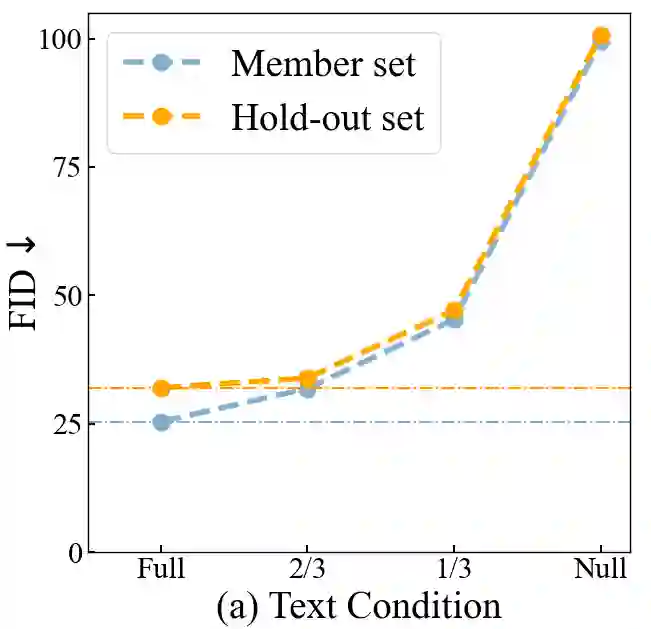
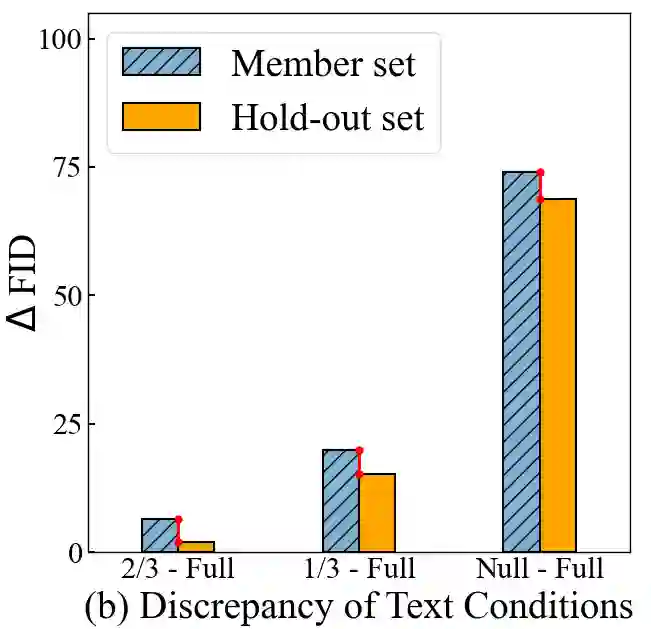
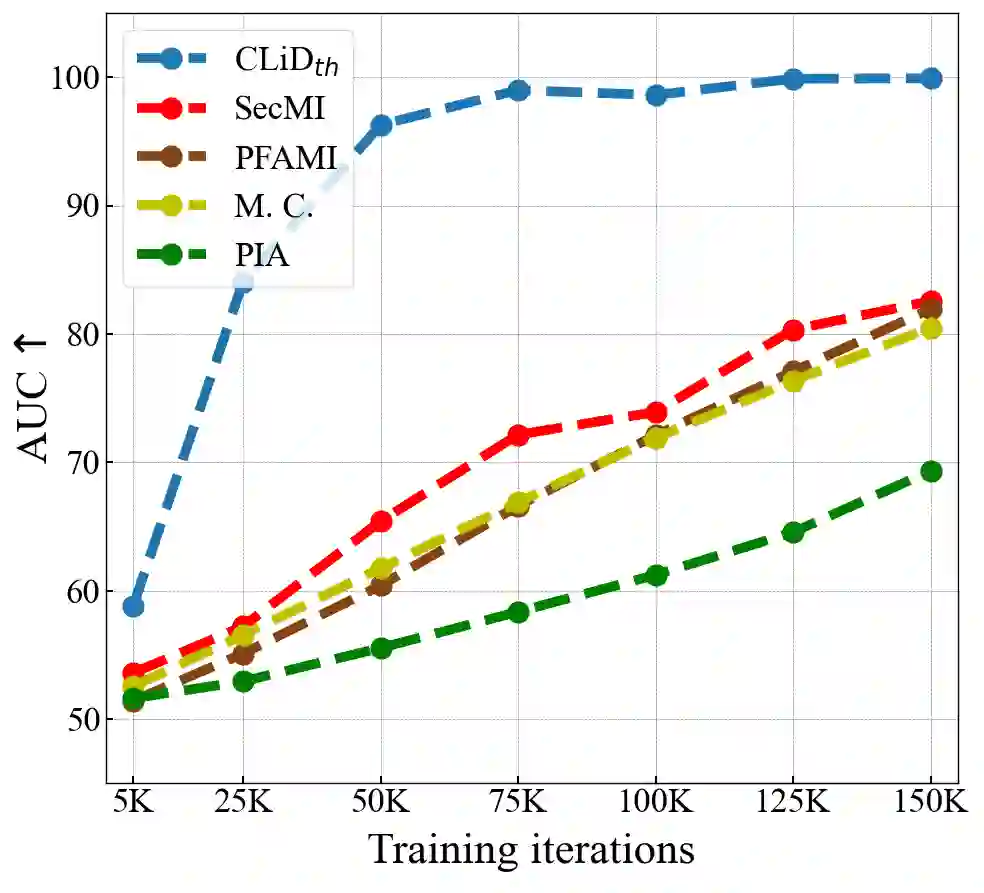
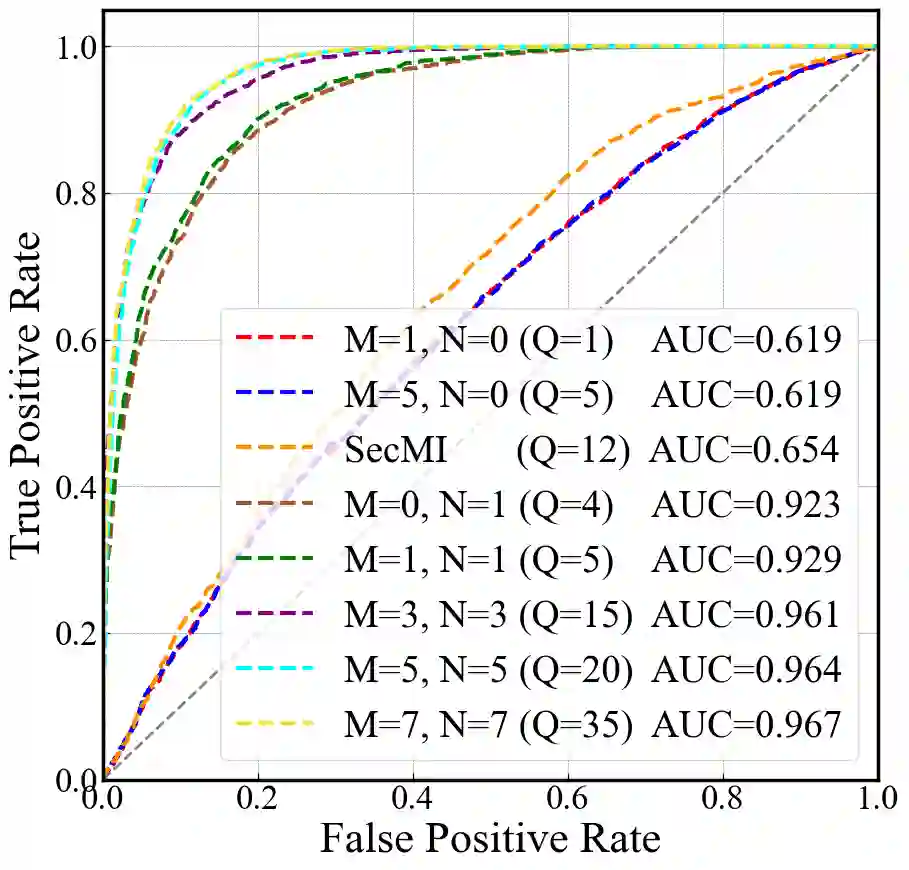
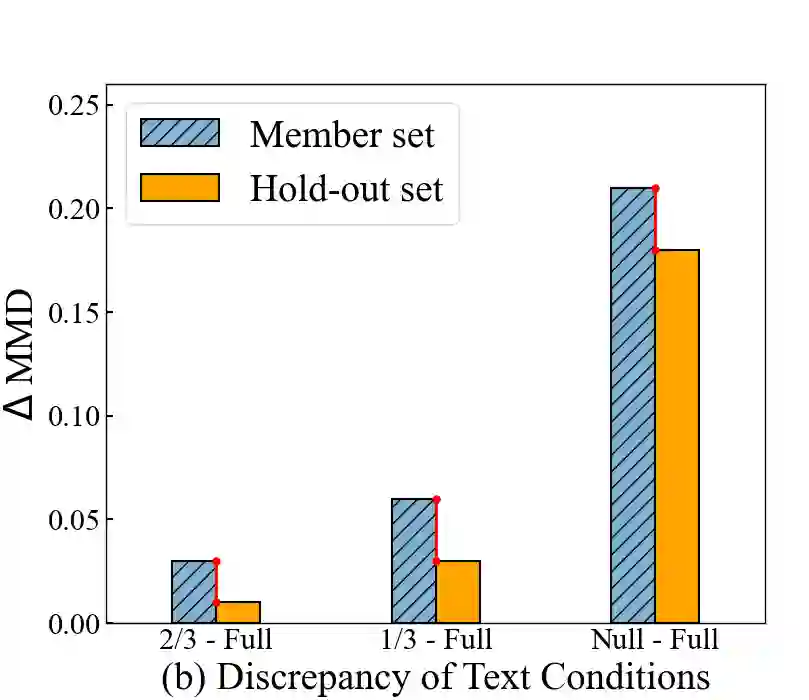
Text-to-image diffusion models have achieved tremendous success in the field of controllable image generation, while also coming along with issues of privacy leakage and data copyrights. Membership inference arises in these contexts as a potential auditing method for detecting unauthorized data usage. While some efforts have been made on diffusion models, they are not applicable to text-to-image diffusion models due to the high computation overhead and enhanced generalization capabilities. In this paper, we first identify a conditional overfitting phenomenon in text-to-image diffusion models, indicating that these models tend to overfit the conditional distribution of images given the text rather than the marginal distribution of images. Based on this observation, we derive an analytical indicator, namely Conditional Likelihood Discrepancy (CLiD), to perform membership inference. This indicator reduces the stochasticity in estimating the memorization of individual samples. Experimental results demonstrate that our method significantly outperforms previous methods across various data distributions and scales. Additionally, our method shows superior resistance to overfitting mitigation strategies such as early stopping and data augmentation.
翻译:暂无翻译