信息引起注意是无效的。事实上,一个错误信息的受欢迎程度往往受到重大社会事件和有效内容改变的影响更大。