
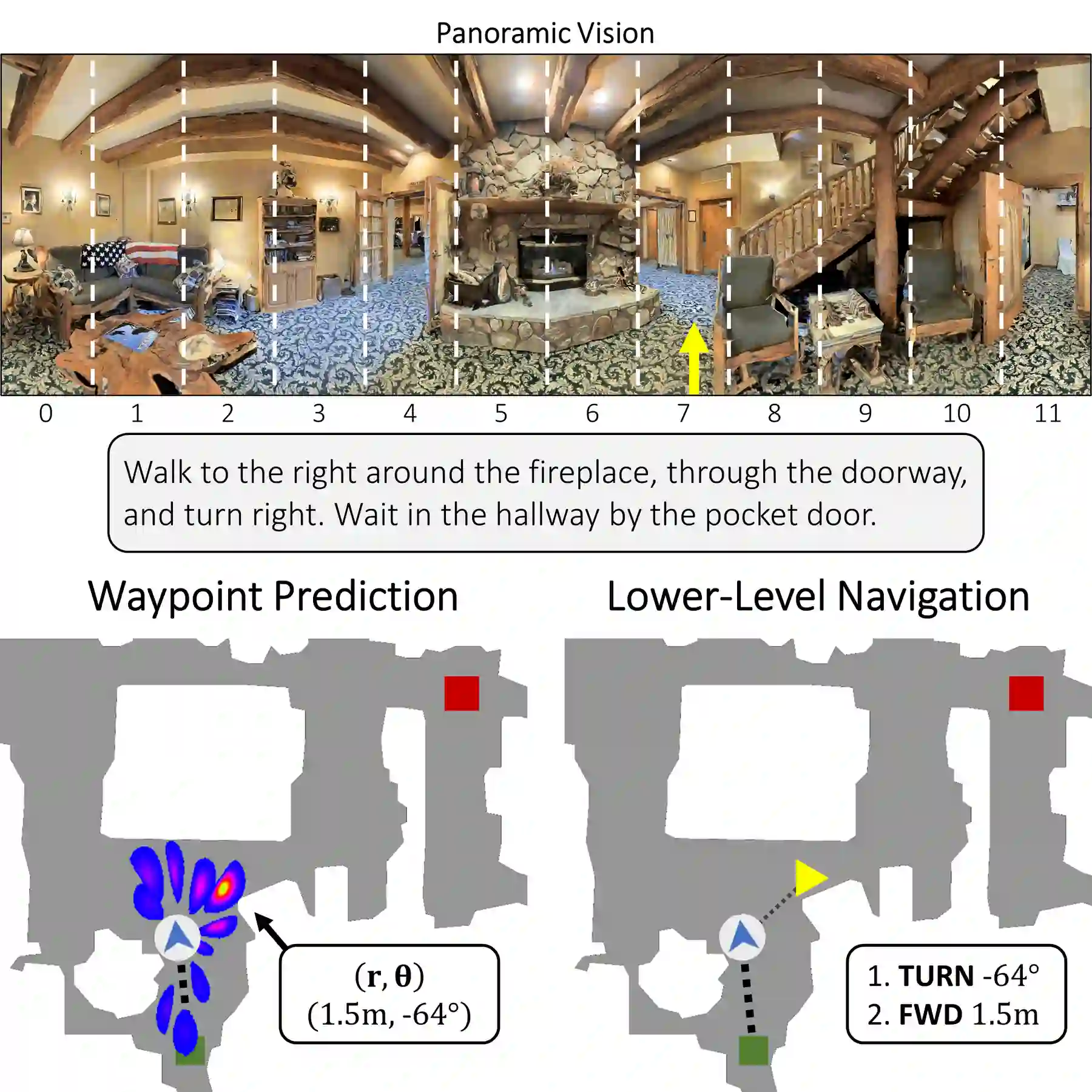
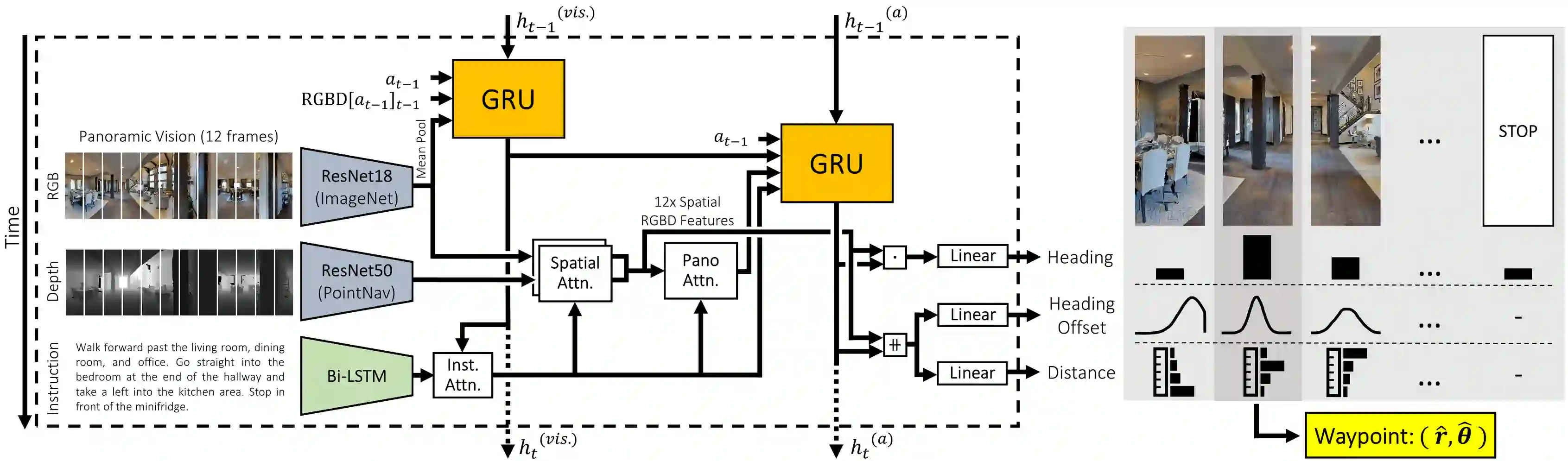
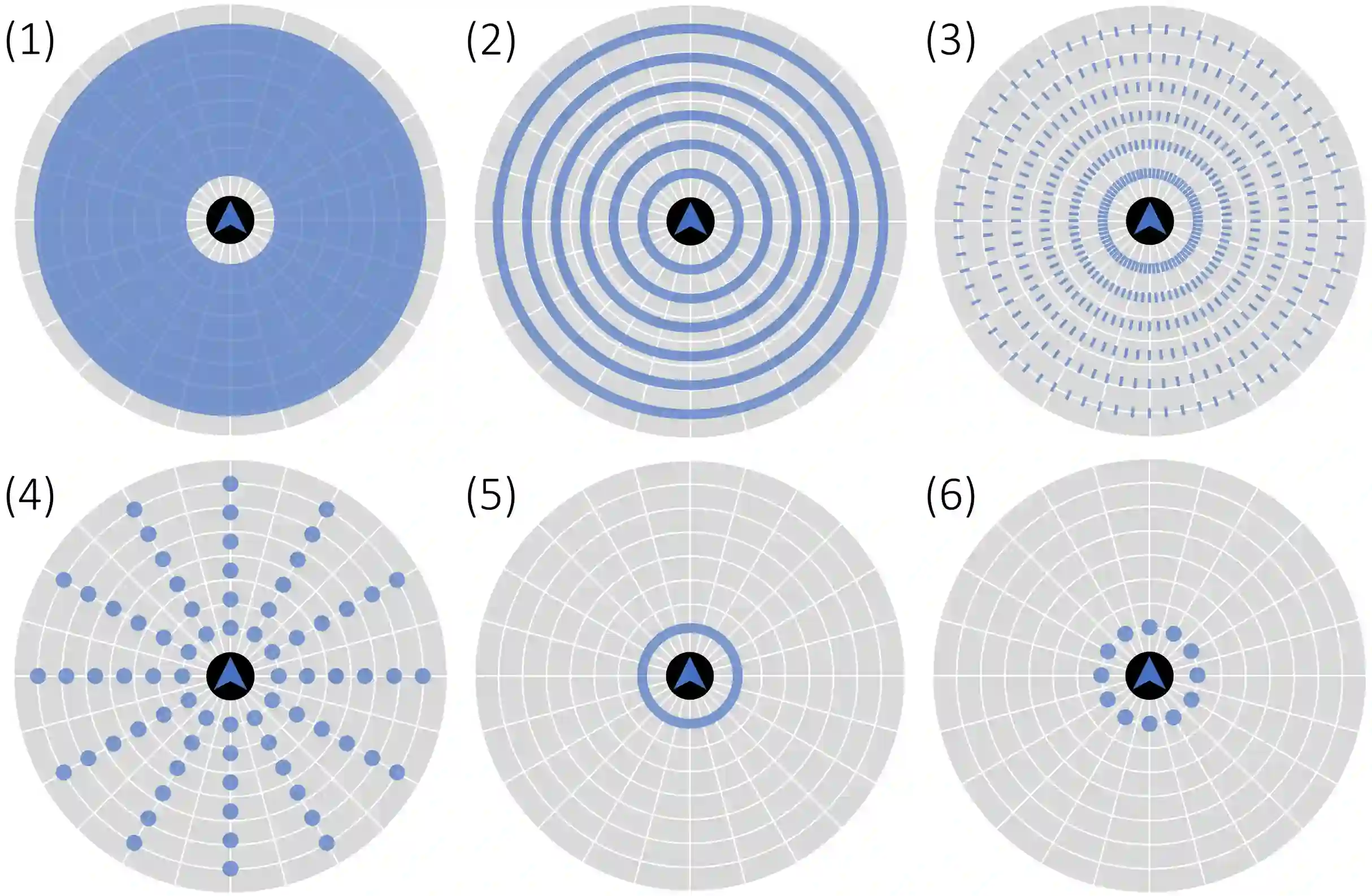
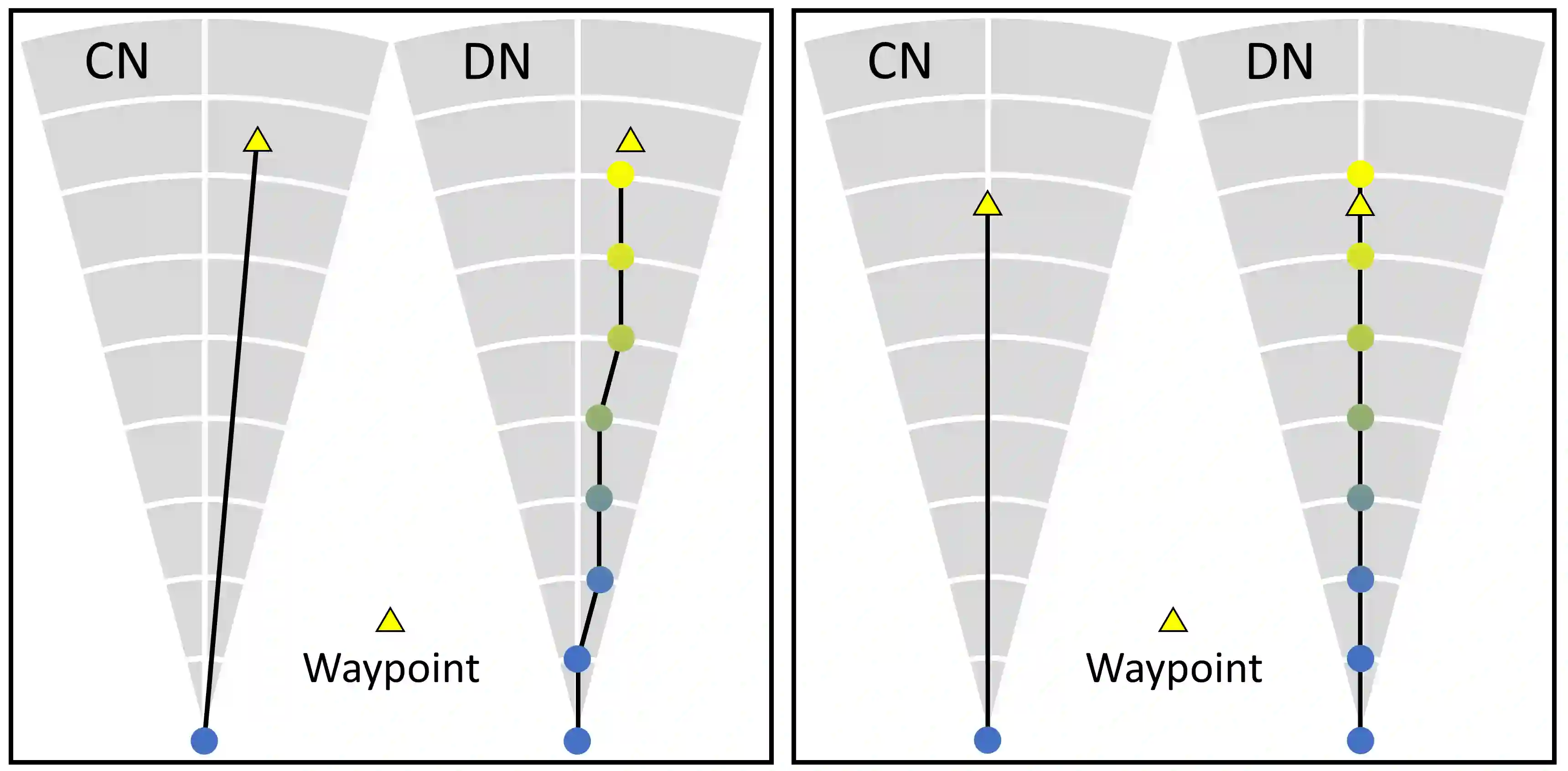
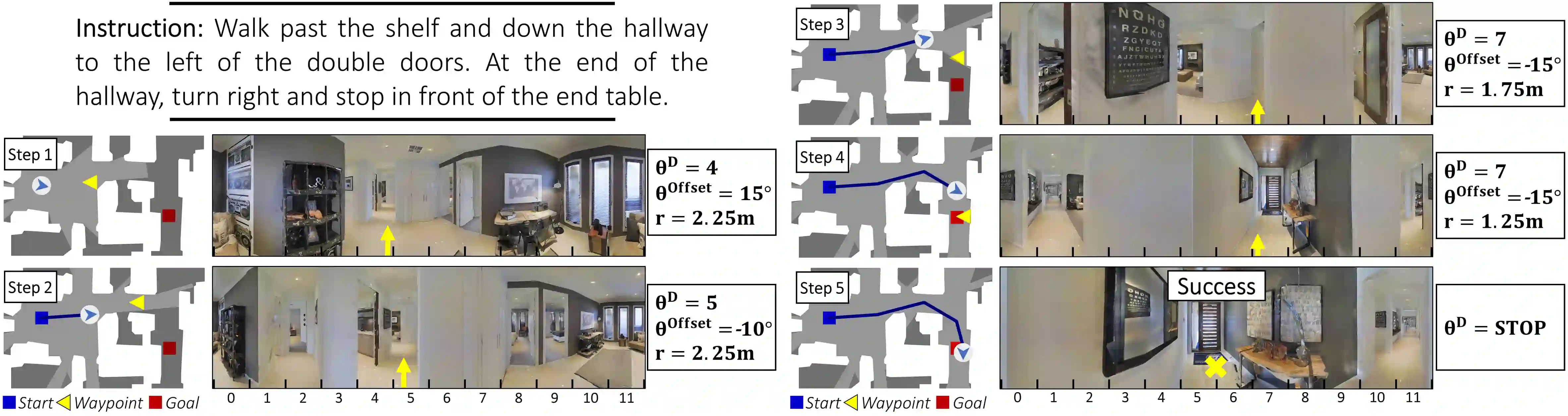
Little inquiry has explicitly addressed the role of action spaces in language-guided visual navigation -- either in terms of its effect on navigation success or the efficiency with which a robotic agent could execute the resulting trajectory. Building on the recently released VLN-CE setting for instruction following in continuous environments, we develop a class of language-conditioned waypoint prediction networks to examine this question. We vary the expressivity of these models to explore a spectrum between low-level actions and continuous waypoint prediction. We measure task performance and estimated execution time on a profiled LoCoBot robot. We find more expressive models result in simpler, faster to execute trajectories, but lower-level actions can achieve better navigation metrics by approximating shortest paths better. Further, our models outperform prior work in VLN-CE and set a new state-of-the-art on the public leaderboard -- increasing success rate by 4% with our best model on this challenging task.
翻译:几乎没有什么调查明确涉及行动空间在语言引导视觉导航中的作用 -- -- 无论是它对于导航成功的影响还是机器人代理人能够执行所产生轨迹的效率。根据最近发布的VLN-CE连续环境中教学设置,我们开发了一组有语言条件的路标预测网络来研究这一问题。我们对这些模型的表达性进行了不同,以探索低层次行动和连续路标预测之间的频谱。我们测量了任务性能和对定位的LoCoBot机器人的估计执行时间。我们发现,更清晰的模型可以更简单、更快地执行轨道,但较低层次的行动可以更好地通过近似最短的路径实现更好的导航测量。此外,我们的模型比VLN-CE的以往工作更成功,并在公共领导板上设置了新的状态,在这项富有挑战性的任务上,我们的最佳模式提高了4%的成功率。
相关内容

Source: Apple - iOS 8

