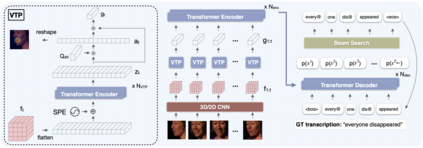
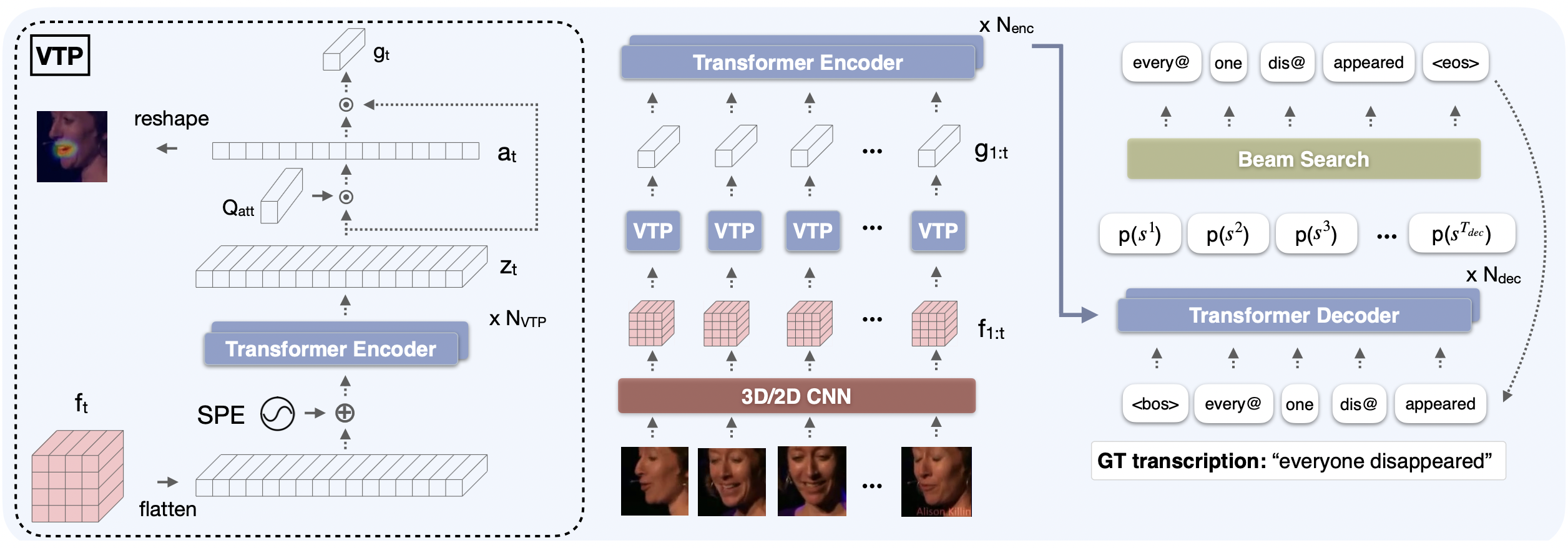
The goal of this paper is to learn strong lip reading models that can recognise speech in silent videos. Most prior works deal with the open-set visual speech recognition problem by adapting existing automatic speech recognition techniques on top of trivially pooled visual features. Instead, in this paper we focus on the unique challenges encountered in lip reading and propose tailored solutions. To that end we make the following contributions: (1) we propose an attention-based pooling mechanism to aggregate visual speech representations; (2) we use sub-word units for lip reading for the first time and show that this allows us to better model the ambiguities of the task; (3) we propose a training pipeline that balances the lip reading performance with other key factors such as data and compute efficiency. Following the above, we obtain state-of-the-art results on the challenging LRS2 and LRS3 benchmarks when training on public datasets, and even surpass models trained on large-scale industrial datasets by using an order of magnitude less data. Our best model achieves 22.6% word error rate on the LRS2 dataset, a performance unprecedented for lip reading models, significantly reducing the performance gap between lip reading and automatic speech recognition.
翻译:本文的目的是学习能够识别静默录像中言论的强烈唇读模型。 大部分先前的工作都通过在微小的集合视觉特征之上调整现有的自动语音识别技术来解决公开的视觉语音识别问题。 相反,在本文件中,我们侧重于在唇读中遇到的独特挑战,并提出有针对性的解决方案。 为此,我们做出以下贡献:(1) 我们提议了一个关注的集合机制,以汇总视觉语音演示;(2) 我们第一次使用小字单位进行唇读,并表明这使我们能够更好地模拟任务的模糊性;(3) 我们建议建立一个培训管道,在口头阅读性能与诸如数据和计算效率等其他关键因素之间取得平衡。 之后,我们在公共数据集培训中获得了具有挑战性的LRS2和LRS3基准方面的最新成果,甚至超过了通过使用数量级较低的数据在大规模工业数据集方面受过培训的模式。 我们的最佳模型在LRS2数据集上实现了22.6%的字误差率,这是对唇读模型来说前所未有的表现,大大缩小了唇读和自动语音识别之间的性差。